字典,队列,列表
| 维度 | 字典 Dictionary<TKey,TValue> | 队列 Queue<T> |
|---|---|---|
| 核心模型 | 键值映射(哈希表) | 线性序列(环形缓冲/FIFO) |
| 访问方式 | 通过 Key 直接定位到 Value | 只能访问队首元素(Peek/Dequeue) |
| 顺序 | 不保证迭代顺序(不要依赖) | 严格 FIFO |
| 唯一性 | Key 必须唯一;Value 可重复 | 元素可重复 |
| 典型操作 | Add/Remove/TryGetValue/ContainsKey | Enqueue/Dequeue/Peek/Count |
| 复杂度(均摊) | 查/增/删 ≈ O(1)(哈希) | 入队/出队 ≈ O(1) |
| 适用场景 | 根据 ID/名称快速定位对象,状态表、缓存、索引 | 按到达顺序排队处理任务/事件/消息 |
| 线程安全版本 | ConcurrentDictionary<TKey,TValue> | ConcurrentQueue<T> |
| 典型错误用法 | 依赖遍历顺序;Key 可变 | 需要随机访问中间元素 |
有“标识符/键”并需秒查 → 用字典(例如 玩家ID→玩家对象、tid→任务)
只需按“到达顺序”依次处理 → 用队列(例如 日志、网络包、回调投递、工作队列)。
List<T> 是通用“动态数组”,擅长随机索引与遍历;Queue<T> 是**先进先出(FIFO)**容器,专为“到达顺序依次处理”设计
| 维度 | List | Queue |
|---|---|---|
| 抽象语义 | 有序序列(不限定出入规则) | 严格 FIFO 队列 |
| 典型操作 | Add, Insert, RemoveAt, [] | Enqueue, Dequeue, Peek |
| 随机访问 | O(1):list[i] | 不支持随机索引(需出队/窥视头部) |
| 头部出队成本 | O(n):RemoveAt(0) 需要整体搬移 | O(1):环形缓冲,仅移动头指针 |
| 尾部入队成本 | O(1) 摊还:Add | O(1):Enqueue |
| 中间插入/删除 | O(n) | 不支持 |
| 线程安全变体 | 无并发版(需自己加锁) | 有 ConcurrentQueue<T>(生产者-消费者常用) |
| 语义可读性 | 容器用途不明显 | 一眼看出“排队/依次处理” |
List 列表(链表)存储和操作有序数据,能够简单的添加,删除或重序
Arrays 数组:适合集合的大小已知或不经常改变
Stacks 栈 :last-in,first out,后进先出,如存储编辑器撤销和重做操作,可以轻松的回到上一个状态
queues 队列:first in,first out,先进先出,适合发送事件,消息,用户操作 – 按接收顺序存储收到的信息,接着按接收顺序处理事件,打印作业
heaps 堆:一般用于任务调度和内存管理,尤其有助于实现优先级队列priority queues,便于访问最高或最低优先级的项目
Trees 树:以分层的方式组织数据,用以表示具有自然层级 / 关联关系,如B树常用于关系型数据库,其他AI决策系统、文件系统
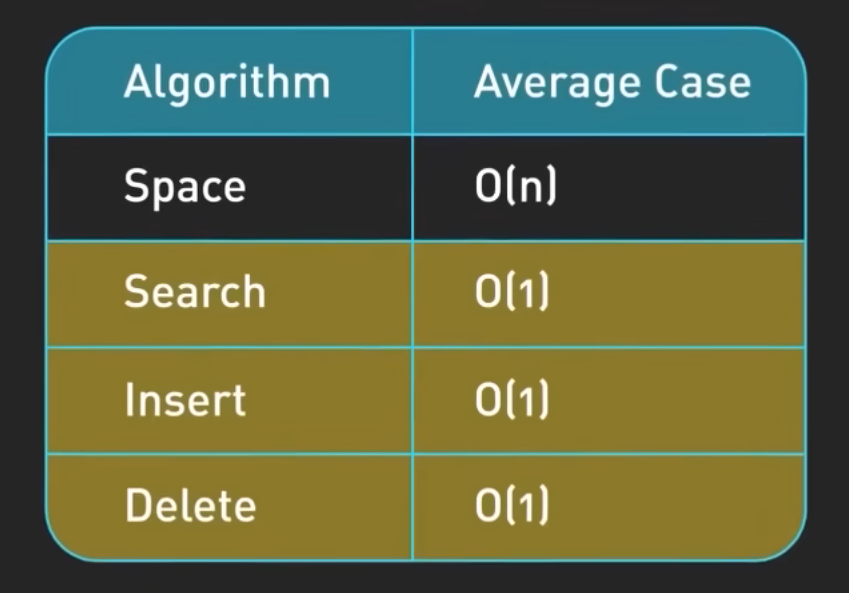
Hash tables 哈希表:能够高效的数据查找,插入和删除。通常使用哈希函数将key和value即某个存储位置对应,常用于搜索引擎,缓存系统,以及编程语言的Interpretor or compilers,快速访问经常使用的资源
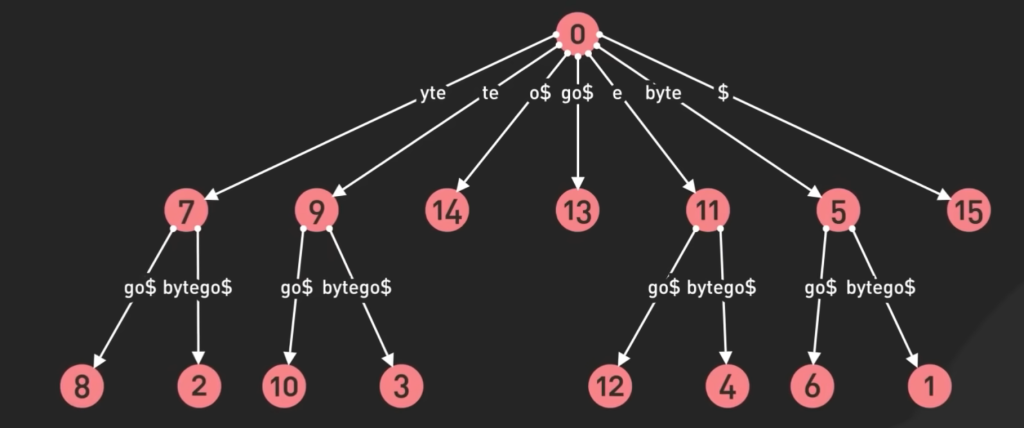
suffix tree 后缀树:specialized for searching strings in documents,this makes them perfect for text editor and search algorithms. In search engine, a suffix tree can be used to efficiently locate all occurrences of a search term within a large corpus of text.
Graph 图:用于追踪关系和寻找路径。常用于推荐引擎和 pathfinding algorithms,可以用于表示用户之间的连接
R tree:擅长查找最近邻,存储位置信息后可高效的查找用户当前最近的地理位置
数组在内存中是连续存储,所以内存的访问效率相比List的非连续存储会更容易命中,因此使用数组性能更好





