线性回归(复习)
这篇内容主要是在系统介绍简单线性回归:先假设响应变量 \(Y\) 与解释变量 \(x\) 之间满足 \(Y_i = \alpha + \beta x_i + \varepsilon_i\) 的线性关系,并在误差均值为0、同方差,进一步可假设正态分布的前提下,用最小二乘法估计回归直线的截距和斜率;然后研究这些估计量的统计性质,包括它们的无偏性、方差和误差方差的估计;接着说明如何利用拟合直线对新的 \(x\) 值进行预测,并构造平均响应和单个新观测的置信区间/预测区间;最后再通过残差、残差图、QQ图以及决定系数 \(R^2\) 等方法,检查线性、同方差、正态性等假设是否合理,并评价模型对数据的拟合效果


求解alpha和beta

- 引入汇总量符号Sxx和Sxy
- x 这一列数据自身的波动有多大
- 如果所有 x_i 都差不多,那 S_{XX} 就很小。
- x 和 y 的共同变动程度
- 如果 x 大的时候,y 往往也大,那么 S_{XY}>0
- x 这一列数据自身的波动有多大


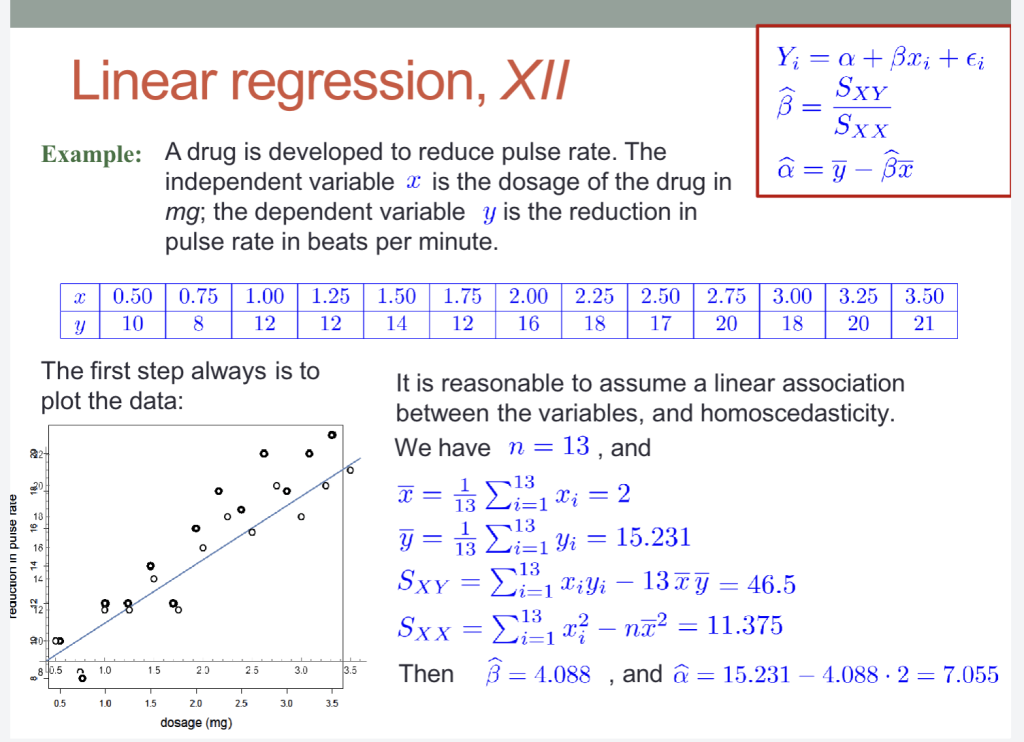
例题:
这是过原点时的公式:

极大似然估计MLE下的最小二乘法
- 在假设误差服从正态分布时,用最小二乘法拟合直线,其实等价于用极大似然估计去找最可能产生这组数据的参数
- 回顾:什么是极大似然估计:在已知结果的情况下,反推什么样的参数,能让当前观测到的数据出现的概率最大?

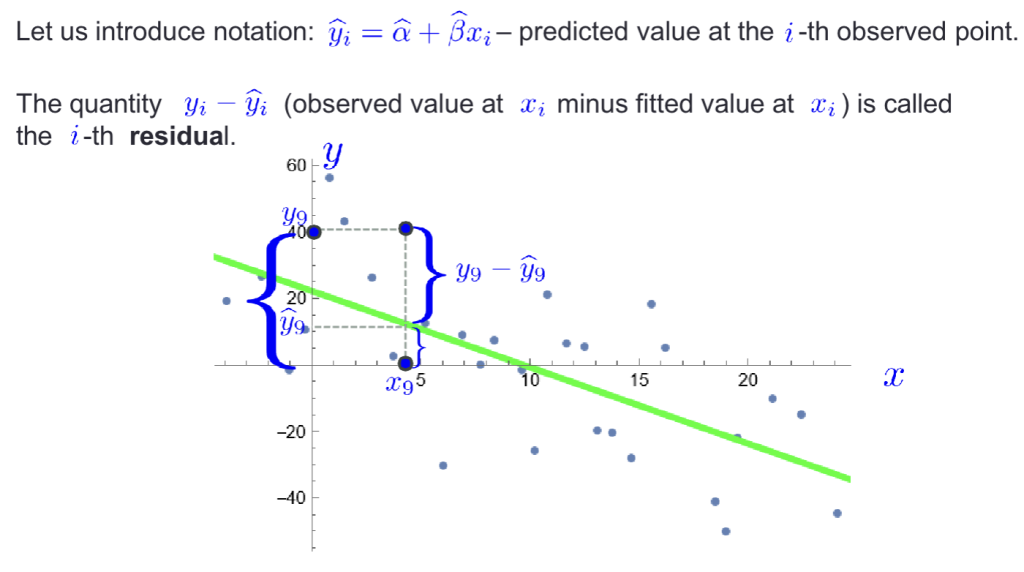
Residuals 残差
估计量的性质
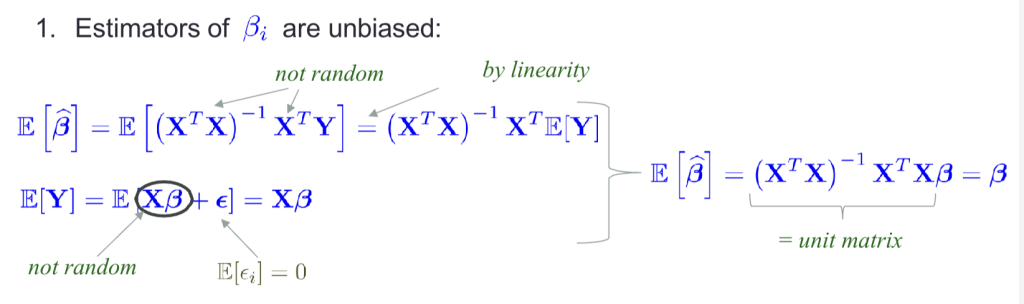
估计量的期望


证明略
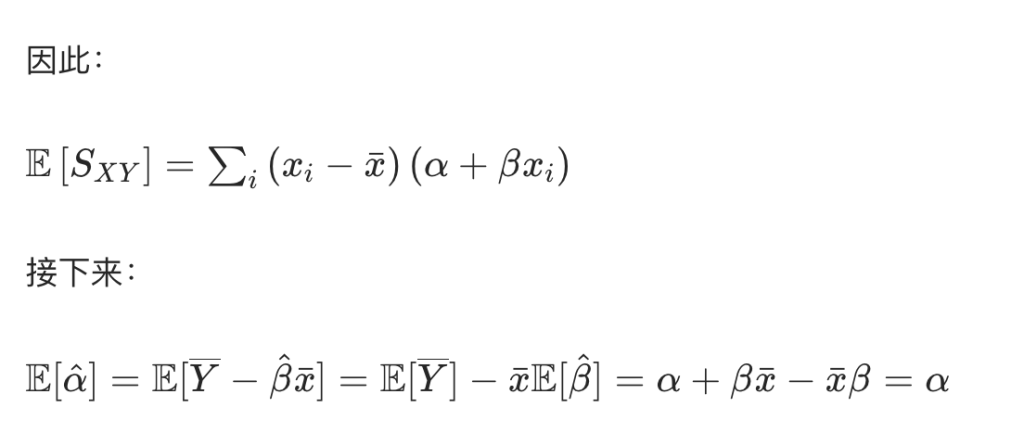
估计量的方差
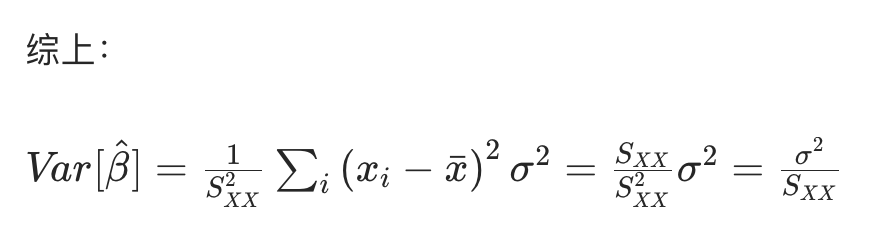


残差平方和 – 用于估计真实的方差


SSE的期望,算这个有什么用处嘛?


Goodness of Fit 拟合优度
- 拟合直线是否能充分代表数据?
- 换句话说,我们能否找到量化区分以下两个示例的指标?y的离散程度有多少能被线性趋势解释?
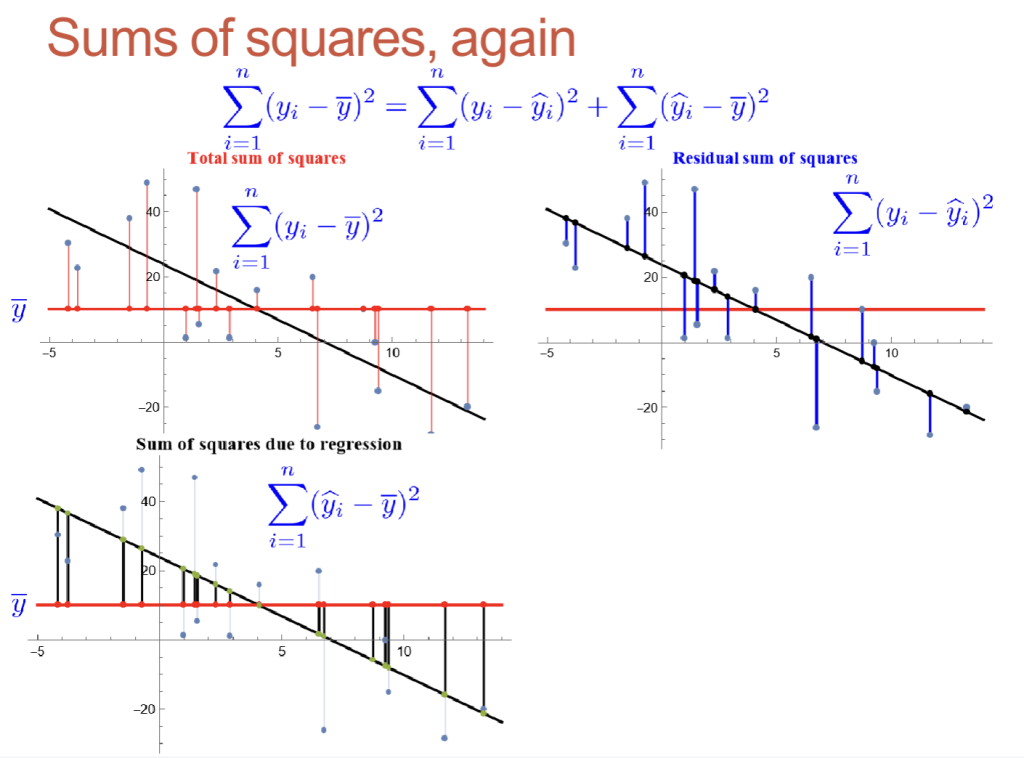
$$ \sum_{i=1}^{n} (y_i – \bar{y})^2 = \sum_{i=1}^{n} (y_i – \hat{y}_i)^2 + \sum_{i=1}^{n} (\hat{y}_i – \bar{y})^2 $$
- 右侧第一项:观测值yi与对应拟合点的偏差平方和。直接衡量直线对原始观测的拟合紧密程度。若该值小,说明直线拟合紧密,可认为仅为 “实验误差”;若该值大,提示线性假设不合适。该量常称为残差平方和,即拟合直线后未被解释的变异剩余部分。
- 右侧第二项:拟合值yi与其均值的偏差平方和(yi的样本均值为yˉ),衡量拟合直线的陡峭程度。常称为回归平方和。
Coefficient of determination 决定系数
Definition: $$ R^2 = \frac{\sum_i (\hat{y}_i – \bar{y})^2}{\sum_i (y_i – \bar{y})^2} $$
该系数取值在 0 到 1 之间,非正式地用作直线拟合优度的度量。
严格来说,R2是响应变量的总变异中,能被线性回归模型解释的比例。

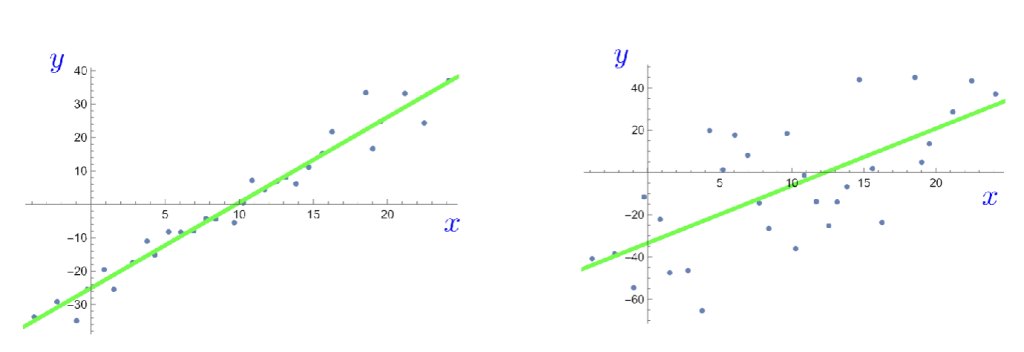
Analysis of residuals 残差分析
- 残差图的点分布没有明显趋势,是随机分布时,说明线性关系基本合理
- 右侧的残差图明显是个U分布
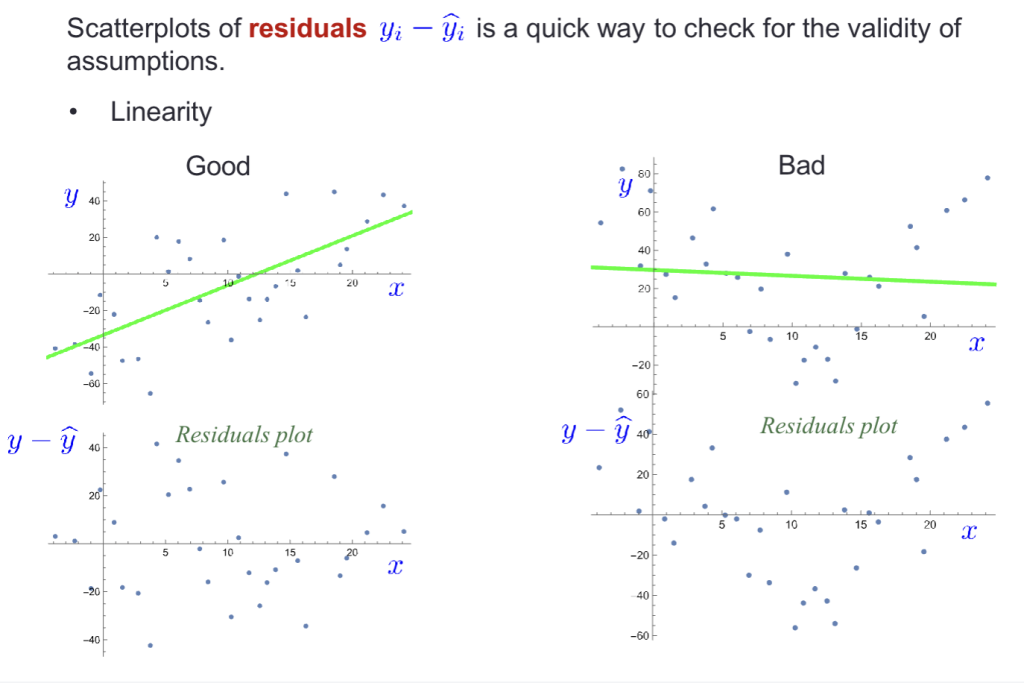
Homoscedasticity同方差性
- 模型在所有 x 区间,预测稳定性都差不
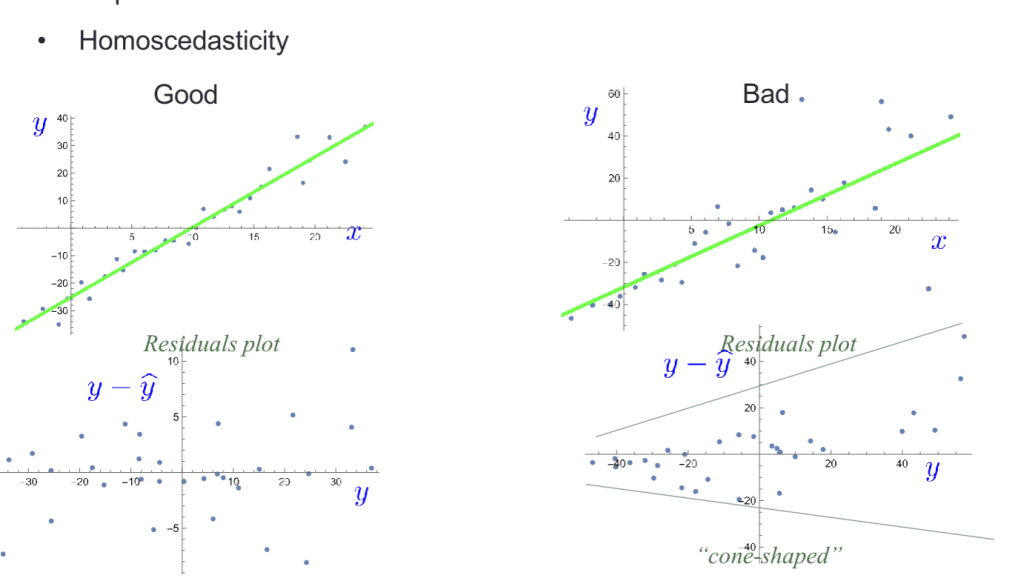
想检查残差是否正态,可以看残差的直方图,或者看 QQ 图
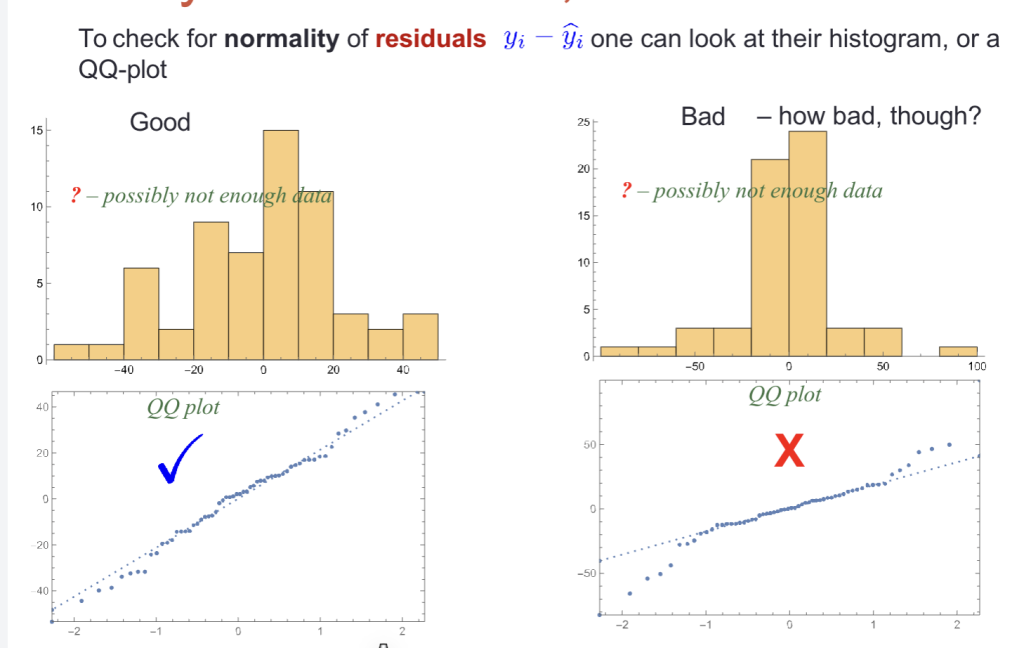
线性性检验
我们通常关心的不是\(\beta\)的具体取值,而是定性判断数据中是否存在线性趋势。 即检验: $$ H_0: \beta = 0 \quad \text{vs} \quad H_1: \beta \neq 0 $$ 注意我们假设数据可被直线良好拟合,问题仅在于直线是“水平”还是“倾斜”。 回顾前述定理:
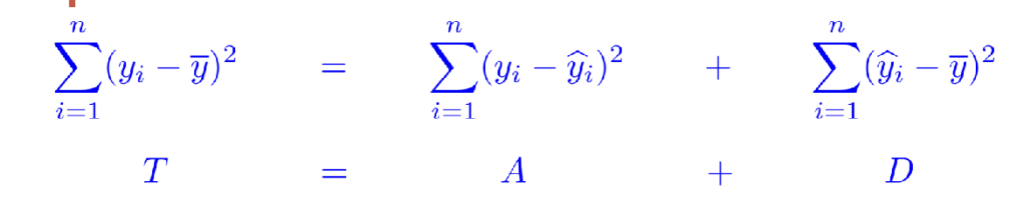

t-检验



注意这个S是残差标准差不是标准差,所以用这个奇怪的公式计算


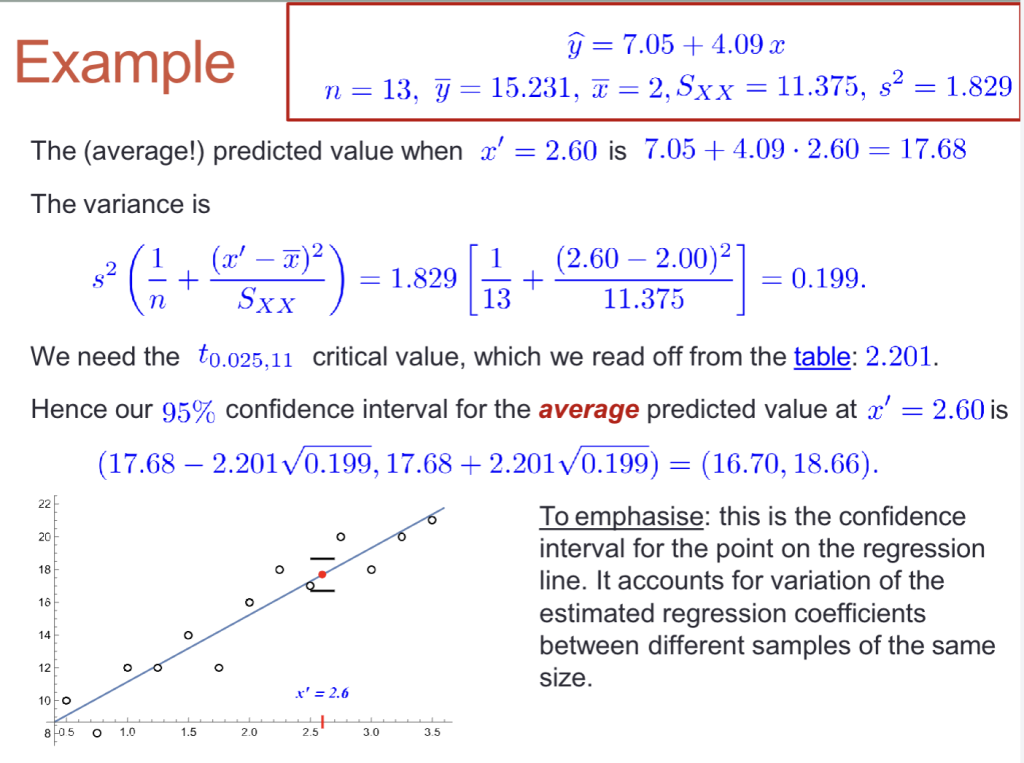
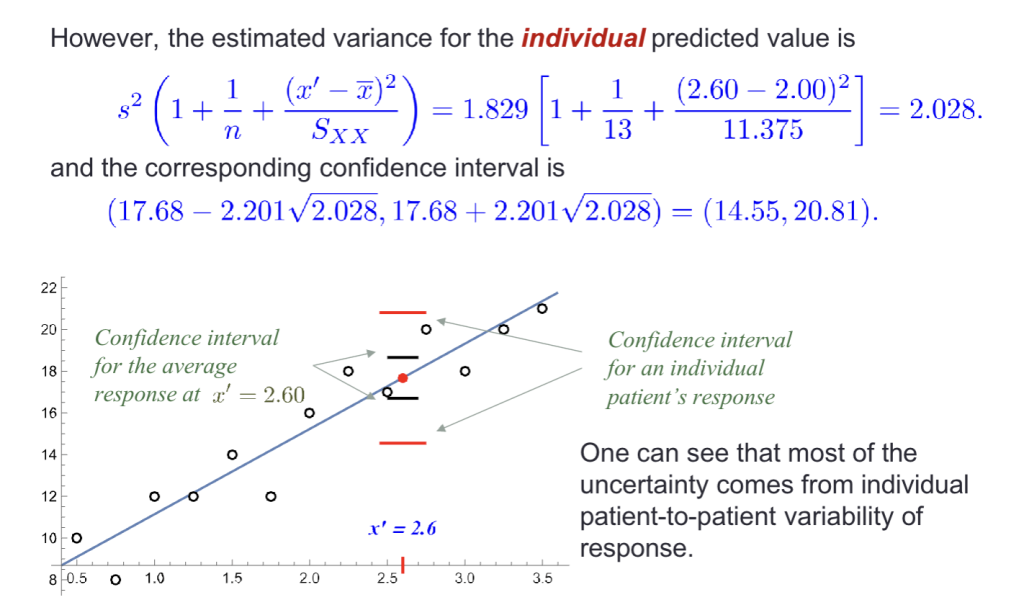
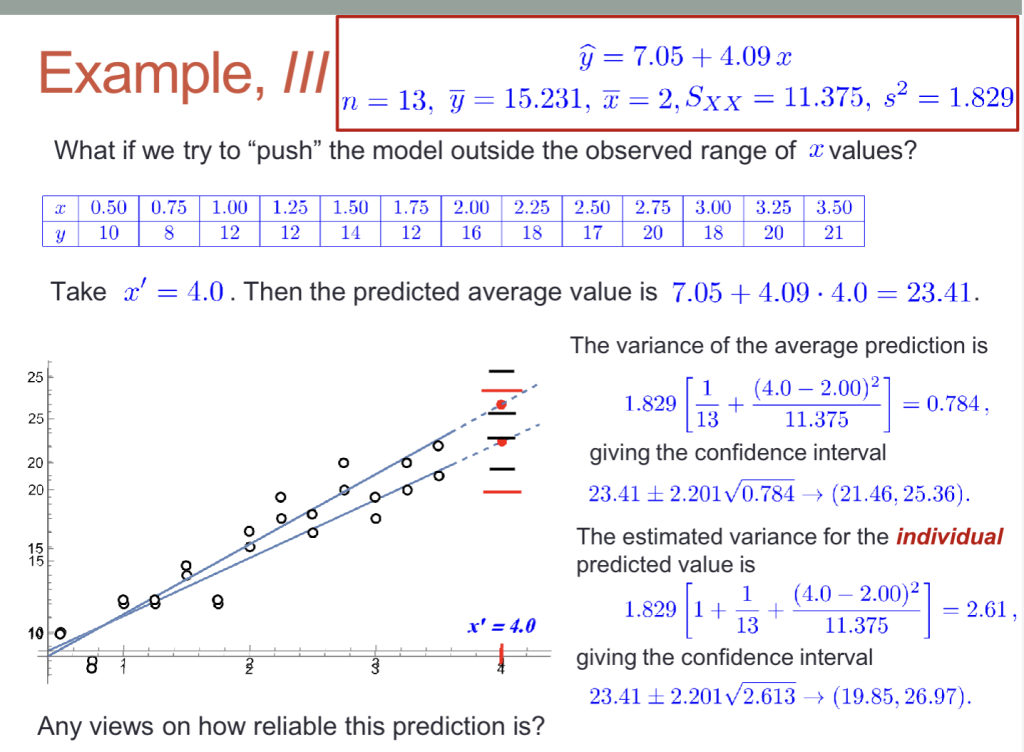
预测Y与置信区间





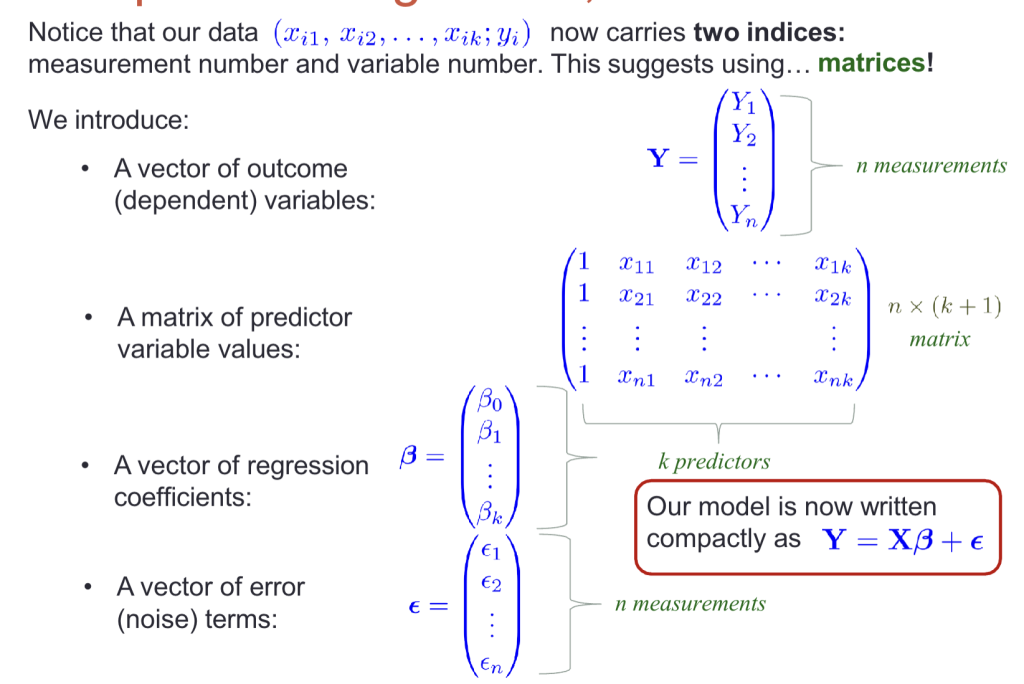
Multiple linear regression 多元线性回归
我们经常会遇到因变量依赖于多个自变量的情况。 例如: – 薪资与受教育程度、年龄、性别 – 癌症发病率与影响因素,如饮食、遗传结构、污染、吸烟等 – 股票价格与市场指数、公司业绩以及整体经济环境 此时模型为: $$Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + \dots + \beta_kX_k + \epsilon$$ 该方法的一个重要应用是对参数的非线性关系建模,例如: $$Y = \beta_0 + \beta_1X + \beta_2X^2 + \epsilon$$
线性回归中的线性是针对参数而言(而非针对变量)。


例题


无偏性
方差协方差矩阵

与一元回归相同,σ2 通常未知,需要估计。

得到估计系数的置信区间


判断回归系数是否为0


Univariate Quantile 一元分位数




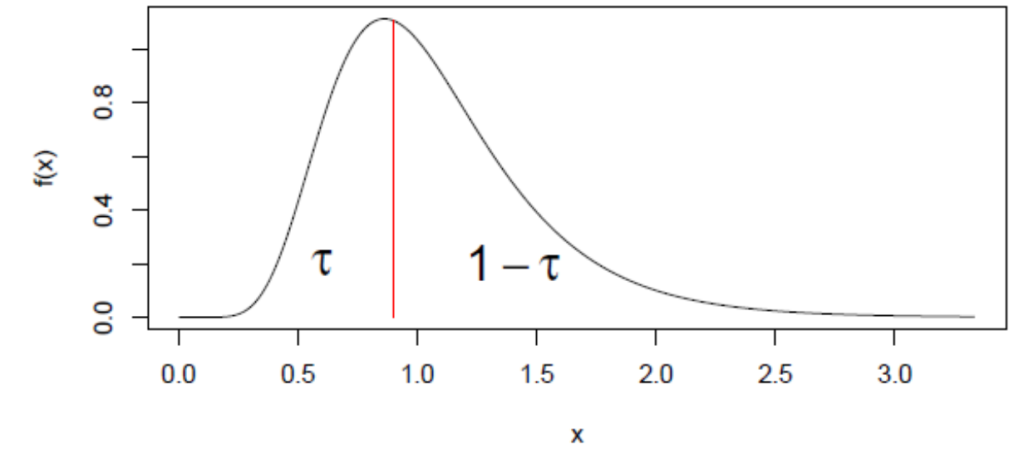
从概率密度的角度看,第 \tau 分位数会把密度曲线下面积分成两部分:
- 左侧面积为:
- \(\tau\)
- 右侧面积为:
- \(1-\tau\)
也就是说,\(\tau\) 分位数以下包含总体中比例为 \(\tau\) 的概率质量,以上包含比例为 \(1-\tau\) 的概率质量

残差
Quantile Regression(分位数回归)
- 普通线性回归,也就是 OLS,回答的是:当 X=x 时,Y 的平均值是多少?但很多现实数据不是对称分布,均价会被抬高,所以这章引入:
- Median Regression 中位数回归:看条件中位数。
- Quantile Regression 分位数回归:看任意分位点,比如 5%、50%、95%














