preprocess_phone_9steps_units.py 数据预处理脚本
模型搭建后得到模型数据脚本
数据的表示

预处理
Step 2) 统一时间轴(关键)
把 timestamp 转成唯一到秒级的时间索引,然后重采样成 1秒一行:
- 解析 timestamp
- 如果是 epoch 数值:自动猜单位(s/ms/us/ns)再
pd.to_datetime - 如果是字符串时间(可能只有分钟级导致重复):同一分钟内按出现顺序补
0..59秒,保证唯一
- 如果是 epoch 数值:自动猜单位(s/ms/us/ns)再
- 设为时间索引并排序、去重
resample("1s").asfreq()- 生成完整连续秒轴
- 缺的秒会新增行(NaN)
- 新增连续时间变量:
t_sec = 距离第一秒的秒数
Step 3) 只对“要参与变换的列”做数值化
不会强制全表转数值,只对你列出的 numeric_need 尝试 to_numeric,避免破坏其它字符串列。
Step 4) 连续化(只填新增秒行,不改原始行)
重点是 fill_only_new_rows():
- 先找哪些行是新增的:
is_new = index不在original_index - 对每个列做连续化得到
s2 - 只把
s2写回新增行,原始行不动
连续化策略:
piecewise:ffill+bfill(分段常数)linear:按时间插值 +ffill+bfill
你分了几类列:
- 开关/档位类:
screen_status / bright_level / wifi_status / mobile_status / gps_activity→ 分段常数 - 连续传感器类:
battery_voltage / cpu_temperature / wifi_intensity / wifi_speed / battery_power→ 线性或分段(由 cfg 控制) - 最后还对 整张表所有列 做一次“只填新增行”的分段填充,让新增秒行尽量不空(仍不改原始行)
Step 5) 可选只保留放电段
若 keep_only_discharging=True 且有 battery_current:
- 保留
battery_current < 0的区间(阈值可调)
Step 6) 单位统一(直接覆盖原列)
这是你“替换原列含义”的核心部分:
- 亮度 bright_level:等级 → nits
- 用 (0..255) 映射到
[screen_min_nits, screen_max_nits] - 支持 gamma(
bright_gamma)
- 用 (0..255) 映射到
- Wi-Fi 速率:Mbps → bit/s
wifi_speed *= 1e6wifi_rx / wifi_tx也按 Mbps 处理*1e6(你注释里也说了这是常见“链路速率”假设)
- 蜂窝 mobile_rx/mobile_tx:累计 bytes → bit/s
- 先
diff()得到每秒增量(bytes/s) - 负 diff 视为重置/回绕,置 0
- 再
*8变为 bit/s
- 先
- Wi-Fi 信号 wifi_intensity:RSSI(dBm) → 质量 q∈[0,1]
q = (rssi - rssi_min) / (rssi_max - rssi_min)并 clip 到 0..1- 若
wifi_status==0则 q 乘 0(Wi-Fi 关掉就认为质量为 0)
Step 7) (可选)构造“可解释的功耗输入特征”
如果 build_power_inputs=True,会新增一组功耗分解特征(单位 W):
P_screen:按 LCD/OLED 模型a0 + a1*亮度nits,并乘screen_onP_cpu:cpu_idle + alpha*cpu_usage + beta*avg_freq_GHzP_net:net_base + net_gamma_bits * wifi_rate_bits * gaingain = 1 + (1 - q_wifi):信号越差(q越小)越耗电的方向net_on由 wifi/mobile 开关决定
P_gps:gps_on * gps_wP_other:常数底噪P_tot_model = 上述之和
这些系数目前是“占位量级”,后续可以用电池侧功率去拟合估参。
Step 8) 构造电池侧“观测功率”用于校验/拟合
- 若有
battery_power:取正并得到P_batt_discharge_W - 否则如果有
battery_voltage和battery_current:用P = -(V * I)并 clip 到 ≥0
(注意你注释写了:如果 current 是 mA 需要 /1000,这里不猜单位)
Step 8.5) 电池相关量统一成正数(直接覆盖)
对 battery_voltage / battery_current / battery_power 做 abs(),把符号统一为“幅值”为正,减少后续建模歧义。

建模
screen_x1_AxL列数据复制给P_scr_mW
根据论文的思路出代码
# preprocess_phone_9steps_units.py
# 作用:按“9步连续时间建模预处理”处理手机日志,并直接“替换原列”的单位/含义:
# 1) bright_level:亮度等级 -> nits(直接覆盖 bright_level)
# 2) wifi_intensity:RSSI(dBm) -> 归一化信号质量 q∈[0,1](直接覆盖 wifi_intensity)
# 3) wifi_speed / wifi_rx / wifi_tx:Mbps -> bit/s(直接覆盖)
# 4) mobile_rx / mobile_tx:累计字节计数 -> 速率(bytes/s) -> bit/s(直接覆盖)
# 5) 其它列保持不变(不额外保留“修改前列”),并输出整张表
#
# 依赖:pip install pandas numpy
from __future__ import annotations
import numpy as np
import pandas as pd
from dataclasses import dataclass
from typing import Optional, List
@dataclass
class Cfg:
# ===== Step 0 / Step 2: 时间与重采样 =====
target_hz: int = 1 # 目标频率:1Hz(1秒一条)
timestamp_col: str = "timestamp" # 你的时间列名
# ===== Step 4: 连续化策略 =====
# 对“新增秒行”填充,不改变原始行的缺失(尽量保证“没变的列不动”)
continuous_method: str = "piecewise" # "piecewise" or "linear"
# ===== bright_level -> nits =====
bright_level_max: float = 255.0
screen_min_nits: float = 2.0
screen_max_nits: float = 600.0
bright_gamma: float = 1.0
# ===== Wi-Fi RSSI(dBm) -> q∈[0,1] =====
# 典型范围:-100(差) ~ -50(好)
rssi_min_dbm: float = -100.0
rssi_max_dbm: float = -50.0
# ===== 放电段筛选(可选) =====
keep_only_collected: bool = False # 如果你有 collected 列并只要采集成功,可改 True
keep_only_discharging: bool = False # 若只建放电模型,可改 True
discharge_current_threshold: float = -1e-6 # battery_current < 0 视为放电
# ===== Step 7: 子模块功耗输入(可选,占位系数,可后续估参)=====
build_power_inputs: bool = True
display_type: str = "LCD" # "LCD" or "OLED"
lcd_a0: float = 0.2
lcd_a1: float = 0.002 # W / nit
oled_a0: float = 0.15
oled_a1: float = 0.0018
cpu_idle_w: float = 0.3
cpu_alpha: float = 0.02 # W / (cpu_usage %)
cpu_beta: float = 0.08 # W / (freq_GHz)
net_base_w: float = 0.15
net_gamma_bits: float = 1e-12 # W / (bit/s)(占位量级)
gps_w: float = 0.08
other_w: float = 0.05
# --------------------------
# Step 2: 时间轴统一的辅助函数
# --------------------------
def infer_epoch_unit(x: pd.Series) -> str:
"""推断 epoch 单位:s / ms / us / ns"""
v = pd.to_numeric(x, errors="coerce").dropna()
if v.empty:
return "s"
m = float(v.iloc[0])
if m > 1e17:
return "ns"
if m > 1e14:
return "us"
if m > 1e11:
return "ms"
return "s"
def build_second_resolved_datetime(ts: pd.Series) -> pd.DatetimeIndex:
"""
把 timestamp 变成“每秒唯一”的 datetime:
- 若是 epoch 数值:按推断单位解析
- 若是字符串分钟级且重复:同一分钟内按出现顺序补 0..59 秒
"""
if pd.api.types.is_numeric_dtype(ts):
unit = infer_epoch_unit(ts)
dt = pd.to_datetime(ts, unit=unit, errors="coerce")
if dt.isna().any():
raise ValueError("timestamp(epoch) 解析失败:存在无法解析值")
return pd.DatetimeIndex(dt)
dt_min = pd.to_datetime(ts, errors="coerce")
if dt_min.isna().any():
raise ValueError("timestamp(字符串) 解析失败:存在无法解析值")
dup_rate = dt_min.duplicated().mean()
if dup_rate > 0.1:
sec_in_group = dt_min.groupby(dt_min).cumcount()
dt = dt_min + pd.to_timedelta(sec_in_group, unit="s")
return pd.DatetimeIndex(dt)
return pd.DatetimeIndex(dt_min)
# --------------------------
# Step 4: 只填充“新增秒行”,不改原始行
# --------------------------
def fill_only_new_rows(
df_1hz: pd.DataFrame,
original_index: pd.DatetimeIndex,
cols: List[str],
method: str = "piecewise",
) -> None:
"""
对 cols 进行连续化,但只把结果写回“新增秒行”(index 不在 original_index):
- piecewise:ffill+bfill
- linear:time 插值 + ffill/bfill
"""
cols = [c for c in cols if c in df_1hz.columns]
if not cols:
return
is_new = ~df_1hz.index.isin(original_index)
for c in cols:
s = df_1hz[c]
if method == "linear":
# 时间插值只对数值有效,非数值会保持 NaN -> 再 ffill/bfill
s2 = pd.to_numeric(s, errors="coerce").interpolate(
method="time").ffill().bfill()
else:
s2 = s.ffill().bfill()
# 只填新增行:避免改变原始行
df_1hz.loc[is_new, c] = s2.loc[is_new]
# --------------------------
# Step 6: 累计计数器 -> 速率
# --------------------------
def counter_to_rate_per_sec(counter: pd.Series) -> pd.Series:
"""
把累计计数器变成“每秒增量”(≈ bytes/s):
- diff<0 视为回绕/重置 -> 置0
"""
x = pd.to_numeric(counter, errors="coerce").fillna(
method="ffill").fillna(0.0)
d = x.diff()
d = d.where(d >= 0, 0.0)
return d # 若为 1Hz,则 diff 就是每秒 bytes
# --------------------------
# 主函数:按 9 步预处理
# --------------------------
def preprocess_9steps(in_csv: str, out_csv: str, cfg: Cfg = Cfg()) -> None:
# =========================
# Step 1) 读入数据(不改列结构)
# =========================
df_raw = pd.read_csv(in_csv)
if cfg.timestamp_col not in df_raw.columns:
raise ValueError(f"缺少时间列:{cfg.timestamp_col}")
# 可选:只保留采集成功行
if cfg.keep_only_collected and "collected" in df_raw.columns:
df_raw = df_raw[df_raw["collected"] == 1].copy()
# =========================
# Step 2) 时间轴统一(构造每秒唯一 datetime,并重采样到 1Hz)
# =========================
dt = build_second_resolved_datetime(df_raw[cfg.timestamp_col])
df_raw = df_raw.copy()
df_raw["__datetime__"] = dt
df_raw = df_raw.sort_values("__datetime__")
df_raw = df_raw.set_index("__datetime__")
df_raw = df_raw[~df_raw.index.duplicated(keep="last")]
original_index = df_raw.index.copy()
# 目标 1Hz 时间轴:补齐缺失秒(若原本就是每秒一条,这步基本不新增)
df_1hz = df_raw.resample("1s").asfreq()
# 相对时间(给连续模型用):t_sec
t0 = df_1hz.index[0]
df_1hz["t_sec"] = (df_1hz.index - t0).total_seconds().astype(float)
# =========================
# Step 3) 需要计算的列先转数值(只对“会参与变换”的列)
# 说明:为了“没变的列不动”,不对所有列强制 to_numeric
# =========================
numeric_need = [
# 屏幕
"bright_level", "screen_status",
# Wi-Fi
"wifi_intensity", "wifi_speed", "wifi_rx", "wifi_tx", "wifi_status",
# 蜂窝
"mobile_rx", "mobile_tx", "mobile_status",
# CPU
"cpu_usage", "cpu_temperature",
"frequency_core0", "frequency_core1", "frequency_core2", "frequency_core3",
"frequency_core4", "frequency_core5", "frequency_core6", "frequency_core7",
# GPS
"gps_activity",
# 电池
"battery_current", "battery_voltage", "battery_power",
]
for c in numeric_need:
if c in df_1hz.columns:
df_1hz[c] = pd.to_numeric(df_1hz[c], errors="coerce")
# =========================
# Step 4) 连续化(只填“新增秒行”,不改变原始行)
# =========================
# 4.1 开关/档位:分段常数
step_like = [
"screen_status", "bright_level",
"wifi_status", "mobile_status",
"gps_activity",
]
fill_only_new_rows(df_1hz, original_index, step_like, method="piecewise")
# 4.2 连续传感器:可选线性插值或分段常数
cont_like = ["battery_voltage", "cpu_temperature",
"wifi_intensity", "wifi_speed", "battery_power"]
fill_only_new_rows(df_1hz, original_index, cont_like,
method=cfg.continuous_method)
# 4.3 其它列:如果你希望“新增秒行也不空”,可以对全部列做 piecewise 填充新增行
# ——不会改变原始行,只填补新插入行
fill_only_new_rows(df_1hz, original_index, list(
df_1hz.columns), method="piecewise")
# =========================
# Step 5) 可选:只保留放电段(battery_current < 0)
# =========================
if cfg.keep_only_discharging and "battery_current" in df_1hz.columns:
df_1hz = df_1hz[df_1hz["battery_current"] <
cfg.discharge_current_threshold].copy()
# =========================
# Step 6) 单位统一:Wi-Fi/蜂窝/亮度/信号质量(直接替换原列,不保留旧列)
# =========================
# 6.1 bright_level:等级 -> nits(覆盖 bright_level)
if "bright_level" in df_1hz.columns:
lvl = df_1hz["bright_level"].fillna(0.0).clip(0, cfg.bright_level_max)
frac = (lvl / cfg.bright_level_max).clip(0, 1)
df_1hz["bright_level"] = cfg.screen_min_nits + (frac ** cfg.bright_gamma) * (
cfg.screen_max_nits - cfg.screen_min_nits
)
# 6.2 Wi-Fi 速率:Mbps -> bit/s(覆盖 wifi_speed;如有 wifi_rx/wifi_tx 也按 Mbps 处理)
if "wifi_speed" in df_1hz.columns:
df_1hz["wifi_speed"] = df_1hz["wifi_speed"].fillna(0.0) * 1e6
for c in ["wifi_rx", "wifi_tx"]:
if c in df_1hz.columns:
# 若你的 wifi_rx/tx 本来就是“链路速率(Mbps)”(常见468/650/866),直接乘 1e6
df_1hz[c] = pd.to_numeric(
df_1hz[c], errors="coerce").fillna(0.0) * 1e6
# 6.3 蜂窝流量:累计 bytes -> bytes/s -> bit/s(覆盖 mobile_rx/mobile_tx)
# (如果你的 mobile_rx/mobile_tx 原本就是累计字节计数,这一步是正确的;
# 若原本已是速率,则请把本段改为 *8 即可。)
if "mobile_rx" in df_1hz.columns:
rx_bps = counter_to_rate_per_sec(df_1hz["mobile_rx"]) # bytes/s
df_1hz["mobile_rx"] = rx_bps * 8.0 # bit/s
if "mobile_tx" in df_1hz.columns:
tx_bps = counter_to_rate_per_sec(df_1hz["mobile_tx"]) # bytes/s
df_1hz["mobile_tx"] = tx_bps * 8.0 # bit/s
# 6.4 Wi-Fi 信号强度:RSSI(dBm) -> 归一化质量 q∈[0,1](覆盖 wifi_intensity)
if "wifi_intensity" in df_1hz.columns:
rssi = df_1hz["wifi_intensity"].astype(float)
# 归一化:q = (rssi - min)/(max-min)
q = (rssi - cfg.rssi_min_dbm) / (cfg.rssi_max_dbm - cfg.rssi_min_dbm)
q = q.clip(0.0, 1.0).fillna(0.0)
# 若 Wi-Fi 关闭,则质量直接置 0(更符合物理解释)
if "wifi_status" in df_1hz.columns:
wifi_on = (df_1hz["wifi_status"].fillna(0.0) > 0).astype(float)
q = q * wifi_on
df_1hz["wifi_intensity"] = q
# =========================
# Step 7) 构造可解释输入(可选):P_screen / P_cpu / P_net / P_gps / P_other / P_tot_model
# =========================
if cfg.build_power_inputs:
# Screen power input (W)
screen_on = (df_1hz["screen_status"].fillna(0.0) > 0).astype(
float) if "screen_status" in df_1hz.columns else 0.0
bright_nits = df_1hz["bright_level"].fillna(
0.0) if "bright_level" in df_1hz.columns else 0.0
if cfg.display_type.upper() == "OLED":
df_1hz["P_screen"] = screen_on * \
(cfg.oled_a0 + cfg.oled_a1 * bright_nits)
else:
df_1hz["P_screen"] = screen_on * \
(cfg.lcd_a0 + cfg.lcd_a1 * bright_nits)
# CPU power input (W)
cpu_usage = df_1hz["cpu_usage"].fillna(
0.0) if "cpu_usage" in df_1hz.columns else 0.0
freq_cols = [
c for c in df_1hz.columns if c.startswith("frequency_core")]
if freq_cols:
cpu_freq_ghz = (df_1hz[freq_cols].mean(
axis=1) / 1000.0).fillna(0.0)
else:
cpu_freq_ghz = 0.0
df_1hz["P_cpu"] = cfg.cpu_idle_w + cfg.cpu_alpha * \
cpu_usage + cfg.cpu_beta * cpu_freq_ghz
# Network power input (W)
# wifi_speed 已经是 bit/s;wifi_intensity 已经是 q∈[0,1]
wifi_rate_bits = df_1hz["wifi_speed"].fillna(
0.0) if "wifi_speed" in df_1hz.columns else 0.0
q_wifi = df_1hz["wifi_intensity"].fillna(
0.0) if "wifi_intensity" in df_1hz.columns else 0.0
net_on = 1.0
if "wifi_status" in df_1hz.columns or "mobile_status" in df_1hz.columns:
wifi_on = (df_1hz.get("wifi_status", 0.0).fillna(0.0) > 0)
mobile_on = (df_1hz.get("mobile_status", 0.0).fillna(0.0) > 0)
net_on = (wifi_on | mobile_on).astype(float)
# 用 (1 - q) 代表“弱信号放大”方向(q越小越耗电)
gain = 1.0 + (1.0 - q_wifi)
df_1hz["P_net"] = net_on * \
(cfg.net_base_w + cfg.net_gamma_bits * wifi_rate_bits * gain)
# GPS
gps_on = (df_1hz.get("gps_activity", 0.0).fillna(
0.0) > 0).astype(float)
df_1hz["P_gps"] = gps_on * cfg.gps_w
# Other baseline
df_1hz["P_other"] = cfg.other_w
# Total model power
df_1hz["P_tot_model"] = df_1hz["P_screen"] + df_1hz["P_cpu"] + \
df_1hz["P_net"] + df_1hz["P_gps"] + df_1hz["P_other"]
# =========================
# Step 8) 电池侧观测功率(用于校验/估参)
# =========================
if "battery_power" in df_1hz.columns:
# battery_power 已经被你转成正数了,所以直接用即可
df_1hz["P_batt_discharge_W"] = df_1hz["battery_power"].clip(lower=0.0)
elif "battery_voltage" in df_1hz.columns and "battery_current" in df_1hz.columns:
# 注意:battery_current 若为 mA 需 /1000;这里不猜单位,默认 A(必要时你自己改)
df_1hz["P_batt_discharge_W"] = (-(df_1hz["battery_voltage"]
* df_1hz["battery_current"])).clip(lower=0.0)
# =========================
# Step 8.5) 把电池相关量统一成“正数”(直接替换原列,不保留旧列)
# 说明:
# - voltage 本来一般就是正的,这里用 abs() 兜底
# - current / power:无论原来正负,统一取“幅值”为正
# =========================
for c in ["battery_voltage", "battery_current", "battery_power"]:
if c in df_1hz.columns:
df_1hz[c] = pd.to_numeric(df_1hz[c], errors="coerce").abs()
# =========================
# Step 9) 输出整表:保留原列不变(除已替换列)+ 新增列(如 t_sec、P_*、P_batt_discharge_W)
# =========================
# 把索引时间写回 timestamp 列(带秒),保证唯一时间戳
# ——这是“为了连续时间建模必需”的修改
df_1hz[cfg.timestamp_col] = df_1hz.index.strftime("%Y-%m-%d %H:%M:%S")
# 输出 CSV
df_1hz.reset_index(drop=True).to_csv(
out_csv, index=False, encoding="utf-8-sig")
# --------------------------
# 使用示例(只改路径即可)
# --------------------------
if __name__ == "__main__":
IN_CSV = r"D:\LaterDeletee\70a09b5174d07fff_20230221_dynamic_processed.csv"
OUT_CSV = r"D:\LaterDeletee\70a09b5174d07fff_20230221_dynamic_processed_preprocessed_9steps.csv"
cfg = Cfg(
target_hz=1,
continuous_method="piecewise",
# 亮度映射(按机型/文献改)
screen_max_nits=600.0,
bright_gamma=1.0,
# RSSI 归一化范围
rssi_min_dbm=-100.0,
rssi_max_dbm=-50.0,
# 可选
keep_only_collected=False,
keep_only_discharging=False,
build_power_inputs=True,
display_type="LCD", # 若 OLED 改为 "OLED"
)
preprocess_9steps(IN_CSV, OUT_CSV, cfg)
print("Saved:", OUT_CSV)



经过草图验证后,根据得到的数据集在graphpad中作图
关键字:
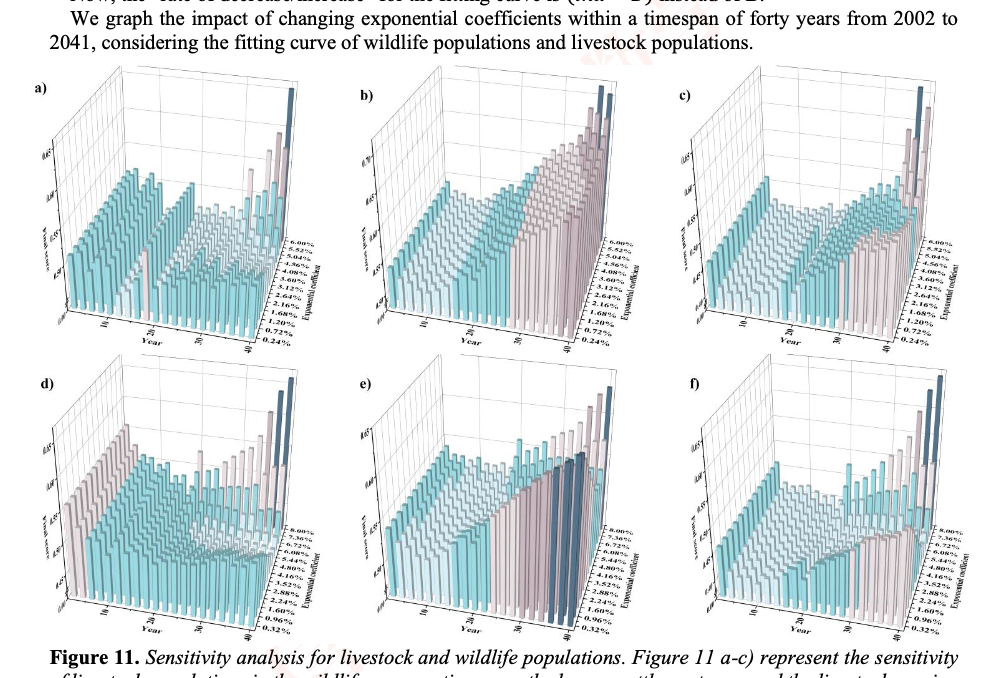
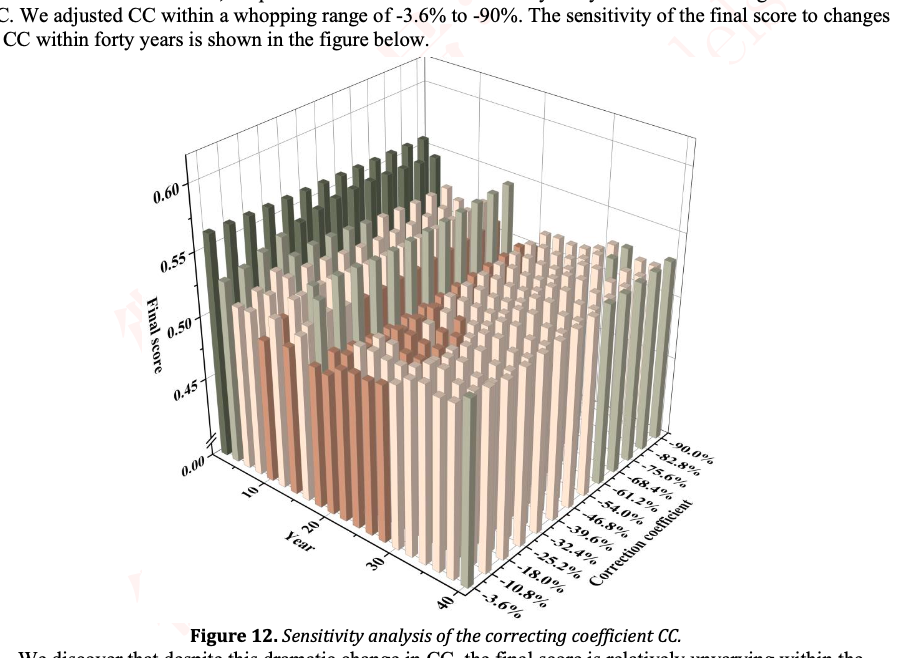
现在解题第一问,根据可视化读取你所需要的列数据,这些数据是按照建模思路处理过的,直接生成python代码做的图,并同时生成一份你所有图中用到的数据的集合。最后你再用这些图额外生成一些你认为有用的图,并详细的说明这些图怎么能帮助建模思路回答第一问的题目要求
第一问:
通过第一二个数据集算出Qeff(N)和Q0的比例也就是等于(1-kn的alpha次方),然后代入第二个公式就能算出没有SOH的两个数据集的SOH了,你的SOH逻辑不要直接读取SOC,通过我上面说的逻辑计算。其他逻辑不变。重新修改代码# Q1_make_figures.py
首先AGING_processed_with_load_quantified.csv的SOH就是SOH,另外两张表的SOH计算方式不变。AGING_processed_with_load_quantified.csv的N没有的话需要你去拟合,额外加一张只根据AGING_processed_with_load_quantified.csv的N和R0,N和SOH的关系图。给我修改后的代码
在计算AGING_processed_with_load_quantified.csv中的Rt,等于R0_mean 除SOH计算得到,其他逻辑不变,给我改后的代码
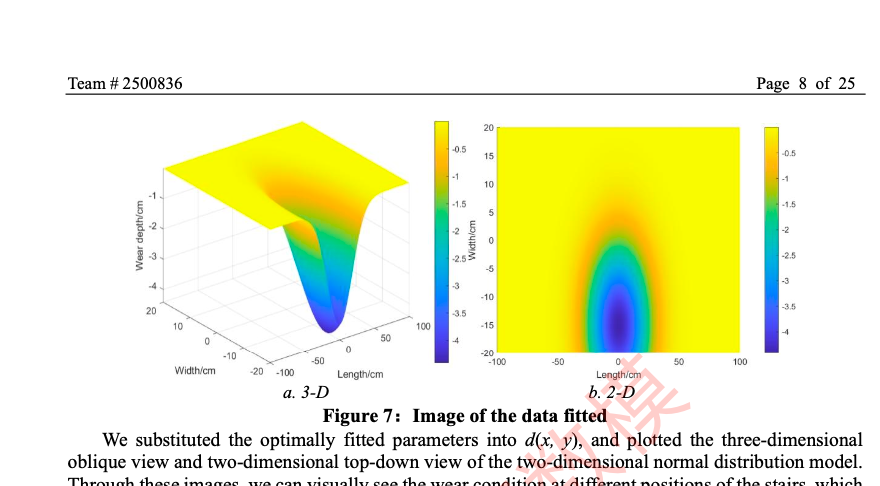
第三问:
现在解题第三问,根据建模思路和题目信息读取你所需要的列数据,这些数据是按照建模思路处理过的,直接生成python代码做的图,并同时生成一份你所有图中用到的数据的集合,这些数据要方便在graphpad中复刻的表示,并详细的说明这些图怎么能帮助建模思路回答第3问的题目要求
出图提示
先用GPT生成提示词:附加文件:当题的做题思路,所有预处理后的数据
我是一名经验丰富的科研绘图设计师,请仔细阅读我们的数学建模大赛的解题思路,充分理解内容,生成可用于数学建模大赛拿第一名的英文提示词。我们的数据有这些。请给出我们需要什么图表,需要包含一些最后图片的高级图表。风格:Biorender风格