条件概率

贝叶斯定理
贝叶斯定理非常实用,可实现条件的转换,例如:
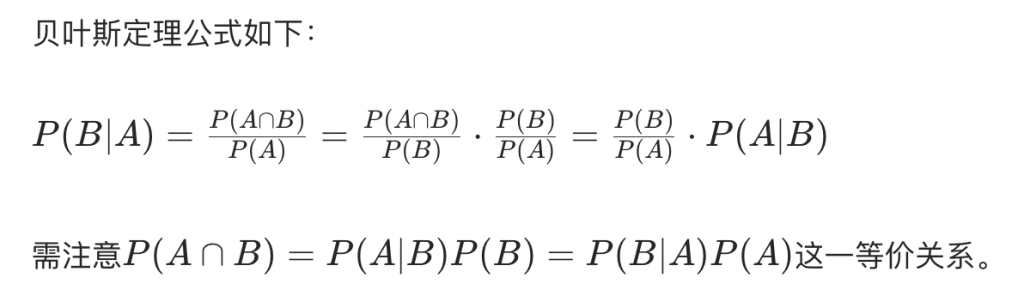
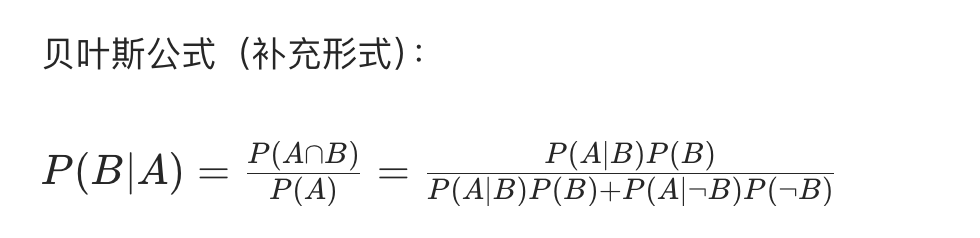
概率核心公式

我们对这些公式的直接使用需求不多,但需关注其与混淆矩阵的关联。
混淆矩阵 Confusion Matrices



均值、平均值、期望值、中位数Median、众数Mode、方差



协方差和相关系数 Covariance and Correlation

协方差和相关系数用于描述变量间的关联强度:
- 正相关:一个变量增大时,另一个变量也倾向于增大;
- 负相关:一个变量增大时,另一个变量倾向于减小;
- 零相关:变量间无明显关联。

Polynomial Regression 多项式回归
- 多项式回归
- 数据的最佳拟合直线(或多项式)
- 代价与损失:均方误差(MSE)和总平方误差(TSE)
- 标准方法以及岭回归和 LASSO 正则化
- 用于分类的逻辑回归
- 上述方法的原理、数学基础及代码实现
1. 基本目标
构建模型\(\hat{y}(x)\),通过特征x预测标签y,核心是找到 “最优” 多项式(或直线),使预测值与真实值的误差最小。
2. 线性回归(一阶多项式)
(1)模型形式


(2)损失与成本定义
损失(单数据点误差):平方误差损失,即,目的是消除误差符号影响。成本(整体误差):均方误差(MSE),为所有损失的平均值,公式为:
其中为向量 2 – 范数(元素平方和的平方根)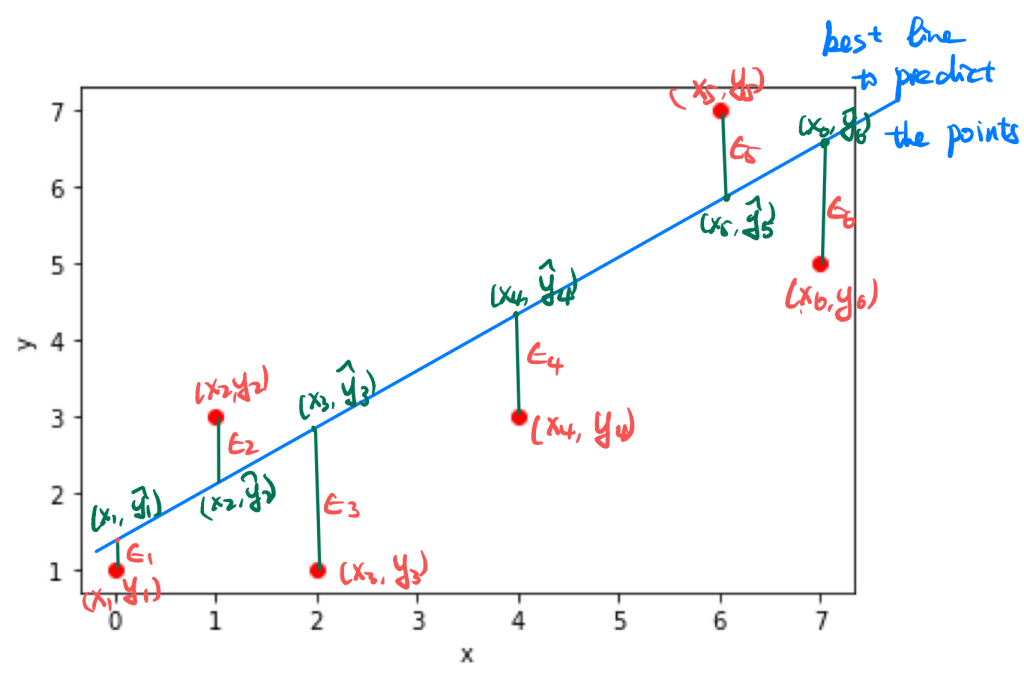
补充术语:总平方误差(TSE)为未取平均的损失和;部分文献中 MSE 被称为 “经验风险”,IPDS 中 “损失” 特指 TSE(无平均),但核心计算逻辑一致。
(3)最优参数求解:正规方程
先分清要找谁的最小值,我们要找使损失函数最小的\(\theta\),因此当\(\theta\)满足以下条件时:

3. 高阶多项式回归

(2)示例:二次与五次多项式
- 二次多项式:设计矩阵包含 1、x、\(x^2\)列,拟合曲线比直线更贴合部分数据波动。
- 五次多项式:6 个数据点可被五次多项式完全拟合(自由度与数据点数量匹配),但需通过密集x网格(如步长 0.1)才能呈现平滑曲线。
(3)关键问题:过拟合
- 现象:五次多项式完美贴合训练数据,但对新增测试数据(\((1,2)、(3,3)、(6,5)\))预测误差大。
- 本质:模型过度学习训练数据中的噪声,丧失泛化能力。
- 解决方案:引入验证集,在模型训练中监控泛化性能,避免过度复杂。
正则化 Regularization:解决过拟合over fitting与病态问题
1. 正则化的核心目的
处理 “病态问题”(如数据含异常值、特征冗余),避免模型出现 “虚假解”,平衡拟合效果与泛化能力。
2. 正则化成本函数
在 TSE 基础上添加参数惩罚项,形式为:
\(\mathcal {E}_{\alpha }(\theta )=\| y-X\theta \| _{2}^{2}+\alpha \| \theta \| _{p}^{p}\)
- \(\alpha \geq0\):正则化参数,\(\alpha=0\)退化为普通 OLS,\(\alpha<0\)无意义(惩罚项为负,无法约束参数)。
- \(\| \theta \|_p^p\):参数的p范数惩罚,核心分三类:
3. 三种正则化方法


4. 正则化参数\(\alpha\)的权衡
- \(\alpha\)过小:惩罚不足,接近 OLS,仍可能过拟合或受病态问题影响。
- \(\alpha\)过大:惩罚过重,参数过度压缩,模型过于简单,可能欠拟合(偏离真实数据规律)。
- 选择方式:无通用规则,需通过交叉验证( trial and error )确定最优\(\alpha\)。
五、多元线性回归
1. 模型场景
当预测目标受多个独立变量(特征)影响时(如房价受面积、地段、房龄影响),而非单一特征的高阶多项式。
2. 模型形式
\(\hat{y}(x)=\theta_0+\theta_1 x_1+\theta_2 x_2+\cdots+\theta_p x_p\)
- 特征矩阵X:每行对应一个数据点,列包括 1(截距项)和p个特征,形式为:\(X=\left( \begin{array} {llll}{1}&{x_{1,1}}&{x_{2,1}}&{\cdots }\\ {1}&{x_{1,2}}&{x_{2,2}}&{\cdots }\\ {\vdots }&{\vdots }&{\vdots }&{\ddots }\end{array} \right)\)
- 求解逻辑:仍通过最小化 MSE,求解正规方程\(X^T X \theta=X^T y\),与单特征线性回归原理一致。
3. 关键问题:\(p>n\)(特征数 > 数据点数量)
(1)核心矛盾
- 定理:\(X^T X\)可逆的充要条件是X具有满列秩(列向量线性无关)。
- 矛盾推导:若\(p>n\),X的列秩最大为n(小于p),故\(X^T X\)不可逆,无法通过\(\theta=(X^T X)^{-1} X^T y\)求解唯一参数。
- 补充:行秩与列秩相等(通过 SVD 分解可证,非零奇异值数量一致)。
(2)解决方案
- 无法通过传统正规方程求解,但可通过正则化(岭回归、LASSO)或数值方法最小化成本,scikit-learn 等库已封装相关实现,无需手动推导。
六、逻辑回归:回归用于分类
1. 核心定位
虽名为 “回归”,实则用于二分类任务,通过线性回归构建决策边界,结合 sigmoid 函数实现类别划分。
2. sigmoid 函数(逻辑函数)
(1)基础形式
\(\sigma(x | a)=\frac{1}{1+exp(-a x)} \quad (a>0)\)
- 特性:输出值映射到\((0,1)\)区间,可表示 “属于某类的概率”。
- 参数影响:a控制曲线陡峭程度(a越大,曲线越陡,分类边界越清晰);可通过\(x_0\)平移曲线,形式为\(\sigma(x | a,x_0)=\frac{1}{1+exp(-a(x-x_0))}\)。
(2)多维扩展(二特征示例)
\(\sigma(x_1,x_2 | a,b,c)=\frac{1}{1+exp(-(a x_1 + b x_2 + c))}\)
- 决策边界:当\(\sigma=0.5\)时,\(a x_1 + b x_2 + c=0\)(直线),一侧\(\sigma \to 1\)(类 1),另一侧\(\sigma \to 0\)(类 2)。
- 3D 可视化:以\(x_1\)(花萼宽度)、\(x_2\)(花瓣长度)为特征,sigmoid 值为 z 轴,呈现 “斜坡状” 分类面。
3. 数学本质:对数几率(log-odds)
- 几率:\(\frac{p}{1-p}\)(p为属于类 1 的概率)。
- 对数几率:\(ln\left(\frac{p}{1-p}\right)=\theta^T x\)(\(\theta=(\theta_0,\theta_1,…,\theta_p)^T\),\(x=(1,x_1,x_2,…,x_p)^T\)),即对数几率与特征呈线性关系,连接线性回归与分类任务。
Principal Component Analysis
高维数据其实大多靠近一个低维 subspace,我们要找到这个低维 subspace,既压缩维度,又尽量保留原始数据的关键信息

通俗说:找几个 “主成分”(其实就是前面讲的特征向量),让数据投影到这些主成分上后,“方差最大”—— 方差越大,说明保留的原始信息越多;专业说:找到一个矩阵 B,让数据 X 乘 B 再乘 B 的转置(Z = X B Bᵀ),Z 是 X 的近似(重构),重构误差(原始数据 X 和重构数据 Z 的差距)最小。
协方差矩阵(描述数据的 “变化关系”)

Explained Variance 解释方差

例子:
数据 X:假设我们有一组数据,比如 “10 个学生的 3 项成绩(语文、数学、英语)”,那么:
- 每一行是 1 个学生(“一个观测值”),
- 每一列是 1 个科目(“一个特征”),
- 所以 语文成绩列数学成绩列英语成绩列(对应图里的 X=[x0,x1,x2])。
假设我们有 3 个学生(N=3),他们的 2 项成绩(特征数 D=2:语文x0、数学x1):
学生 1:语文 80,数学 85 → x0=[80],x1=[85]
学生 2:语文 85,数学 90 → x0=[85],x1=[90]
学生 3:语文 90,数学 95 → x0=[90],x1=[95]


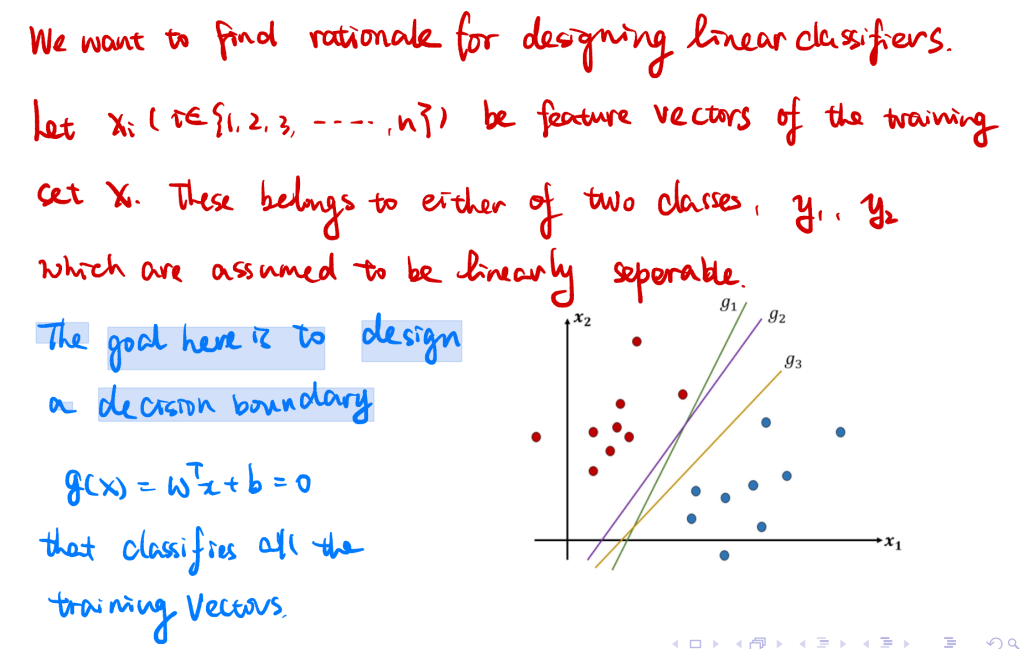
支持向量机
我们需要一个决策边界 —— 在这个案例中,它将是一条能够分离两个品种的直线。之后,我们就可以根据新数据落在直线的哪一侧来对其进行分类,这与我们在逻辑回归中所描述的方法类似。需要注意的是,我们可以清楚地看到,用一条直线就能分离这两个品种。能够通过这种方式分离的数据集被称为线性可分数据集。
1.2.1 最大边际
SVM 的核心是找到 “最优决策边界”—— 即位于两条平行分离线正中间的直线,这两条平行分离线需尽可能远离,它们之间的间隙称为 “分离间隔(separating margin)”,SVM 目标是最大化该间隔。间隔最大化的意义:间隔越宽,未见过的测试数据和未来数据落在正确分类侧的概率越高,模型泛化能力越强
决策边界的一个非常合理的选择是:与两个类别都保持最大间隔的那条边界。

我们认为,决策边界的一个非常合理的选择是:与两个类别都保持最大间隔的那条边界。
我们有两个类别
一个正类 y1,标签为 +1
一个负类 y2,标签为 -1
权重向量 w 和偏置 b 的构建方式是:线性模型的输出始终大于 1(对应正类)或小于 – 1(对应负类)
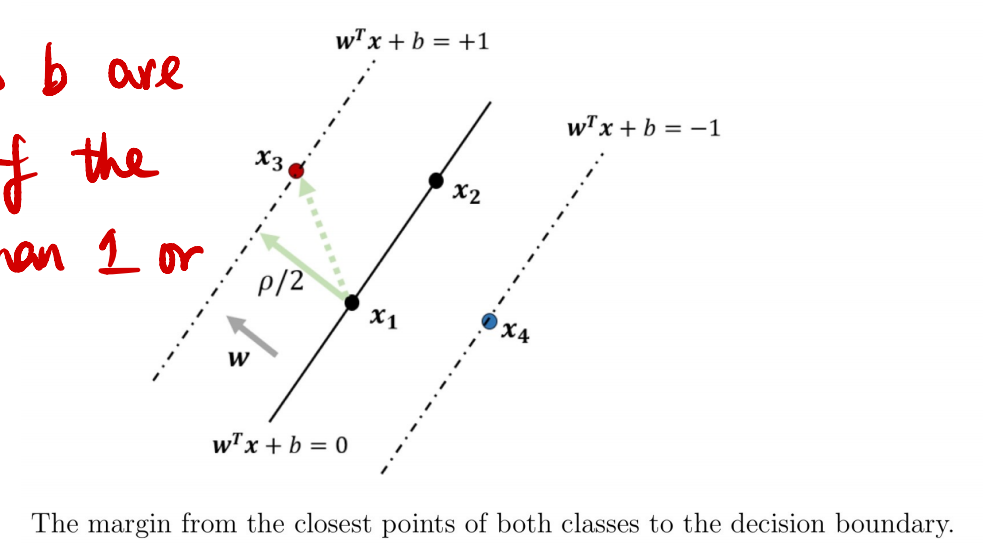

为了计算间隔ρ,
我们先计算正类中的点x3到决策边界的最近距离。
这个距离可以通过将线段对应的向量x3−x1投影到方向向量w上来计算:

这意味着,要最大化间隔ρ,我们需要最小化权重向量w的范数。
基于上述分析,我们的任务现在变成:
找到一个带有参数w和b的决策边界,使得
minw,b21∥w∥2
满足约束条件:
yi(wTxi+b)−1≥0∀ i=1,2,⋯,n
点、直线、平面与超平面


优化问题(Optimization Problem)

Perception 感知机
感知机是一种计算单元,它接收一个数值输入向量x,并通过权重向量w对其进行线性组合,随后可添加一个数值偏置b,得到一个实数结果。
激活函数的作用是判断输入信号的重要性,决定是否抑制该信号或传递其某种形式的输出。
感知机的结构示意图如下:输入向量x=(x1,x2,x3)T与权重向量w=(w1,w2,w3)T进行线性组合,添加可选偏置b后得到结果n,再将n输入激活函数σ:R→R,最终输出y。其数学表达式为:
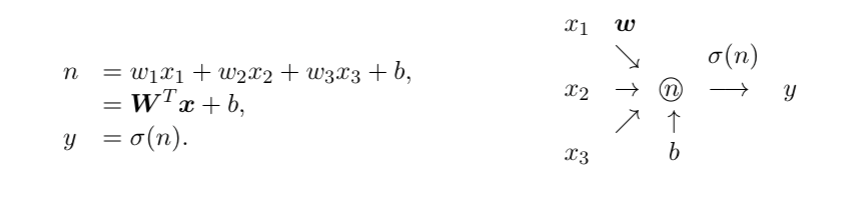
简洁表达式:y=σ(wTx+b)。
激活函数 activation function – The Heaviside Unit Step function


简单前馈神经网络 A simple feed forward neural net

将输入划分为两类(输出 1 或 0)
四分类问题 Four Classes

据此可将输入分为四类:C1、C2、C3、C4。
决策边界由以下两个方程确定:x1−6×2+1=0(即x2=(x1+1)/6)和2×1+4×2+2=0(即x2=−(x1+1)/2)。
该神经网络通过y的第一个元素判断输入点是否在直线x1−6×2+1=0的上方或下方,通过第二个元素判断输入点是否在直线2×1+4×2+2=0的上方或下方,进而确定输入点所属的类别。
人工神经网络 Artificial Neural Network
前馈 feeding forward:输入层的输入信号通过重复权重计算、偏置添加和激活处理等步骤在网络中传播,最终在最右侧的输出层得到输出结果

我们需要选择所有权重和偏置,使误差最小化。
代价最小化的常用方法是随机梯度下降(Stochastic Gradient Descent)。
梯度下降概述
-∇f 指示函数 f 下降最快的方向。



通常会绘制代价随轮数的变化曲线。理想情况下,代价应逐渐趋近于 0(或接近 0)。若未出现这种趋势,说明训练效果不佳,需调整超参数
熵 Entropy
交叉熵损失函数是一种常用的替代方案,有时被认为在分类问题中更具优势。

熵是衡量随机变量不确定性或意外程度的指标,熵值越大,不确定性越高。

信息

交叉熵 Cross Entropy
核心作用:替代 TSE(平方误差),作为分类问题的损失函数(衡量模型输出与真实标签的差距)

Softmax
问题:sigmoid 函数只能让输出在 0-1 之间,但无法保证总和为 1(比如 y=(0.13,0.25,0.75,0.31),总和 1.44,不是概率)

通俗理解:分子是 e 的 x_j 次方(放大差异),分母是所有 e 的 x_i 次方和(归一化),最终结果每个元素在 0-1 之间,总和为 1,完美适配交叉熵损失
完整的前向与反向传播算法(含交叉熵)

为了更新权重系数w1 – w6,目的是为了减小损失函数的数值
因此采用梯度下降的方法,计算损失函数与每一个系数的偏导数更新偏导数