离散变量的概率质量函数PMF和概率累积分布函数CDF
\( X \) 的概率质量函数;这是一个函数 \( f_X: \mathbb{Z} \to [0,1] \),定义为 \( f_X(n) = \mathbb{P}(A_n) = \mathbb{P}(X = n) \),表示随机变量 X 取值小于或等于给定值 x 的概率。累积分布函数为:
\[
F(x) = \sum_{x_i \leq x} f(x_i).
\]对于连续型随机变量 \( X \),其累积分布函数 \( F_X(x) \) 定义为:
\[
F_X(x) = \mathbb{P}(X \leq x) = \int_{-\infty}^{x} f_X(t) \, dt,
\]其中 \( f_X(x) \) 是概率密度函数(PDF)。根据微积分基本定理,对 \( F_X(x) \) 求导即可恢复 PDF:\[
f_X(x) = \frac{d}{dx} F_X(x).
\]对累积分布函数(CDF)求导可以得到概率密度函数(PDF)
需要满足:\[ \sum_{n \in \mathbb{Z}} f_X(n) = \sum_{n \in \mathbb{Z}} \mathbb{P}(X = n) = 1 \]
或 \(\int_{-\infty}^{+\infty} f_X(x)dx = 1\)
为什么不需要乘以自变量:CDF 的目的是计算 X落在某个区间内的概率(如 P(X≤x)。在计算某些期望值或矩时,会用到 x 与概率的乘积
离散型随机变量的一个特征是其对应的分布函数是阶梯函数。
已知离散变量的概率求CDF

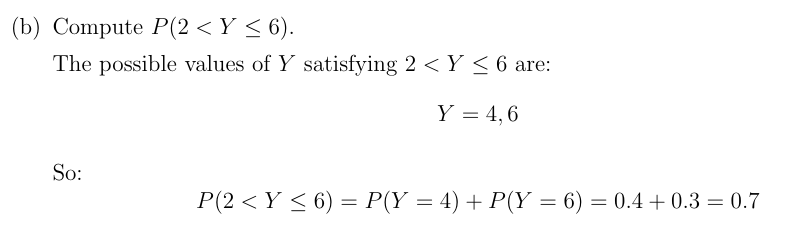
已知连续变量CDF求PDF – 对CDF求导
假设X是一个随机变量,其累积分布函数为: \[ F_X(x)= \begin{cases} 0, & x < 1 \\ (x – 1)^5, & 1\leq x\leq 2 \\ 1, & 其他 \end{cases} \] 求X的概率密度函数。 解:首先注意到函数\(F_X\)是连续的,因此该随机变量是连续型随机变量。为了找到X的概率密度函数,我们只需要对\(F_X\)求导,实际上: \[ f_X(x)=\frac{dF_X(x)}{dx}= \begin{cases} 0, & x < 1 \\ 5(x – 1)^4, & 1\leq x\leq 2 \\ 0, & 其他 \end{cases} \]
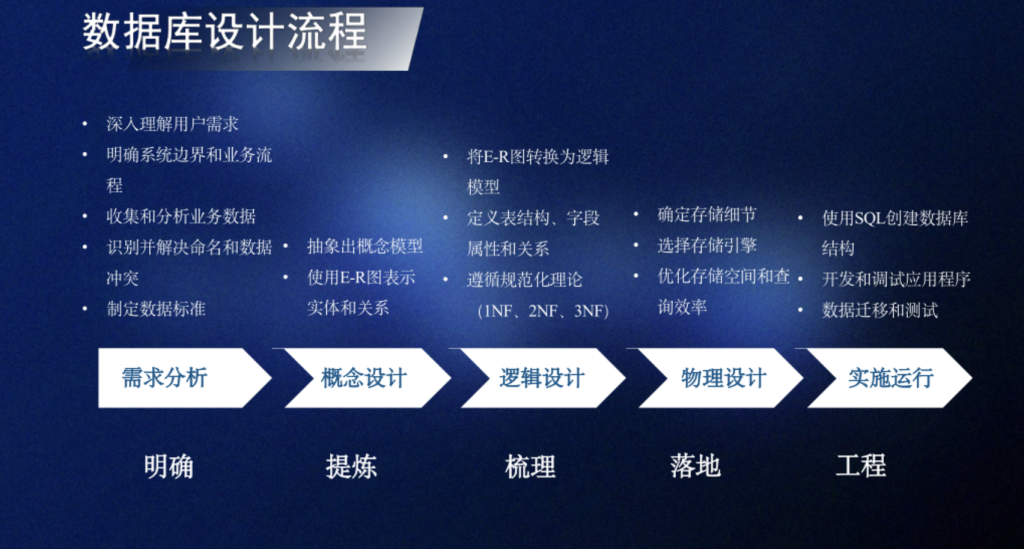
例1. 某公司为顾客生产了七台大型机器,其中三台不符合顾客的规格要求。质检员随机抽取两台机器进行检查。设离散型随机变量 X表示被检查的机器中符合顾客规格的数量。

已知连续变量PDF求CDF – 求积分
求与具有概率密度函数的连续型随机变量Y相关的累积分布\(F_Y\) \[ f_Y(y)= \begin{cases} 4(y – 2)^3, & 2\leq y\leq 3 \\ 0, & 其他 \end{cases} \] 解:首先注意到\(f_Y\)确实满足命题2的性质,因为对所有y, \(f_Y(y)\geq0\),并且 \[ \int_{-\infty}^{+\infty} f_Y(y)dy = \int_{2}^{3} 4(y – 2)^3dy = [(y – 2)^4]_2^3 = 1 \] 由于 \[ F_Y(y) = \int_{-\infty}^{y} f_Y(t)dt \] 我们考虑三种情况\(y\lt2\)、\(2\leq y\leq3\)和\(y\gt3\),得到: \[ F_Y(y)= \begin{cases} 0, & y\leq2 \\ (y – 2)^4, & 2\leq y\leq3 \\ 1, & 3\leq y \end{cases} \]
根据PDF的两个条件求
计算区间中PDF值
用PDF计算期望和方差
已知\(f(y)=cy^2\),\(0\leq y\leq5\),其他情况\(f(y)=0\),求使\(f(y)\)成为有效密度函数的\(c\)值。 解:我们必须检查\(f\)是否满足命题2中的条件,即\(f(y)\geq0\)对所有\(y\)成立(这要求\(c\geq0\)),并且\(\int_{-\infty}^{\infty}f(y)dy = 1\)。现在我们计算 \[ \int_{-\infty}^{\infty}f(y)dy=\left[\frac{c}{3}y^3\right]_0^5=\frac{125c}{3} \] 因此我们发现\(c = \frac{3}{125}\)。 例6:在前面的例子中,\(Y\)的\(\mathbb{P}(1\leq Y\leq3)\)和\(\mathbb{P}(1\lt Y\lt3)\)是多少? 解:由于对于任何特定值\(y\),\(\mathbb{P}(Y = y)=0\),所以我们有\(\mathbb{P}(1\leq Y\leq3)=\mathbb{P}(1\lt Y\lt3)\)。现在,我们计算: \[ \mathbb{P}(1\leq Y\leq3)=\frac{3}{125}\left[\frac{y^3}{3}\right]_1^3=\frac{(27 – 1)}{125}=\frac{26}{125} \]

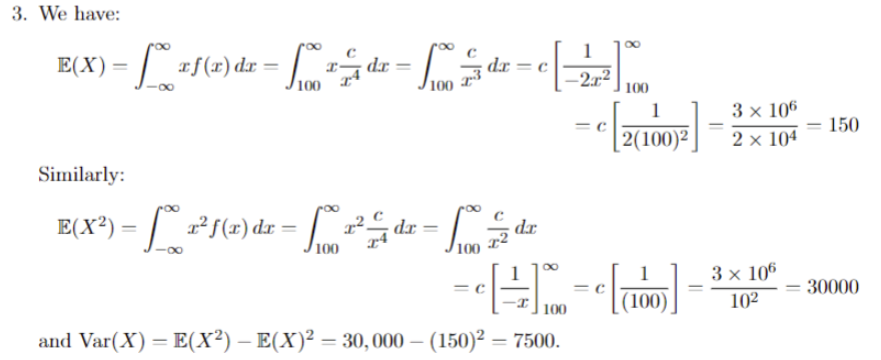
通过变量变换来求一个新随机变量的PDF/PMF
连续变量 PDF:
给定一个随机变量 \( X \) 和它的概率密度函数 \( f_X(x) \),比如它是从 0 到 1 之间均匀分布的。现在你用一个函数 \( Y = g(X) \),比如 \(Y = -\ln(X)\),来 “加工” 这个 X,得到了一个新随机变量 Y。
我们需要找到 \( Y \) 的概率密度函数 \( f_Y(y) \)。对于单调函数的随机变量变换,可以使用以下公式: \[ f_Y(y) = f_X\left(g^{-1}(y)\right) \cdot \left| \frac{d}{dy}g^{-1}(y) \right| \]

概率密度虽然不是概率,但它乘上区间长度就是概率,比如:\(P(a \leq X \leq b) \approx f_X(x) \cdot (b – a)\)
现在如果你做了变量变换 \(Y = g(X)\),那么:
- 原来的区间长度是 dx
- 变换后的区间长度是 dy
为了保持概率不变,我们有:\(f_X(x) \cdot dx = f_Y(y) \cdot dy\)
两边都除以 dy,得到:\(f_Y(y) = f_X(x) \cdot \frac{dx}{dy} = f_X\left(g^{-1}(y)\right) \cdot \left| \frac{d}{dy}g^{-1}(y) \right|\)
导数 \(\frac{dx}{dy}\) 哪里来的?区间缩放比例变化的产物。为什么求逆函数?输入从x变成y
\( f_Y(y) \):是变量 \( Y \) 的密度函数(表示 \( Y \) 取值为 \( y \) 时的密度 ); – \( f_X(x) \):是变量 \( X \) 的密度函数; – 所以整个变换公式里,我们用的是 \( X \) 的密度函数,来间接推导出 \( Y \) 的密度函数

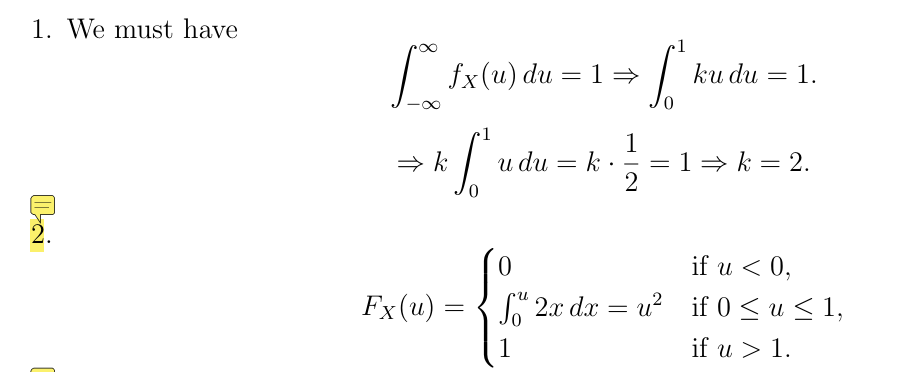

离散变量PMF:

独立性


以上为对之前知识的回顾,现在开始学习新的内容 – 常见的离散随机变量
常见分布
某些类型的随机变量在实践中出现得非常频繁,因此了解相关数值事件的概率非常有用。这种概率的集合称为离散随机变量的概率分布。 许多实验表现出相似的特征,并生成具有相同类型概率分布的随机变量。了解常见的概率分布可以节省大量时间,因为我们不需要反复解决相同的概率问题。在本课程中,我们将学习四种离散分布:伯努利分布、二项分布、泊松分布和几何分布。
Binomial Distribution 伯努利分布(二项分布)
条件:
- 某个事件发生的次数有限
- 事件的结果有且只有两种(成功或失败)
- 事件的结果的概率相等且不变。比如每次抛硬币相同面朝上的概率是一样的
- 各个实验之间相互独立
公式:假设试验成功的概率为 \( p \),所以失败的概率为 \( 1 – p \),设为 \( q \)。现在进行这个试验,假设这个试验进行了 \( n \) 次,有 \( r \) 次获得了成功。用二项分布的概率质量函数表示为: \[ P(X = r) = C_n^r \ p^r \ q^{n-r} \]
前面表示在 n 次试验中获得 r 次成功和(n−r)次失败的方式数量。因为试验的所有结果都需要被考虑。
后面表示在特定排列下获得 x 次成功和(n−x)次失败的概率。
相当于把满足条件的所有情况的概率加起来
符号 X∼B(n,p)表示随机变量 X服从参数为 n 和 p 的二项分布。n表示试验的次数。p表示每次试验成功的概率,反过来说如果 x 是二项实验 n 次试验中成功的总次数,那么 x 就是一个二项随机变量。
E[X]=np,Var(X)=np(1−p)
例:沿着某条赛道行驶的山地自行车骑手爆胎的概率为 0.05。求在 17 名骑手中:
这是一个二项分布问题,题目告诉我们:
- 爆胎概率 \(p = 0.05\)
- 骑手人数 \(n = 17\)
- 设 \(X \sim B(n = 17, p = 0.05)\):表示爆胎的人数。
(a) 恰好有一人爆胎
(b) 最多三人爆胎
P(X=0)+P(X=1)+P(X=2)+P(X=3)\[
\mathbb{P}(X \leq 3) \approx 0.4181 + 0.3741 + 0.1575 + 0.0415 \approx 0.9912
\]
(c) 两人或更多人爆胎
需要计算 P(X≥2),即 1−P(X<2)=1−P(X=0)−P(X=1)\[
\mathbb{P}(X \geq 2) = 1 – 0.4181 – 0.3741 \approx 0.2078
\]
解. 设 X为爆胎的骑手数量,则 X∼B(17,0.05),表示试验次数17次,每次爆胎的概率为0.05
\[
\mathbb{P}(X = 0) = C(17, 0) \cdot (0.05)^0 \cdot (0.95)^{17} = 1 \cdot 1 \cdot (0.95)^{17} \approx 0.4181
\]\[
\mathbb{P}(X=1) = C(17,1) \cdot (0.05)^1 \cdot (0.95)^{16}
\]\[
\mathbb{P}(X = 2) = C(17, 2) \cdot (0.05)^2 \cdot (0.95)^{15} = 136 \cdot 0.0025 \cdot (0.95)^{15} \approx 136 \cdot 0.0025 \cdot 0.4633 \approx 0.1575
\]\[
\mathbb{P}(X = 3) = C(17, 3) \cdot (0.05)^3 \cdot (0.95)^{14} = 680 \cdot 0.000125 \cdot (0.95)^{14} \approx 680 \cdot 0.000125 \cdot 0.4877 \approx 0.0415
\]


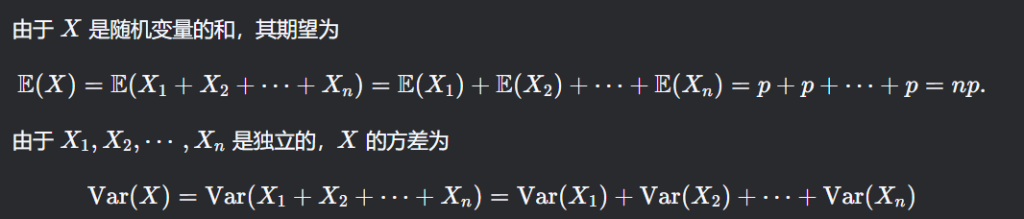
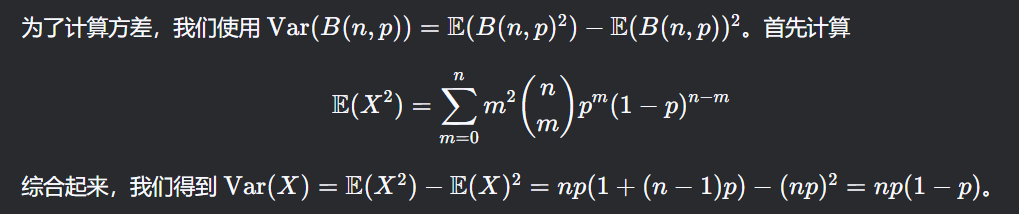

Geometric Distribution 几何分布
与二项分布的“n次实验k次成功的概率”不同,几何分布关心的是,试验k次才得到第一次成功的机率。用几何分布的概率质量函数表示为:
\[
P\left( X = k \right) = \left( 1 – p \right)^{k – 1} p, \quad k = 1, 2, \ldots
\]
为什么几何分布的概率质量函数的计算前面没有二项分布那样前面有组合数?
概率质量函数,计算的是某事件发生的概率,有两种计算思路:
一种是所有符合条件的事件×对应发生的概率的和。
另一种是符合条件的事件数 / 事件的总数,这种一般适合组合和排列不太适合可以有重复情况的例题。
二项分布和几何分布都属于用第一种方式计算概率质量函数
回到主题为什么几何分布的概率质量函数前没有组合数,因为其分布限制了只能最后一个为反例,也就是说符合事件条件的事件数只能为1,而二项分布符合条件的事件数有很多,要用组合数计算。但他们后面跟的都是该事件发生的概率
记作Y∼Geometric(p),P表示成功的概率,注意与二项分布相同,每次事件发生(成功)的概率是相同的
期望:\(E(Y) = \frac{1}{p} \quad\)
方差:\(\mathrm{Var}(Y) = \frac{1 – p}{p^{2}}\)
几何分布的期望定义为:
\[
E(Y) = \sum_{m=1}^{\infty} m \cdot P(Y=m)
\]根据几何分布的概率质量函数 \( P(Y=m) = p(1-p)^{m-1} \),代入上式:
\[
E(Y) = \sum_{m=1}^{\infty} m \cdot p(1-p)^{m-1}
\]将 \( p \) 提出求和符号:\[
E(Y) = p \sum_{m=1}^{\infty} m(1-p)^{m-1}
\]我们知道,对于 \( |x| < 1 \),有:\[
\sum_{m=1}^{\infty} mx^{m-1} = \frac{1}{(1-x)^2}
\]令 \( x = 1 – p \),则:\[
\sum_{m=1}^{\infty} m(1-p)^{m-1} = \frac{1}{(1-(1-p))^2} = \frac{1}{p^2}
\]因此:\[
E(Y) = p \cdot \frac{1}{p^2} = \frac{1}{p}
\]

二项分布与几何分布杂交题
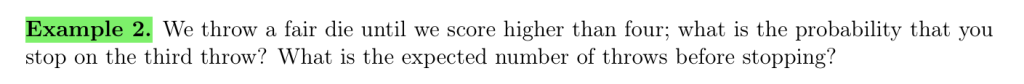
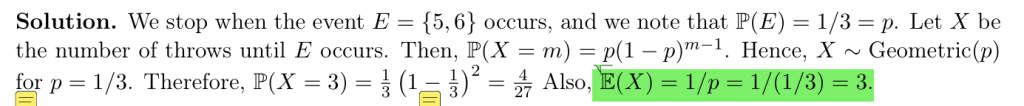
Poisson Distribution 泊松分布
泊松分布用于描述特定间隔内事件发生次数,需满足等长间隔事件发生概率相同、不同间隔事件发生相互独立。其是二项分布在\(n\to\infty\)、\(p\to0\)且\(np = \lambda\)(平均发生率固定)时的极限形式。若预期发生次数为\(\lambda\),事件发生\(m\)次的概率为\(P(X = m)=\frac{\lambda^{m}e^{-\lambda}}{m!}\)(\(m = 0,1,\dots\)),记为\(X\sim\text{Poisson}(\lambda)\),且期望和方差均为\(\lambda\)。
记为 \(X \sim \text{Poisson}(\lambda)\)
定义了参数为 λ 的泊松分布 Z。我们将假设它给出了X∼B(n,p)的有效近似
泊松分布的期望和方差均为 \(\lambda\)
例:批量生产的针以每盒 1000支包装。据信,平均每 2000支针中有 11 支不合格。求一盒中有 22 支或更多不合格针的概率
由于 n较大且 p较小,可以使用泊松分布来近似二项分布。泊松分布的参数 λ为:λ=n⋅p=1000⋅0.0005=0.5
我们需要计算 \(\mathbb{P}(X \geq 2)\), 即:
\[
\mathbb{P}(X \geq 2) = 1 – \mathbb{P}(X = 0) – \mathbb{P}(X = 1)
\]
计算 \(\mathbb{P}(X = 0)\) 和 \(\mathbb{P}(X = 1)\):
\[
\mathbb{P}(X = 0) = e^{-0.5} \frac{0.5^0}{0!} = e^{-0.5} \approx 0.6065
\]
\[
\mathbb{P}(X = 1) = e^{-0.5} \frac{0.5^1}{1!} = 0.5 \cdot e^{-0.5} \approx 0.3033
\]
因此:
\[
\mathbb{P}(X \geq 2) = 1 – 0.6065 – 0.3033 = 0.0902
\]



例3:泊松分布与二项分布的对比

例4:注意隐藏的试验次数1周

例5:平均发生率已知,所以用泊松分布

例6:如果更改前提条件,注意修改平均值\(lambda\)。对单天内使用泊松分布,对整体使用二项分布




Continuous Random Variables
累积分布函数的3条性质

连续型概率分布的性质
- 对所有x,均有f(x)≥0
- 概率曲线f(x)下方的总面积等于 1
重点强调:连续型概率分布曲线下的面积代表概率。
常见连续型概率分布
连续型随机变量的概率密度函数包含了该变量的全部信息。常用的概率密度函数有正态分布、均匀分布和指数分布,更复杂的分布则包括威布尔分布和伽马分布。
Uniform Distribution 均匀分布 U(a,b)
均匀分布既可以是离散型的,也可以是连续型的

若随机变量 X 在连续区间 [a,b]上取值,且任意子区间的概率密度相同,则服从连续均匀分布。

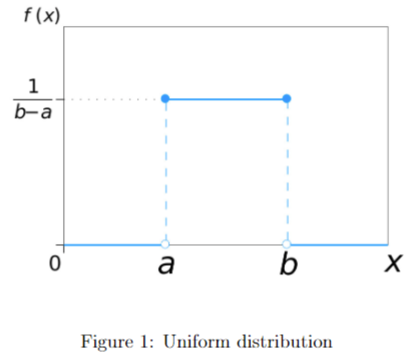

例题:


例题(新):

Exponential Distribution 指数分布
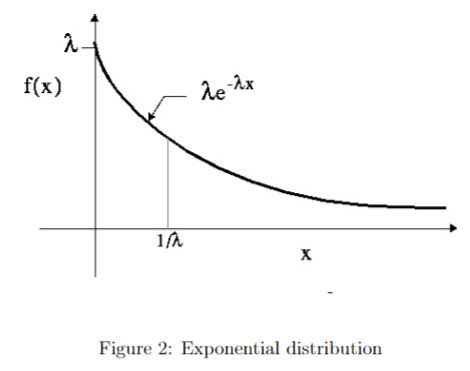



例题:


例2:


The Gamma distribution 伽马分布


The Pareto distribution 帕累托分布


注意F(x)累积分布函数CDF定义中的积分上下限是x,下限是负无穷,但是实际应用在常用分布的概率密度函数时,由于0区间,实际都会修改上下限
Normal Distribution正态分布 / Gaussian Distribution 高斯分布
二项分布的条件和几何分布相同,泊松分布是对二项分布在一定条件下的近似,但这些都是离散变量的分布,接下来是连续变量的分布,正态分布描述了由均值 \(\mu\) 和标准差 \(\sigma\) 表征的连续概率分布,通常记作 \(X \sim N(\mu, \sigma^2)\)。概率密度函数(PDF)为:
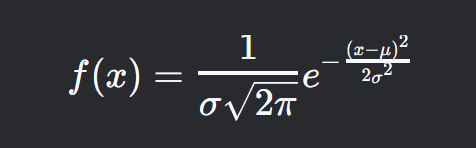
– \(\mu\)(均值):分布的中心位置。
– \(\sigma\)(标准差):衡量分布的扩散程度。
– \(\sigma^2\)(方差):量化值的离散程度。
– 归一化因子 \(\frac{1}{\sigma\sqrt{2\pi}}\):确保总概率积分为1。
所以不需要计算方差和期望,分布中的两个参数即为期望和方差
– 指数项 \(e^{-\frac{(x – \mu)^2}{2\sigma^2}}\):控制钟形形状,随着 \(x\) 远离 \(\mu\),概率减小。
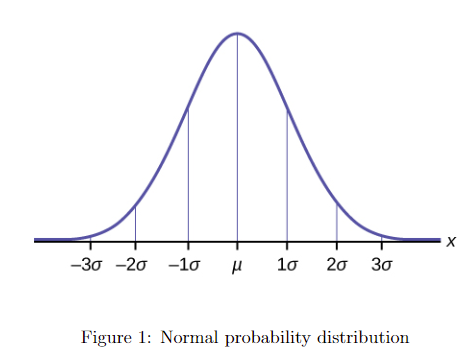
正态概率分布 \(N(\mu,\sigma^{2})\) 的图像是钟形的,关于均值 \(\mu\) 对称,标准差为 \(\sigma\)(见图1)。曲线下的总面积为1,对应总概率。分布的形状取决于两个特征:均值 \(\mu\) 和标准差 \(\sigma\)。知道这两个参数就足以描述相关正态分布的形状。均值决定了曲线的位置,而标准差决定了它的离散程度

正态分布的线性性:

实际是方差和期望的性质
正态分布的概率计算
实际要将正态分布转换为标准正态分布再进行计算
概率曲线 / 概率密度函数:若连续型随机变量x落在某一指定数值区间的概率,等于概率曲线f(x)在该区间下方对应的面积,则曲线f(x)即为该随机变量x的连续型概率分布。落在a到b之间的概率,即阴影面积 = P(a≤x≤b)

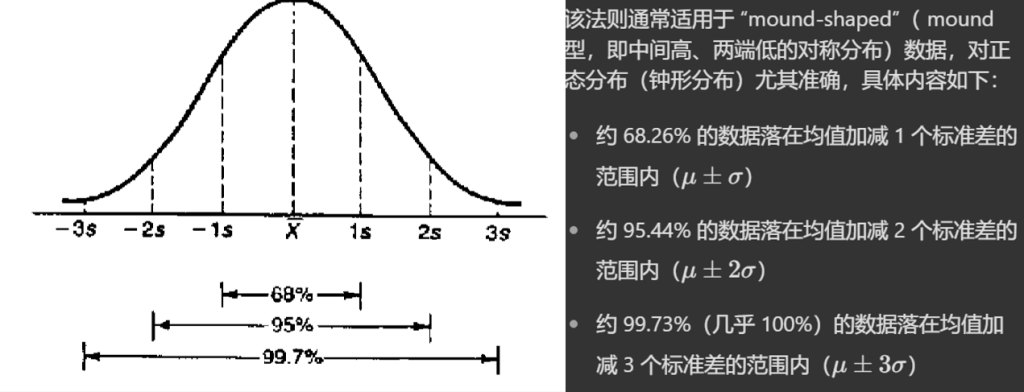
- 经验法则
The standard normal distribution 标准正态分布
标准正态分布\(N(0,1)\)是均值\(\mu = 0\)且方差\(\sigma^2 = 1\)的正态分布。标准正态随机变量\(Z \sim N(0,1)\)的概率密度函数为:
$$\phi(z) = \frac{1}{\sqrt{2\pi}} e^{-\frac{1}{2} z^2}, z \in \mathbb{R}$$
其累积分布函数为:
$$\Phi(z) = \mathbb{P}(Z \leq z) = \int_{-\infty}^{z} \phi(t) dt$$
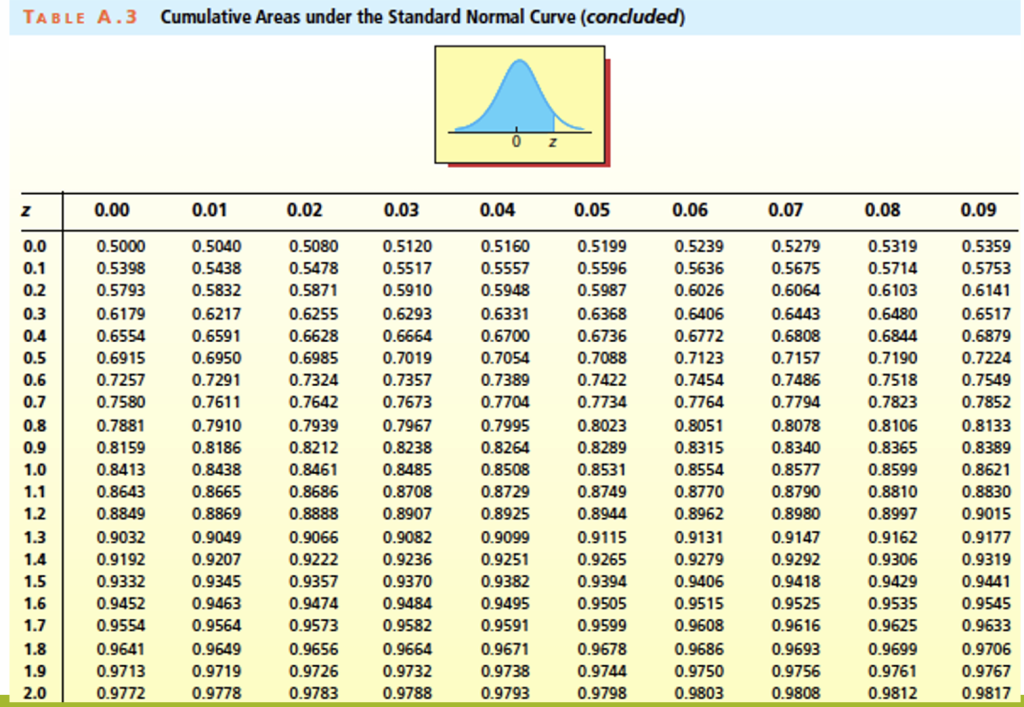
与其他连续随机变量一样,标准正态变量\(Z \sim N(0,1)\)在给定区间内的概率可通过对其概率密度函数在该区间上积分得到。这个计算过程比较困难,而正态随机变量在实际应用中又非常常见,因此统计学家将标准化正态分布的累积分布函数制成了表格(见表 2),用于查找正态曲线下给定区间的面积。该表中z对应的条目是标准正态曲线在z左侧的面积:
\(\Phi(z) = \int_{-\infty}^{z} \frac{1}{\sqrt{2\pi}} e^{-\frac{1}{2} x^2} dx\)
例题:正态分布的题目都要化成标准型

Integration of the normal distribution curve 正态分布曲线的积分 – Z值
设 X 为正态随机变量 \(X \sim N(\mu, \sigma^{2})\)。根据命题 1,随机变量 \(Z = \frac{X – \mu}{\sigma}\) 是标准正态随机变量 \(Z \sim N(0, 1)\),我们称其为 X 的标准化形式。通过这种方式,我们可以将每个正态分布与标准正态分布联系起来。事实上,如果 \(F_{X}(x)\) 是 \(X \sim N(\mu, \sigma^{2})\) 的累积分布函数,那么 \(F(z) = F(\frac{x – \mu}{\sigma})\) 就是标准正态分布的累积分布函数,可用于计算 X 在给定区间内的概率。换句话说,标准正态分布表可用于查找与任何正态分布相关的概率。
Z是标准正态曲线下水平轴上的点
注意,正态分布的参数是方差,但是标准化中减的是标准差
其次标准正态分布 \(Z \sim N(0,1)\) 是关于 \(Z = 0\) 对称的,所以有:
\(P(Z < -a) = P(Z > a)\)
然后再利用 \(P(Z < a) + P(Z > a) = 1\)将P(Z > a)表示为1- P(Z < a),P(Z < a)可以查表得到
可以看如下例题:注意到P(Z>-1)就是用上述思路最终转换为P(Z<1)的概率,查表得到0.841
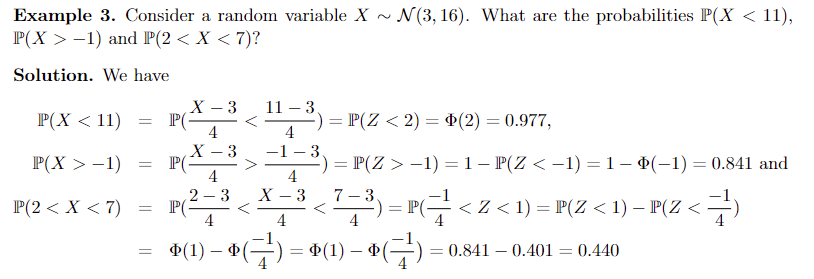
也可通过概率反向查表找到Z值的例题:

独立正态分布随机变量和的分布
之前正态分布说的是X变成kx+b,X的期望和方差怎么变
随机变量和又告诉我们如果有很多个这样的X加在一起期望和方差也相加即可


只给了每个西瓜自己的正态分布,而要求的是所有西瓜的正态分布

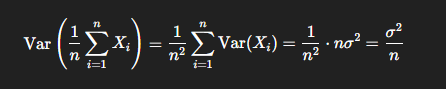
Central Limit Theorem中心极限定理
不管每个变量本身是不是正态分布,只要你抽够多的样本,它们的平均值分布都会接近正态分布!、
它还解释了一个重要现象:许多自然总体的经验频率呈现钟形曲线。



二项分布的正态近似
回顾伯努利试验 / 实验有两种结果:成功(概率 p)和失败(概率 \(1-p\))。参数为 p 的伯努利随机变量在成功时取值 1,否则取值 0,其期望和方差分别为 p 和 \(p(1-p)\)。




泊松分布的正态近似
不用近似时



a:泊松分布,当知道事件的平均发生率,即固定时间/距离间隔事件发生的次数固定。参数为每小时平均顾客数 6,即 \(Poisson(6)\)。
(b)同理,工作日8h到达的顾客数是固定的, X 服从泊松分布,参数为 8 小时平均顾客数 \(8 \times 6 = 48\),即 \(Poisson(48)\)

Joint Distribution 联合分布
用于表示多个随机变量各种结果组合的概率情况。要获取实际概率,需使用求和(离散型)或积分(连续型):
- 离散型:\(P(X=x, Y=y)\)
- 连续型:\(f_{X, Y}(x, y)\)\(P(a \leq X \leq b, c \leq Y \leq d)=\int_{c}^{d} \int_{a}^{b} f_{X, Y}(x, y) d x d y\)
\(\sum_{x} \sum_{y} P(X=x, Y=y)=1\)
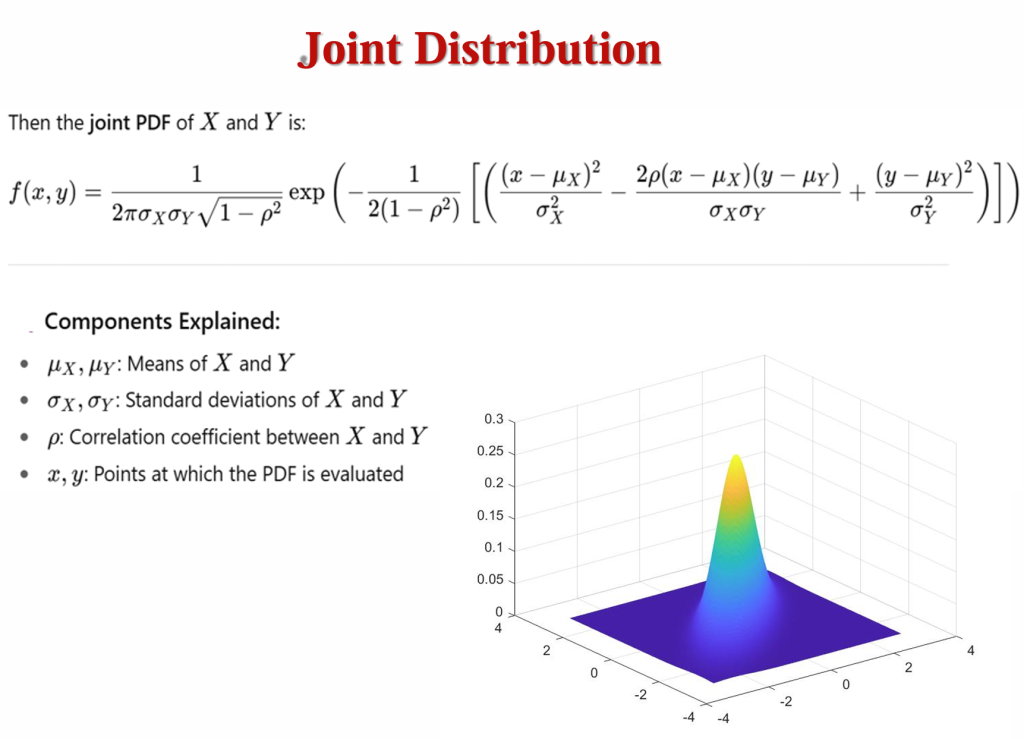
双变量正态分布
它是应用最广泛的分布,很多变量的联合分布都近似服从多元正态分布
\(\mathbf{X} \sim \mathcal{N}(\boldsymbol{\mu}, \Sigma)\) 表示随机向量 \(\mathbf{X}\) 服从均值向量为 \(\boldsymbol{\mu}\)、协方差矩阵为 \(\Sigma\) 的多元正态分布。多元正态分布由均值向量 \(\boldsymbol{\mu}\)和协方差矩阵 \(\Sigma\)** 定义
对于 d 维的随机向量 \(\mathbf{x}\),其概率密度函数为:
\(f(\mathbf{x}) = \frac{1}{(2\pi)^{d/2}|\Sigma|^{1/2}} \exp\left(-\frac{1}{2}(\mathbf{x} – \boldsymbol{\mu})^{\top} \Sigma^{-1} (\mathbf{x} – \boldsymbol{\mu})\right)\)
这个公式看起来复杂,核心是描述了随机向量 \(\mathbf{x}\) 取不同值时的概率密度大小。其中 \(|\Sigma|\) 是协方差矩阵 \(\Sigma\) 的行列式,\(\Sigma^{-1}\) 是协方差矩阵的逆矩阵,\((\mathbf{x} – \boldsymbol{\mu})^{\top}\) 是向量 \((\mathbf{x} – \boldsymbol{\mu})\) 的转置
当考虑两个连续随机变量 X 和 Y 时,它们的联合分布表示为 \((X, Y) \sim \mathcal{N}_2(\boldsymbol{\mu}, \Sigma)\),这里 \(\mathcal{N}_2\) 表示二维的正态分布
均值向量 \(\boldsymbol{\mu}\):
\(\boldsymbol{\mu} = \begin{bmatrix} \mu_X \\ \mu_Y \end{bmatrix}\)
其中 \(\mu_X\) 是随机变量 X 的均值,\(\mu_Y\) 是随机变量 Y 的均值。
协方差矩阵 \(\Sigma\):
\(\Sigma = \begin{bmatrix} \sigma_X^2 & \rho \sigma_X \sigma_Y \\ \rho \sigma_X \sigma_Y & \sigma_Y^2 \end{bmatrix}\)
这里 \(\sigma_X^2\) 是 X 的方差,\(\sigma_Y^2\) 是 Y 的方差,\(\rho\) 是 X 和 Y 的相关系数,\(\rho \sigma_X \sigma_Y\) 是 X 和 Y 的协方差
双变量正态分布描述了两个随机变量联合起来的分布情况,通过均值向量体现两个变量各自的平均水平,协方差矩阵体现两个变量的波动情况以及它们之间的线性关联程度,概率密度函数则能计算出两个变量取不同值组合时的概率密度
Marginal Distribution 边缘分布
由联合分布求边缘分布
当有多个随机变量(比如两个变量 X 和 Y 一起考虑时的联合分布),现在只关注其中一个变量的分布,这就是边缘分布,你会疑惑 “直接求单变量分布不就行了”,其实关键在于:很多时候,我们是先知道多个变量的联合情况(联合分布),再从中提取单个变量的分布
若要从联合分布中获取单个变量的分布,需对另一个变量进行求和(离散型)或积分(连续型):
离散型:
\(P(X=x)=\sum_{y} P(X=x, Y=y)\)
连续型:
\(f_{X}(x)=\int_{-\infty}^{\infty} f_{X, Y}(x, y) d y\)
“直接求单变量分布” 和 “从联合求边缘分布” 的区别
- 直接求单变量分布:适用于 “你已经能单独观察这个变量,不需要考虑其他变量” 的情况。比如,只关心 “抛一枚硬币(变量 X ,正面为 1,反面为 0)” 的概率,直接算 \(P(X=1)=\frac{1}{2}\) 、 \(P(X=0)=\frac{1}{2}\) 就行,不需要涉及其他变量。
- 从联合求边缘分布:适用于 “你先知道了多个变量的联合情况,现在要单独看其中一个” 的情况。比如,已经知道 “抛两枚硬币(X 是第一枚,Y 是第二枚)” 的联合概率(比如 \(P(X=1,Y=1)=\frac{1}{4}\) ,\(P(X=1,Y=0)=\frac{1}{4}\) 等),现在想单独看 “第一枚硬币 X 为 1 的概率”,这时候就要用边缘分布的方法:把 Y 所有可能的情况(\(Y=1\) 和 \(Y=0\))对应的联合概率加起来,即 \(P(X=1) = P(X=1,Y=1) + P(X=1,Y=0) = \frac{1}{4} + \frac{1}{4} = \frac{1}{2}\)。
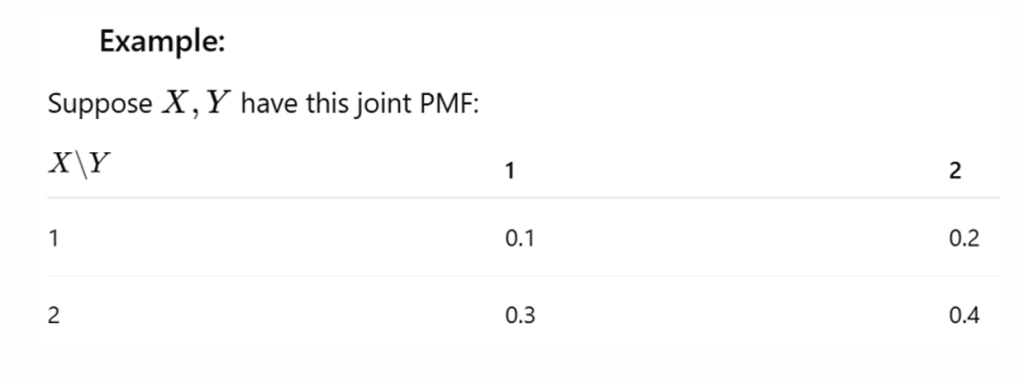
假设已知X和Y的联合概率表如下:
| \(Y=0\) | \(Y=1\) | |
|---|---|---|
| \(X=0\) | 0.1 | 0.2 |
| \(X=1\) | 0.3 | 0.4 |
X的边缘分布:
计算\(P(X=0)\),需对所有Y的取值概率求和:
\(P(X = 0) = P(X = 0, Y = 0) + P(X = 0, Y = 1) = 0.1 + 0.2 = 0.3\)
\(P(X = 1) = 0.3 + 0.4 = 0.7\)
因此,X的边缘分布为:
\(P(X=1)=0.7\)
\(P(X=0)=0.3\)
例2:
已知联合概率密度函数:
\(f_{X, Y}(x, y)=6xy \quad (0 \leq x \leq 1, 0 \leq y \leq 1)\)
求X的边缘概率密度函数:
\(f_{X}(x)=\int_{0}^{1} 6xy dy=6x \int_{0}^{1} y dy=6x \cdot\left[\frac{y^{2}}{2}\right]_{0}^{1}=6x \cdot \frac{1}{2}=3x\)
因此:
\(f_{X}(x)=3x \quad (0 \leq x \leq 1)\)
同理,对x积分可求得Y的边缘概率密度函数:
\(f_{Y}(y)=\int_{0}^{1} 6xy dx=3y\)
Conditional Distribution 条件分布
条件分布描述了在已知一个变量取值的情况下,另一个变量的概率分布
离散型变量
对于两个离散型随机变量X和Y,在\(Y=y\)条件下,X的条件概率质量函数为:
\(P(X=x | Y=y)=\frac{P(X=x, Y=y)}{P(Y=y)}\)
连续型变量
对于联合概率密度函数\(f_{X, Y}(x, y)\),在\(Y=y\)条件下,X的条件概率密度函数为:
\(f_{X | Y}(x | y)=\frac{f_{X, Y}(x, y)}{f_{Y}(y)}\)
条件分布示例 1:离散型


\(f_{X,Y}(x,y)\) 表示二维随机变量 \((X,Y)\) 的联合概率密度函数。
Covariance 方差 协方差 相关系数


\(E(XY)\) 和 \(E(X)\) 的计算方式没有本质不同,只是从对所有 X 的值乘以权重求和,变成对所有 XY 的值乘以权重求和

Sampling Distribution 抽样分布
抽样分布是指某种样本统计量(如均值 X̄、比例 p、方差 S²)在重复抽样过程中的概率分布
样本均值的抽样分布
- 总体:假设全国成年男性身高服从分布,其均值 μ = 175 cm,标准差 σ = 10 cm。
- 抽样行动:我们不是只抽一次,而是重复进行以下操作:
- 随机抽取 n=100 名男性,计算他们的平均身高 X̄₁。
- 把这100人放回去,再随机抽100人,计算平均身高 X̄₂。
- 重复这个过程成千上万次,我们会得到一长串的样本均值:X̄₁, X̄₂, X̄₃, …
现在,我们来看这些成千上万个 X̄ 组成的分布,它就是“样本均值的抽样分布”
既然是样本均值,我们要区分,样本和他们样本的均值
样本本身可能满足某种分布比如二项分布,因此E(X)期望和方差可以套公式
结合均值后\(E(\bar{X})\)计算方差和期望要用如下公式,但可以看到如果X服从某些分布还是可以套公式,只是要考虑n的问题,下面有例题涉及到该注意事项


解释为什么样本均值的期望是miu:
为什么会出现这种 “单个与整体(均值)期望相等” 的情况?期望的定义是对某随机变量加权求和,期望是随机变量集合的性质,这个集合中的任何元素也同样有该性质。E(x1) = E(x)
那现在只需要计算E(x),因为每个人被抽到的概率是相等的,所以就是等概率求和,即平均值miu
样本比例的抽样分布
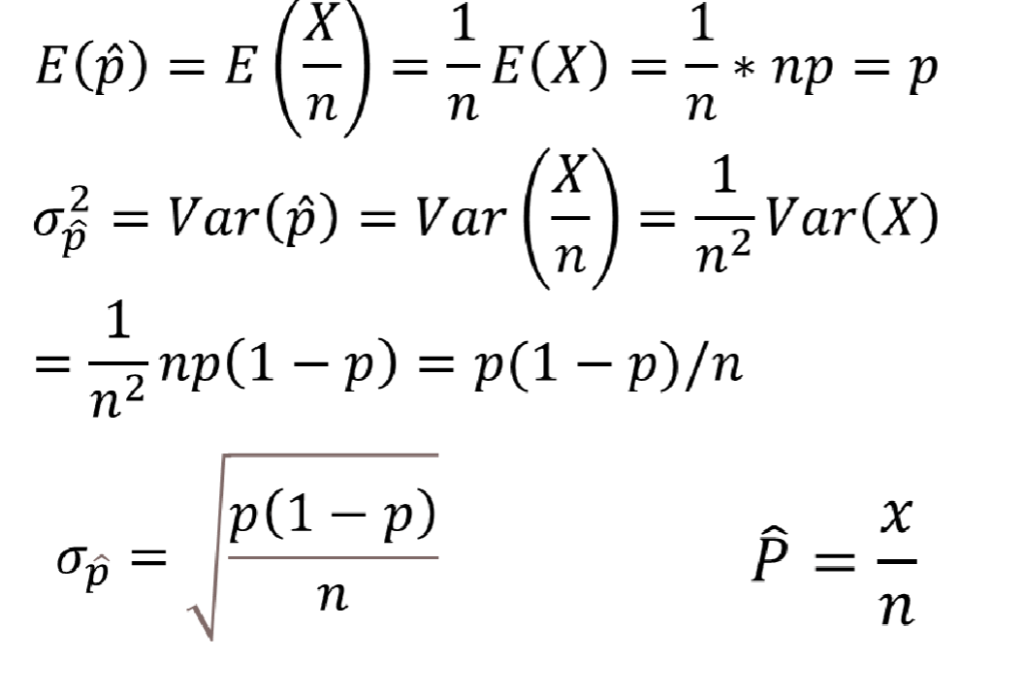
- 样本均值和样本比例均为随机变量
- 当样本量足够大时,样本均值和样本比例可能服从正态分布
中心极限定理
无论总体分布形态如何,当样本量 n>30时,样本均值的抽样分布近似服从正态分布。
当样本量 n 足够大(满足条件np≥5且n(1−p)≥5)时,样本比例p^的抽样分布近似服从正态分布。
某瓶装饮料厂的工头观察到,每瓶 “32 盎司(约 0.91 升)” 可乐的实际容量服从正态分布,均值为 32.2 盎司,标准差为 0.3 盎司。
问题:
(1)若一位顾客购买 1 瓶可乐,该瓶内饮料量超过 32 盎司的概率是多少?
(2)若一位顾客购买 1 箱(4 瓶)可乐,这 4 瓶饮料的平均量超过 32 盎司的概率是多少?


示例:火腿酱包装设计问题
某食品加工公司研发了一种新型火腿酱出料口,该设计可能降低生产成本。若当前购买者中不接受该设计的比例低于 10%,公司将采用这种新型设计。随机选取 1000 名当前购买者进行调查,其中 63 人表示若使用新型出料口,将不再购买该火腿酱。因此,样本比例p^=63/1000=0.063。
为评估该证据的说服力,需计算:若总体不接受比例p=0.1,观察到样本量为 1000、样本比例p^≦0.063的概率是多少?


正态分布一般第二个参数是方差而不是标准差,这里的写法少见,计算正态分布时候的Z,用的是标准差
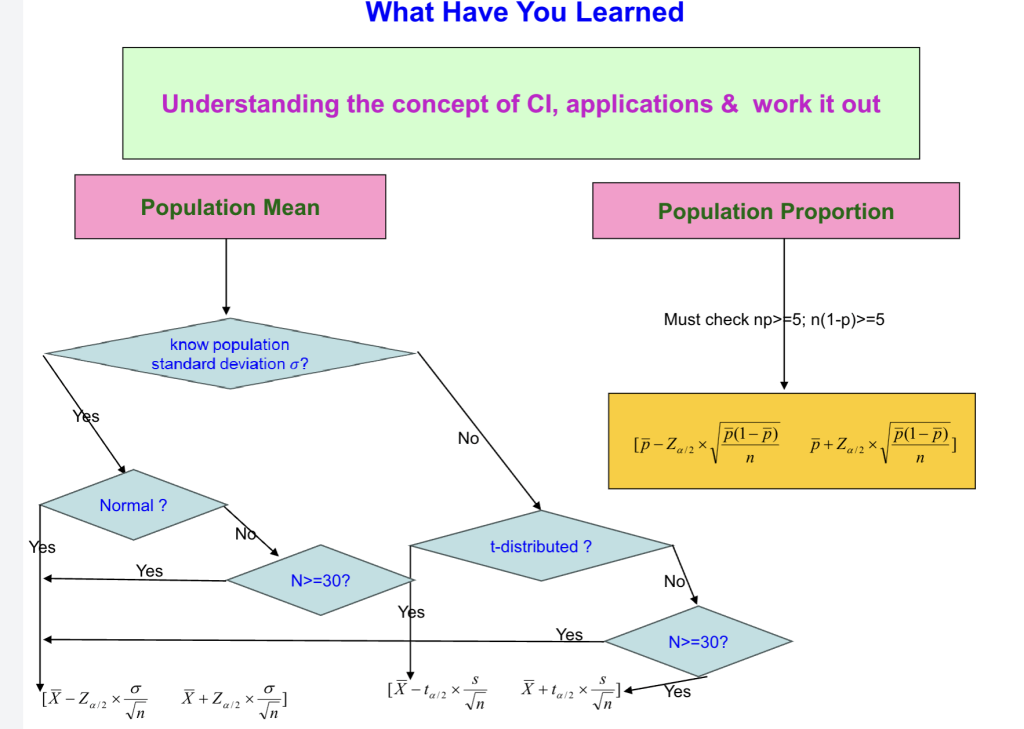
Confidence Intervals 置信区间
置信区间,置信水平定义:置信区间Confidence Interval是根据样本数据计算出的一个区间估计,用于提供一个总体参数(如均值、比例)可能存在的范围[下限, 上限],并附带一个置信水平Confidence Level(1 - α),通常是 90%, 95%, 或 99%。来说明这个区间的可靠性

对“95%置信水平”的正确理解:
如果我们用同样的方法重复抽取无数个样本,并为每个样本构建一个95%置信区间,那么这些区间中大约有95%会包含真实的总体参数
不能说“真实参数有95%的概率落在这个具体的区间里”。因为参数是固定的、未知的常数,而区间是由样本计算出来的。对于一个计算好的区间,它要么包含真值,要么不包含,不存在概率问题。概率描述的是构建区间的方法的长期成功率。
符号说明
Z / α
α 显著性水平:所能容忍的其中一种错误的界限
一个 (1 – α)% 的置信区间(例如,95%置信区间对应 α=0.05),其含义是:
如果我们用同样的方法重复抽样成百上千次,并为每个样本构建一个(1-α)%的置信区间,那么其中大约有(1-α)%的区间会包含真实的总体参数,而另外 α% 的区间则会错误地错过真实的总体参数
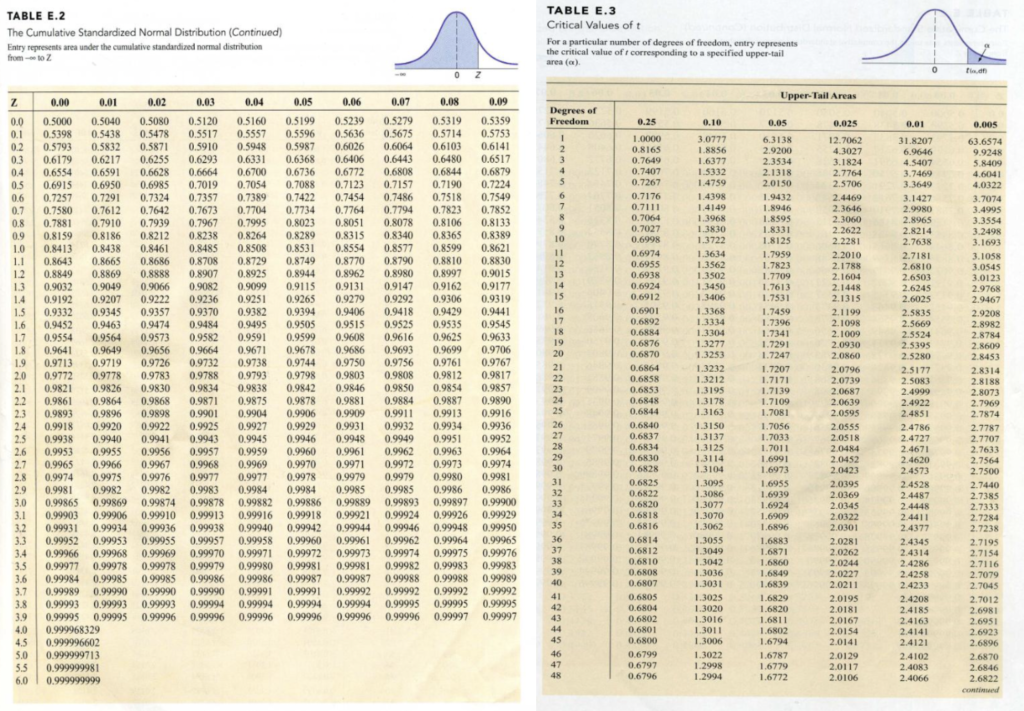
Z

标准正态分布表(Z表)通常给出的是从 -∞ 到某个z值 的累积面积,即 P(Z ≤ z)。
如果右侧尾部面积是 0.025,那么从 -∞ 到 0.025 的面积就是 1 – 0.025 = 0.975
因此要在表中找0.975对应的数据
| 指标类型 | 总体参数(无偏真值) | 样本统计量(估计值) | 样本统计量的符号逻辑 |
|---|---|---|---|
| 均值 / 比例(平均类) | 总体均值\(\mu\)、总体比例p | 样本均值\(\bar{X}\)、样本比例\(\bar{p}\) | 用 “横线(\(\bar{\cdot}\))” 体现 “平均” |
| 离散程度(偏差类) | 总体标准差\(\sigma\)、总体方差\(\sigma^2\) | 样本标准差s、样本方差\(s^2\) | 用 “小写英文字母s” 区分总体的 “小写希腊字母\(\sigma\)” |
无横线参数:通常表示总体参数,是描述总体特征的概括性数字度量,反映了总体的真实情况。
有横线参数:一般表示样本统计量,是根据从总体中抽取的样本数据计算得出的量。用来估计总体参数的指标,下面的写法方便记忆:

σ=0.8 (总体标准差):总体中单个数据点与总体均值 μ的平均偏离有多大
\(\sigma_{\bar{x}} = 0.3577\)(均值的标准误):如果我们反复抽样,计算出的不同样本均值 \(\bar{x}_1, \bar{x}_2, \dots\) 与总体均值 \(\mu\) 的平均偏离有多大
经验法则(68-95-99.7 法则)
总体与样本的核心统计量
- 约 68.26% 的样本均值落在总体均值的 1 个标准差范围内;
- 约 95.44% 的样本均值落在总体均值的 2 个标准差范围内;
- 约 99.73% 的样本均值落在总体均值的 3 个标准差范围内。
总体参数是描述总体真实特征的固定数值
\( t = \frac{\bar{x} – \mu}{s / \sqrt{n}} \) ; \( Z = \frac{\bar{x} – \mu}{\sigma / \sqrt{n}} \)
用样本标准差 s 来代替未知的总体标准差 σ。
\(\sigma = 0.8\),\(\mu\) 未知且待估计,\(n = 5\);
\(\sigma_{\bar{x}} = \frac{\sigma}{\sqrt{n}} = \frac{0.8}{\sqrt{5}} = 0.3577\)
然后,有 \(0.9544\) 的概率,\(\bar{x}\) 会是这样一个值,使得区间 \([\bar{x} \pm 0.7115]\) 包含 \(\mu\)。
区间 \([\bar{x} \pm 0.7115]\) 被称为 \(\mu\) 的 \(95.44\%\) 置信区间。
\(0.7115\) 是用 \(\bar{x}\) 估计 \(\mu\) 时的误差幅度。
我们可以把\(\bar{X}\)想象成 “样本的平均情况”,\(\bar{p}\)想象成 “样本里符合某类情况的比例”。
在这个例子里,我们要研究的是 “客户对产品极其满意的比例”。那怎么得到这个比例呢?我们从所有客户(总体)里抽了一部分客户(样本),去看这部分样本里有多少人极其满意。
\(\bar{X}\)在这里代表的是,从样本角度看 “极其满意” 这个情况的平均表现。而\(\bar{p}\)是样本里极其满意的人数占样本总人数的比例。因为我们研究的就是 “极其满意” 的比例,所以从样本层面来说,这个比例的平均情况就等于这个比例本身,也就是\(\bar{X}=\bar{p}\)。
简单讲,就是我们要算的 “比例”,在样本里的平均结果就是这个 “比例” 自己。
Sample Size Determination

如果样本量 n 较大 *,那么总体比例 p 的 \((1 – \alpha)100\%\) 置信区间为:
\(\hat{p} \pm z_{\alpha/2} \sqrt{\frac{\hat{p}(1 – \hat{p})}{n}}\)
注意:必须同时满足以下两个条件时,上述方法才适用:
\(n \cdot \hat{p} \geq 5 \quad \text{且} \quad n \cdot (1 – \hat{p}) \geq 5\)
总体均值和总体比例的置信区间不同情况下的公式总结

答案
设随机变量 表示期中考试分数,。
(1) 求进入前 10% 所需的最低分数要找到 使得 ,即 。