用希腊字母表示总体参数,大写拉丁字母表示随机变量,小写拉丁字母表示数据。
统计推断核心概念
| 核心概念 | 定义 | 用途 | 关键步骤 |
|---|---|---|---|
| 参数估计(含似然法) | 利用样本数据,对总体未知参数(如均值、方差)进行数值估计的方法,似然法是常用估计手段之一 | 得到总体参数的具体估计值,为后续推断奠定基础 | 1. 确定总体分布类型;2. 选择合适估计方法(如似然法);3. 代入样本数据计算估计值 |
| 假设检验 | 先对总体参数提出某种假设(如 “总体均值等于 μ₀”),再通过样本数据判断该假设是否成立的推断方式 | 验证对总体参数的猜想是否合理,判断样本结果是否具有统计意义 | 1. 建立原假设与备择假设;2. 选择检验统计量并确定显著性水平;3. 计算检验统计量值与 P 值;4. 作出拒绝或接受原假设的结论 |
| 置信区间 | 基于样本数据构建的区间,用于估计总体参数的可能取值范围,且该区间包含总体真实参数的概率为指定置信水平(如 95%) | 直观反映参数估计的可靠性与精度,给出参数的取值范围而非单一数值 | 1. 明确置信水平;2. 计算样本统计量与标准误;3. 结合对应分布临界值,构建置信区间 |
Estimators 估计量
任何以近似参数为目的的随机样本函数,称为样本统计量或估计量。若\(\theta\)是待估计的参数,其估计量通常记为\(\hat{\theta}\)。当估计量代入实际记录的观测值计算时,得到的数值称为(点)估计值,这个过程称为估计。
我们已经学过的估计量有以下几种


Method of Moments 矩估计法(2次)
核心是用样本矩替代对应的总体矩,得到参数的估计量
先来回顾一下原点矩和中心矩的公式

记巧:原点矩,可以写成(Xi-0),到原点距离的和,同理中心矩就是到分布的中心也就是期望的距离
二阶中心矩不是样本方差,而是总体方差,但是有的时候可以混用,当N很大的时候
矩估计法步骤
- 确定待估计参数的个数,需对应数量的矩;
- 将总体矩表示为参数的函数;
- 反解函数,将参数表示为总体矩的函数;
- 用样本矩替代总体矩,得到参数估计量。
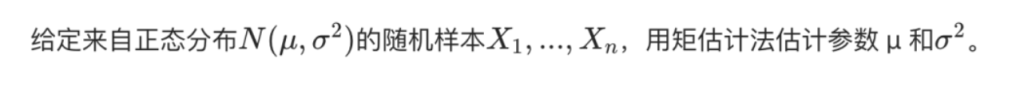


中心矩和原点矩可以混用

自我感悟:之前一直是套各种分布的公式,不知道如何才能判断这些数据到底是否遵循某种分布,以及完全没有思路求出分布的参数
现在明白应该先将参数点画在图表上,观测可能遵循哪种分布,再用矩估计用样本估计真实的参数
矩估计法直观且易于应用,但缺乏通用的优良性质,难以证明其估计量的普遍特性
Maximum Likelihood 最大似然估计法
当总体分布已知时,最大似然估计法是最重要的估计方法。其核心思想是:寻找能使观测样本出现概率最大的参数值。
例如,若 X 服从正态分布\(N(\mu, \sigma^{2})\),观测样本为 2.1、3.5、3.1、4.2、5.1、2.6,样本来自\(N(257,102)\)的概率极小,但来自\(N(3,1.52)\)的概率较大,最大似然估计就是寻找这样的参数值。
核心定义
- 似然函数(定义 7.7):设\(x_{1}, …, x_{n}\)是随机变量 X 的 n 个独立观测值,X 的概率函数(离散型)或概率密度函数(连续型)为\(f(x, \theta)\)(θ 为未知参数,可为向量),则似然函数定义为:
$$L(\theta )=f(x_{1},\theta )\cdot f(x_{2},\theta )\cdot …\cdot f(x_{n}, \theta)$$- 可以理解成:“已知样本结果,反推‘哪个参数 θ 更可能让这些样本出现’的‘可能性大小’”。
比如抛硬币,假设硬币正面概率是 θ(未知参数),你抛了 5 次得到 “正正反正正” 这个样本。 - 似然函数就是把这 5 次结果对应的概率(每次结果的概率是 f (x,θ))乘起来,得到的 L (θ) 就代表 “θ 取某个值时,出现这 5 次结果的可能性有多大”。
- 可以理解成:“已知样本结果,反推‘哪个参数 θ 更可能让这些样本出现’的‘可能性大小’”。
- 最大似然估计量(定义 7.8):使似然函数\(L(\theta)\)达到最大值的参数值\(t=h(x_{1}, …, x_{n})\),称为 θ 的最大似然估计值;对应的随机变量\(t=h(X_{1}, …, X_{n})\),称为 θ 的最大似然估计量(MLE)
- 简单说就是:在似然函数里找到那个 “让样本出现可能性最大” 的 θ 值。
接着上面抛硬币的例子,计算不同 θ(比如 θ=0.5、0.6)对应的 L (θ),找到 L (θ) 最大时的 θ 值,这个值就是 “最大似然估计值”
- 简单说就是:在似然函数里找到那个 “让样本出现可能性最大” 的 θ 值。
因为对数函数是严格递增的,所以似然函数\(L(\theta)\)和它的对数形式\(\ln L(\theta)\)取到最大值的参数\(\theta\)是一样的。而且原本是乘积形式的\(L(\theta)\),取对数后会变成求和形式的\(\ln L(\theta)\),计算起来更简单。所以实际中一般是通过让\(\ln L(\theta)\)最大化来求解参数。这个最大化的过程可以用微积分来算,有些情况则需要用数值方法来解决。
步骤:
- 构建似然函数
- 取对数并简化
- 对 μ 求导并令导数为 0(极值必要条件)
- 验证二阶导数小于 0(确认最大值):
正态分布的 MLE(\(\sigma^{2}\)已知)
Use the method of maximum likelihood to find an estimator of μ


若\(\sigma^{2}\)未知,可通过对 μ 和\(\sigma^{2}\)同时最大化似然函数估计两个参数(见习题集)。一般来说,最大似然法可同时估计多个参数。
MLE估计指数分布参数


均匀分布的MLE(特殊情况)

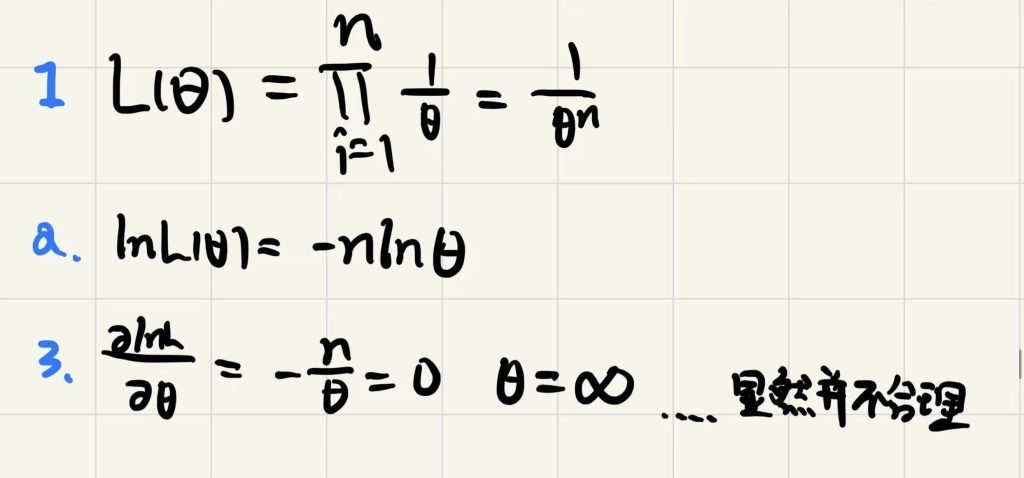
对于这类情况,需更深入分析似然函数:首先,若x落在区间\((0,\theta)\)之外,则\(f(x,\theta)=0\)。因此,似然函数\(L(\theta)=f(x_1,\theta)\cdot f(x_2,\theta)\cdot\cdots\cdot f(x_n,\theta)\)
当\(\theta\)小于至少一个观测值\(x_i\)时,其值为 0;在其他情况下,\(L(\theta)=\theta^{-n}\),即\(\theta\)的递减函数 —— 当\(\theta\)取最小值时,似然函数达到最大值。
结合以上两点可知:\(\theta\)需尽可能小,但不能小于观测值中的最大值(记为\(x_{\text{max}}\))。因此,\(\theta\)的最大似然估计值为:\(\hat{\theta}=x_{\text{max}}\)
需注意,该结果与直觉相悖 —— 因为均匀分布 \(U(0, \theta)\) 的期望 \(E[X] = \frac{\theta}{2}\),更符合直觉的 \(\theta\) 估计量应为 \(2\bar{X}\)(\(\bar{X}\) 为样本均值)。这一问题将在研讨课中进一步讨论
在多数情况下,最大似然估计量(MLE)存在且唯一,但也存在少数 MLE 不存在或不唯一的情况,因此该方法存在一定局限性。尽管如此,最大似然法的优势在于其直观性,且由此得到的估计量通常具有多项理想的统计性质(详见第 4 节);此外,似然理论也是置信区间和假设检验等方法的基础(详见后续章节)
估计一个参数


估计两个参数

估计一个参数,但不能用MLE

估计两个参数,但不能用MLE

估计量的理想性质
对于同一个待估量,可能存在多个估计量可供选择。如何抉择?一个 “优良” 的估计量,其随机取值应集中在待估参数的真实值附近。例如,样本均值\(\bar{X} = \frac{1}{n}\sum_{i=1}^{n}X_i\)是期望\(E[X]\)的一个估计量 —— 它是否是 “优良” 的估计量?
我们用\(\theta\)表示感兴趣的参数,用T表示\(\theta\)的估计量。接下来,我们将讨论估计量T的分布应具备的一些理想性质
例子
根据中心极限定理,当 n 足够大时,\(\bar{X}\)的分布趋近于正态分布\(N(\mu, \sigma^2/n)\)(其中\(\mu = E[X]\),\(\sigma^2\)是 X 的方差)。可见,\(\bar{X}\)的分布确实具有极佳的性质:呈钟形曲线分布,且曲线中心恰好是\(E[X]\)的真实值,同时分布宽度会随 n 的增大而变窄。
另一方面,在示例 7.5 中我们看到,指数分布\(Exp(\lambda)\)的参数 λ 的最大似然估计量(MLE)是\(\frac{1}{\bar{X}}\)。经过(略显复杂的)计算可证明,对于指数分布,\(E\left[\frac{1}{\bar{X}}\right] \neq \lambda\)—— 因此,尽管\(\bar{X}\)是均值\(\frac{1}{\lambda}\)的优良估计量,但反之不成立:\(\frac{1}{\bar{X}}\)并非参数 λ 本身的完美估计量。
无偏性 Unbiasedness
如果估计量的平均值(期望)等于真值,即\(\mathbb{E}[T] = \theta\),则称T是\(\theta\)的无偏估计量unbiased estimator
不具备该性质的估计量称为有偏估计量,\(\delta = \mathbb{E}[T] – \theta\)称为该估计量的偏差
“无偏估计量的函数不一定是无偏的”
注 2:原因在于,一般情况下,随机变量某一函数的期望并不等于该函数在随机变量期望处的取值,即\(\mathbb{E}[f(X)] \neq f(\mathbb{E}[X])\)。具体到本例,平方根的期望通常不等于期望的平方根。

证明样本均值\(\bar{X}\)是\(\mu\)的无偏估计量
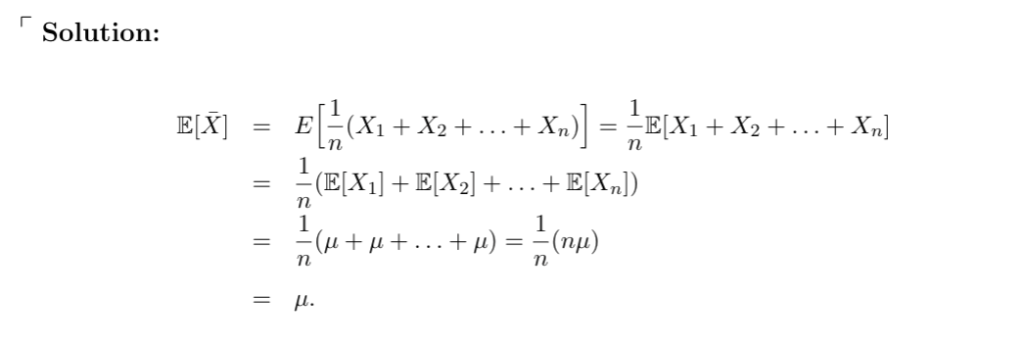
设\(X_{1}, …, X_{n}\)是来自均值为\(\mu\)、方差为\(\sigma^{2}\)的分布的随机样本,同理可证明样本方差\(S^{2}=\frac{1}{n-1} \sum_{i=1}^{n}(X_{i}-\bar{X})^{2}\)是\(\sigma^{2}\)的无偏估计量。
现在我们知道 \(S^{2}=\frac{1}{n-1} \sum_{i=1}^{n}(X_{i}-\bar{X})^{2}\) 是 \(\sigma^{2}\) 的无偏估计量。因此,\(\tilde{S}^{2}=\frac{1}{n} \sum_{i=1}^{n}(X_{i}-\bar{X})^{2}\) 必然是 \(\sigma^{2}\) 的有偏估计量
所以计算样本方差时,我们采用 \(n-1\) 而非 n 作为分母
说明无偏性的局限性:设\(X_{1}, …, X_{n}\)是来自均值为\(\mu\)、方差为\(\sigma^{2}\)的分布的随机样本,求样本均值\(\bar{X}\)的方差
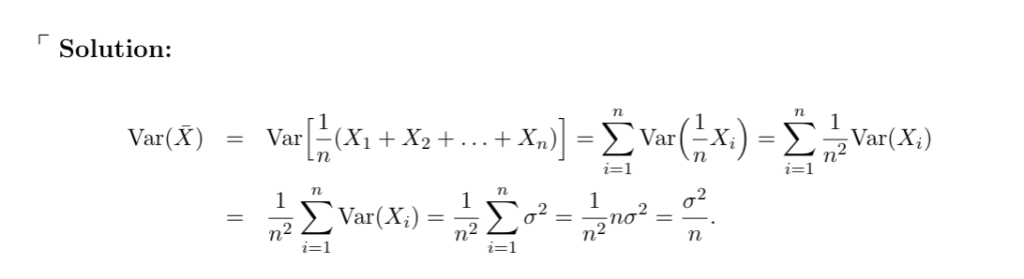
我们发现,样本均值\(\bar{X}\)的方差是总体方差的\(\frac{1}{n}\)(即缩小了 n 倍)!这一结论为 “平均值的波动性小于单个观测值” 这一直观认知提供了数学表达。
通过选取足够大的样本,我们可以将样本均值的方差缩小到任意理想水平。因此,我们可以说\(\bar{X}\)是一个 “相当精确” 的估计量,且其精度会随着样本量n的增大而提高。
仅具备无偏性并不足以成为理想的估计量 ,还需要与小方差与小偏差的结合
有效性与均方误差 Efficiency and Mean Squared Error
定义 8.2 有效性:设\(T_1\)和\(T_2\)是同一参数\(\theta\)的两个无偏估计量。若\(Var(T_2) < Var(T_1)\)(即\(T_2\)的方差小于\(T_1\)的方差),则称估计量\(T_2\)比估计量\(T_1\)更有效 efficient。

指数分布,其期望 \(E[X] = \lambda\),方差 \(Var[X] = \lambda^2\)。利用这两个性质,我们可进行如下推导:
- 计算 T 的期望:\(E[T] = \frac{E[X_1] + E[X_2]}{2} = \frac{2\lambda}{2} = \lambda\),因此 T 是 \(\lambda\) 的无偏估计量。
- 计算 \(\bar{X}\) 的期望:\(E[\bar{X}] = \frac{10\lambda}{10} = \lambda\),因此 \(\bar{X}\) 也是 \(\lambda\) 的无偏估计量。
接下来通过方差比较二者的有效性:
- T 的方差:\(Var(T) = \frac{2\lambda^2}{4} = \frac{\lambda^2}{2}\)
- \(\bar{X}\) 的方差:\(Var(\bar{X}) = \frac{10\lambda^2}{100} = \frac{\lambda^2}{10}\)
由于 \(Var(\bar{X}) < Var(T)\),因此 \(\bar{X}\) 比 T 更有效,是更优的估计量
然而,在比较可能存在偏差的估计量时,方差较小的有偏估计量可能比方差较大的无偏估计量更可取。这种情况下,我们需要引入均方误差(MSE) 这一评价指标
定义 8.3 均方误差
设 T 是 θ 的估计量,其均方误差定义为:
\(MSE(T)=\mathbb{E}[(T-\theta)^2] .\)
定理 8.1
\(MSE(T)=Var(T)+(bias)^2 .\)
证明: 设\(\mathbb{E}[T]=\mu\),则:
\(\begin{aligned} MSE(T)&=\mathbb{E}[(T-\theta)^2]=\mathbb{E}[(T-\mu)+(\mu-\theta)]^2 \\ &=\mathbb{E}[(T-\mu)^2] + 2(\mu-\theta)\mathbb{E}[T-\mu] + (\mu-\theta)^2 \\ &=Var(T)+(偏倚)^2 . \end{aligned}\)
其中,\(2(\mu-\theta)\mathbb{E}[T-\mu]=0\)(因\(\mathbb{E}[T-\mu]=\mu-\mu=0\))
均方误差最小的估计量为最优
若 T 是无偏估计量(\(\mathbb{E}[T]=\theta\)),则\(MSE(T)=Var(T)\)。均方误差通常是 θ 的函数,可用于估计量比较:,它意味着估计值与真实值的平均平方差更小,即方差与偏倚达到良好平衡

证明\(\bar{X}\)是 θ 的有偏估计量,并计算偏倚。
求\(\bar{X}\)作为 θ 的估计量的均方误差。
找到\(\bar{X}\)的一个函数,使其成为 θ 的无偏估计量,并与\(\bar{X}\)比较。

第二问,求A 作为 B 的估计量的均方误差(MSE),其含义就是A 和 B 之间误差平方的期望
Minimum-Variance Estimators 最小方差估计量
对于两个无偏估计量,可选择方差更小的那个,但这无法说明是否存在更优的第三个估计量。本节将解答一个更根本的问题:给定特定推断问题,能否找到方差最小的无偏估计量?
定理 8.2 克拉默 – 拉奥不等式
设\(X_1, …, X_n\)是来自分布\(f(x, \theta)\)的随机样本,在\(f(x, \theta)\)满足一定正则条件下,对 θ 的任意无偏估计量 T,有:
\(Var(T) \geq \frac{1}{I_\theta} ,\)
其中\(I_\theta = \mathbb{E}_X\left[\left(\frac{\partial log L(\theta)}{\partial \theta}\right)^2\right] = -\mathbb{E}_X\left[\frac{\partial^2 log L(\theta)}{\partial \theta^2}\right]\),称为观测值中关于 θ 的费希尔信息;\(\frac{1}{I_\theta}\)称为克拉默 – 拉奥下界。
该定理的重要意义在于:若能找到一个无偏估计量,其方差等于克拉默 – 拉奥下界,则可确定该估计量为最优估计量,此估计量被称为一致最小方差无偏估计量(Uniform Minimum Variance Unbiased Estimator,简称 UMVUE)
证明正态分布中,\(\bar{X}\)是 μ 的 UMVUE
Example 8.6 Let X1, . . . , Xn be a random sample from a N (μ, σ2) distribution. Show that
the estimator ¯X is the UMVUE of μ.

设\(X_1, …, X_n\)是来自泊松分布 Poisson (λ) 的随机样本,证明\(\bar{X}\)是 λ 的 UMVUE
解答: 泊松分布的似然函数为:
\(L(\lambda)=e^{-n\lambda}\frac{\lambda^{\sum_{i=1}^{n}x_i}}{\prod_{i=1}^{n}x_i!} .\)
似然函数的对数为:
\(log L(\lambda)=-n\lambda + \sum_{i=1}^{n}x_i log\lambda – log\left(\prod_{i=1}^{n}x_i!\right) .\)
计算二阶导数:
\(\frac{\partial^2 log L(\lambda)}{\partial \lambda^2}=-\frac{\sum_{i=1}^{n}x_i}{\lambda^2} .\)
费希尔信息为:
\(I_\lambda = -\mathbb{E}\left[\frac{\partial^2 log L(\lambda)}{\partial \lambda^2}\right]=\frac{n\lambda}{\lambda^2}=\frac{n}{\lambda} .\)
最大似然估计量的渐近性质 Asymptotic Properties of Maximum Likelihood Estimators
克拉默 – 拉奥下界为\(\frac{1}{I_\lambda}=\frac{\lambda}{n}\)。由于\(\bar{X}\)是无偏估计量,且\(Var(\bar{X})=\frac{\lambda}{n}\),达到克拉默 – 拉奥下界,因此\(\bar{X}\)是 λ 的 UMVUE。
在通常的正则条件下,若\(\hat{\theta}\)是 θ 的最大似然估计量,则\(\hat{\theta}\)渐近服从正态分布\(\hat{\theta} \sim N(\theta, I_\theta^{-1})\),其中\(I_\theta\)是费希尔信息。
该结果表明,渐近情况下,\(\hat{\theta}\)是无偏的,达到克拉默 – 拉奥下界,且服从正态分布。因此,渐近意义下,最大似然估计量是一致最小方差无偏估计量,这也解释了最大似然法在参数估计中的广泛应用。