术语说明(补充)
- 概率密度函数(pdf):全称为 Probability Density Function,用于描述连续型随机变量在某个取值点附近的概率 “密度”,通过积分可计算随机变量在某一区间内的概率。
- 概率质量函数(pmf):全称为 Probability Mass Function,用于描述离散型随机变量取各个可能值的概率(仅对离散型随机变量定义)。
- 累积分布函数(CDF):全称为 Cumulative Distribution Function(文中以FX(x)表示),用于描述随机变量X的取值小于等于x的概率,即FX(x)=Pr(X≤x),对连续型和离散型随机变量均适用。
- 期望(E(X)):全称为 Expectation,是随机变量取值的加权平均,权重为对应取值的概率(或概率密度),反映随机变量取值的 “中心趋势”,即 1 阶矩。

分布的矩
设随机变量\(X \in \mathbb{R}\),其概率分布的m阶矩定义为\(X^m\)的期望,其中\(m = 0,1,2,\dots\)。因此
设离散型随机变量X的概率质量函数为\(P(X = x_k) = p_k\)(\(k=1,2,\dots\)),则X的m阶矩可表示为:
\(\mathbb{E}(X^m) = \sum_{k} x_k^m \cdot p_k\)
若随机变量X的概率密度函数为\(f_X(x;\alpha_1,\dots,\alpha_p)\)(其中\(\alpha_1,\dots,\alpha_p\)为该概率密度函数的参数),则X的m阶矩可表示为:
\(\mathbb{E}(X^m) = \int_{-\infty}^{\infty} x^m f_X \left(x;\alpha_1,\dots,\alpha_p\right) dx\)

由上述定义可得出以下结论:
注:方差也可等价表示为:\(\text{Var}(X) = \mathbb{E}\left[(X – \mathbb{E}(X))^2\right]\)也就是说,经 “中心化” 变换后的随机变量\(X – \mathbb{E}(X)\)的 2 阶矩即为原随机变量X的方差。
对任意随机变量X,其概率分布的 1 阶矩即为X的期望\(\mathbb{E}(X)\)(将\(m = 1\)代入上述m阶矩的定义式即可验证)。
方差\(\text{Var}(X)\)的定义为 2 阶矩减去 1 阶矩的平方,即\(\text{Var}(X) = \mathbb{E}(X^2) – \left[\mathbb{E}(X)\right]^2\)
注:方差也可等价表示为:
\(\text{Var}(X) = \mathbb{E}\left[(X – \mathbb{E}(X))^2\right]\)
经 “中心化” 变换后的随机变量\(X – \mathbb{E}(X)\)的 2 阶矩即为原随机变量X的方差
随机变量X的概率密度函数的偏斜程度(即偏度)可通过X的 3 阶矩反映
随机变量X的概率密度函数的峰值程度(即峰度)可通过X的 4 阶矩反映


Moment Generating Function 矩生成函数(MGF)
矩生成函数MGF定义
$$M_X(t) = \mathbb{E}\left[e^{tX}\right]$$
如果你有 “概率质量函数 / 密度函数”
- 离散型(有 pmf: \(P(X = x_k) = p_k\))\(M_X(t) = \sum_{k} e^{tx_k} p_k\)
- 连续型(有 pdf: \(f_X(x)\))\(M_X(t) = \int_{-\infty}^{\infty} e^{tx} f_X(x) dx\)
如果有累计分布函数 \(F_X(x)\) \(M_X(t) = \int_{-\infty}^{\infty} e^{tx} dF_X(x)\)
通过计算矩生成函数关于t的i阶导数,并将t=0代入,即可得到该分布的i阶矩
由于矩包含了随机变量X概率分布的全部信息,因此已知矩生成函数等价于已知该概率分布,反之亦然
矩生成函数的性质
矩生成函数关于t的i阶导数在\(t = 0\)处的取值,等于该分布的i阶矩(其中\(i = 0,1,2,\dots\))
解释


矩生成函数\(M_X(t)\)与随机变量X的累积分布函数\(F_X(x)\)之间存在一一对应关系

随机变量X线性变换后Y的矩生成函数
设\(Y = aX + b\),则Y的矩生成函数为:
\(M_Y(t) = \mathbb{E}\left(e^{(aX+b)t}\right)\)
进一步推导可得:
\(\mathbb{E}\left(e^{aXt} e^{bt}\right) = e^{bt}\mathbb{E}\left(e^{X \cdot at}\right) = e^{bt} M_X(at)\)
泊松随机变量的矩生成函数
设离散型随机变量N服从均值为\(\lambda\)的泊松分布(其概率质量函数符合泊松分布形式),则N关于标量t的矩生成函数推导如下:\(\begin{align*} M_N(t) &:= \sum_{n \geq 0} \frac{\exp(-\lambda)\lambda^n}{n!} \exp(nt) \\ &= \exp(-\lambda) \sum_{n \geq 0} \frac{(\lambda \exp(t))^n}{n!} \\ &= \exp(-\lambda) \exp(\lambda \exp(t)) \\ &= \exp\left( \lambda \left( \exp(t) – 1 \right) \right) \end{align*}\)
- 若随机变量\(N_1 \sim Poisson(\lambda_1)\)且\(N_2 \sim Poisson(\lambda_2)\),则由上述结果可推出:
\(\begin{align*} M_{N_1 + N_2}(t) &= M_{N_1}(t) \cdot M_{N_2}(t) \\ &= \exp\left( \lambda_1 \left( \exp(t) – 1 \right) \right) \cdot \exp\left( \lambda_2 \left( \exp(t) – 1 \right) \right) \\ &= \exp\left( (\lambda_1 + \lambda_2) \left( \exp(t) – 1 \right) \right) \end{align*}\)
这表明\(N_1 + N_2\)服从参数为\(\lambda_1 + \lambda_2\)的泊松分布
PS:
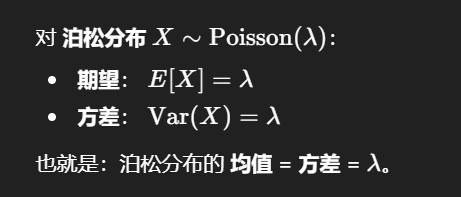
Exercise Q3 Q4 Q5 Q6 矩估计 Find an estimator using the method of moments

Q3. Poisson分布
一阶矩就是连续分布的期望公式计算含待估计参数的期望,再利用期望就是样本计算出的均值,联立得到参数的具体结果
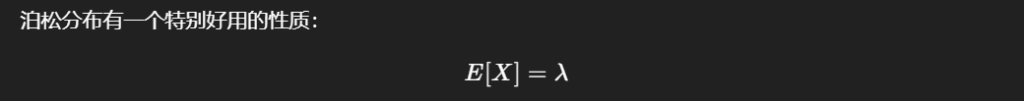

Q4.对于概率密度函数不是经典模型无法直接用结论的,则按照连续分布的期望公式计算

Q5.Gamma分布

Q6. exponential分布,注意加常量是针对X,所以如果是-(X+b)最终期望应为-b

用矩生成函数(MGF)来证明 “相加以后还是同一类分布,而且参数怎么变
- 先把 MGF 当成 “分布的指纹”对正态分布 \(X \sim N(\mu, \sigma^2)\),它的 MGF 长这样:\(M_X(t) = \mathbb{E}(e^{tX}) = \exp\left( \mu t + \frac{\sigma^2 t^2}{2} \right)\)
你可以把它理解成:只要看到某个随机变量的 MGF 恰好是这个形式,它就一定是正态分布,而且 \(\mu, \sigma^2\) 就是里面两个参数。
- 为什么两个正态相加,MGF 会变成 “参数相加”?设 \(X = X_1 + X_2\)。
关键一步是:
\(e^{t(X_1+X_2)} = e^{tX_1} e^{tX_2}\)
如果 \(X_1, X_2\) 相互独立,那么期望可以拆开:
\(M_X(t) = \mathbb{E}(e^{t(X_1+X_2)}) = \mathbb{E}(e^{tX_1}e^{tX_2}) = \mathbb{E}(e^{tX_1})\mathbb{E}(e^{tX_2}) = M_{X_1}(t) M_{X_2}(t)\)
把正态的 MGF 代进去:
\(M_{X_1}(t) M_{X_2}(t) = \exp\left( \mu_1 t + \frac{\sigma_1^2 t^2}{2} \right) \exp\left( \mu_2 t + \frac{\sigma_2^2 t^2}{2} \right)\)
两个指数相乘 = 指数里内容相加:
\(M_X(t) = \exp\left( (\mu_1 + \mu_2) t + \frac{(\sigma_1^2 + \sigma_2^2) t^2}{2} \right)\)
这又是 “正态 MGF 的标准形状”,所以立刻得到:
\(X \sim N(\mu_1 + \mu_2, \sigma_1^2 + \sigma_2^2)\)
一句话:独立 ⇒ MGF 相乘 ⇒ 指数里参数相加 ⇒ 还是正态