What is Bert?
BERT 利用基于Transformer 的神经网络来理解和生成类似人类的语言
旨在通过在所有层中对左右上下文进行联合条件反射,从未标记的文本中预训练深度双向表示。因此,预训练的BERT模型可以通过一个额外的输出层进行微调,从而为广泛的任务(如问答和语言推理)创建最先进的模型,而无需对特定于任务的架构进行大量修改
BERT 采用仅编码器的架构。在原始 Transformer 架构中,既有编码器模块,也有解码器模块。在 BERT 中使用仅编码器架构的决定表明主要强调理解输入序列而不是生成输出序列
论文及开源资源
BERT 的原始论文是《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》。
论文地址:
https://arxiv.org/abs/1810.04805
GitHub 项目地址:
GitHub – google-research/bert: TensorFlow code and pre-trained models for BERT
Google AI Blog :
Open Sourcing BERT:State-of-the-Art Pre-training for Natural Language Processing
地址:
https://link.zhihu.com/?target=https%3A//ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
Bert的优势
与传统的单向语言模型相比,BERT 的核心优势在于:
- 双向性:BERT 能够同时从文本的左右两个方向学习上下文信息,而不是按顺序分析文本,使模型能够更好地理解句子中的每个词的语义。能精准捕捉信访文本中复杂的语义表述、领域专业术语,解决传统单向模型词义理解偏差问题;
- 良好的可扩展性:可通过添加CRF层、注意力机制、调整预训练策略等方式进行轻量化优化,无需大规模重构模型
例如:“The bank is situated on the _ of the river.”
在单向模型中,对空白的理解将严重依赖于前面的单词,并且模型可能难以辨别“bank”是指银行还是河的一侧,BERT 是双向的,它同时考虑左侧(“The bank is situated on the”)和右侧上下文(“of the river”),从而实现更细致的理解
BERT的架构
BERT 整体可以分成三块:
- 输入表示层(Embeddings)
- 多层 Transformer 编码器(Encoder Stack)
- 任务输出层(Task Head)
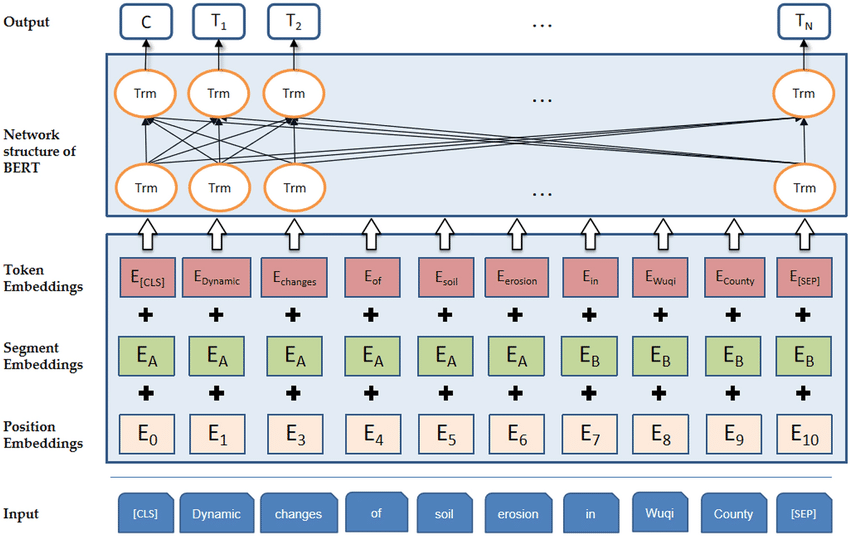
输入表示层(Embeddings)
在输入到模型之前,这些文本需要经过特定的预处理步骤
BERT 的输入不是单纯的词向量,而是 三种嵌入相加:
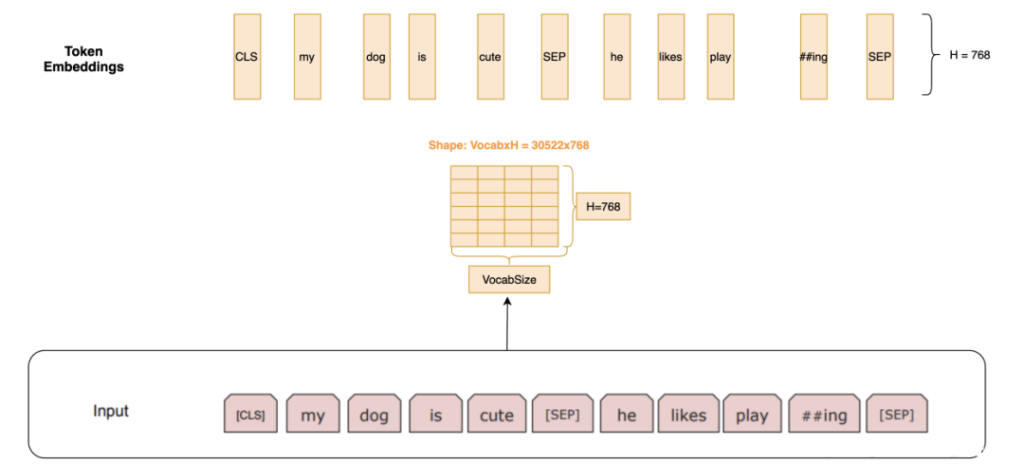
Token Embedding
BERT 会先用 WordPiece 把文本分成 token 序列。
每个 token 会通过一个“嵌入矩阵”(可理解为词向量表)映射成固定长度的高维向量,得到 Token Embeddings。
这些向量自带一定的语义信息,为后续理解上下文打基础。
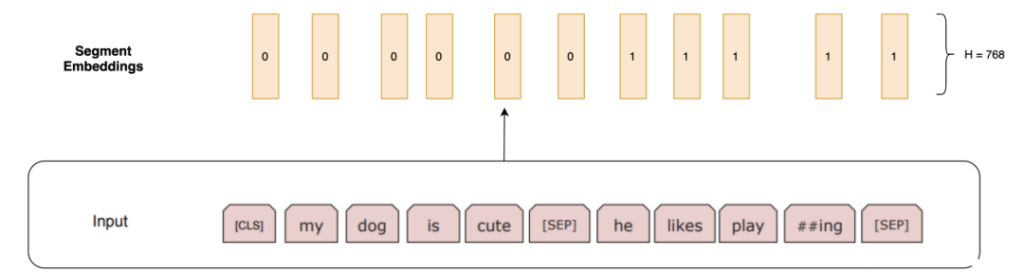
Segment Embeddings:
BERT 有时候会把“两段文本”拼在一起输入,所以需要Segment Embedding告诉模型:这个 token 来自第一段(A)还是第二段(B)
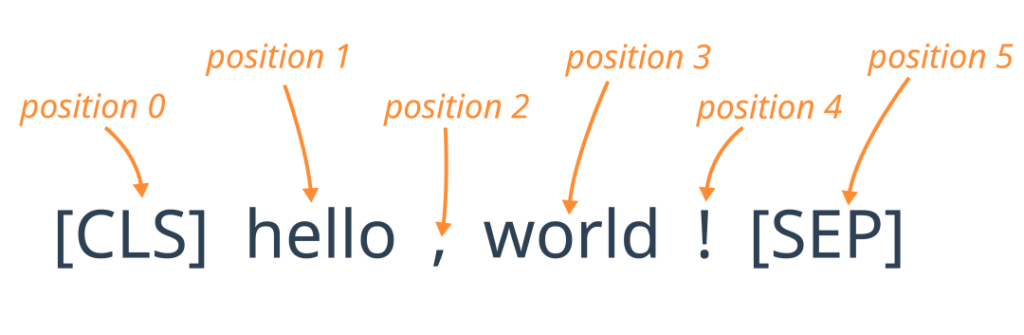
Position Embeddings:
由于Transformer模型本身不具有处理序列中Token位置信息的能力,因此需要位置嵌入来提供这一信息。每个位置都有一个独特的嵌入向量,这些向量在训练过程中学习得到。
Token Embeddings、Segment Embeddings和Position Embeddings三者相加,得到每个Token的最终输入嵌入。
输出层架构 (Output)
在多数情况下,BERT 模型会根据具体的下游任务添加一个输出层。例如
- 在文本分类任务中,输出层可能是一个简单的 softmax 分类器,用于预测输入文本的类别
- 在问答任务中,输出层可能是一个生成起始和结束位置的 softmax 分类器。
- 在命名实体识别(Named Entity Recognition)等序列标注任务中,输出层通常采用条件随机场(CRF)等模型结构。这一层的目的是将 BERT 编码器的输出映射到特定任务的输出空间,并且根据任务的不同进行适当的损失计算和参数优化
BERT训练 – 预训练 微调
BERT的工作原理是通过在大规模未标注数据上执行预训练任务(如Masked Language Model来捕获文本中词汇的双向上下文关系,以及Next Sentence Prediction来理解句子间的逻辑关系),再将预训练的模型针对特定任务进行Fine tuning,从而在各种自然语言处理任务中实现高性能
BERT 的训练分为两个阶段:预训练和微调。
预训练
预训练阶段,BERT 使用两个任务来学习语言表示:
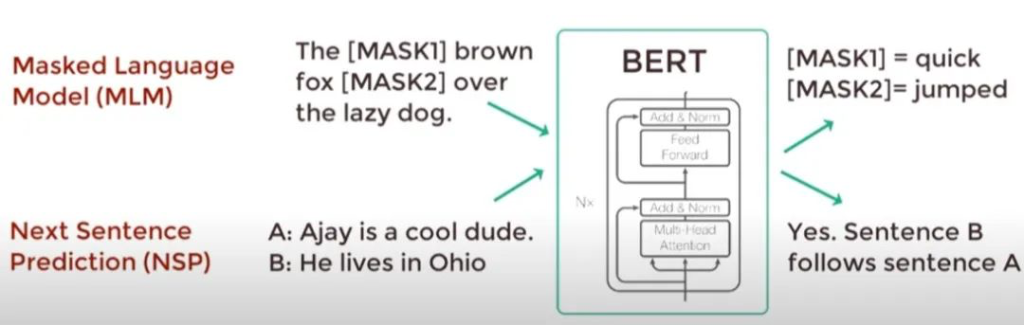
Masked Language Model (MLM)和Next Sentence Prediction (NSP)
传统 LM(尤其 RNN 类)预测当前词时 只能用左边已出现的词,ELMo 虽说双向,但本质是 左到右 LM + 右到左 LM 两个单向模型拼接,不是“在同一个模型里同时融合左右信息”。
那么如何同时利用好前面的词和后面的词的语义呢,提出 Masked Language Model
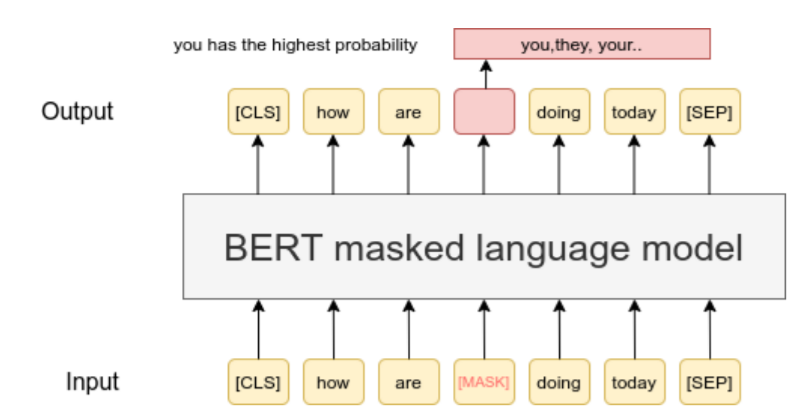
Masked Language Model (MLM)
- BERT 随机把句子里一部分 token 遮住(mask),让模型利用 左+右 的上下文去猜被遮住的词。
- 训练目标:调整参数,让猜中的概率尽可能大。
- 直觉类比:像做英语完形填空,通过上下文推断空缺词,学到更完整的语义与语法关系。
实现方式:在预训练阶段,BERT随机选择文本中15%的Token进行遮盖,其中80%的时间用[MASK]标记替换,10%的时间用随机词汇替换,剩下的10%保持不变。这种遮盖策略被称为动态遮盖,因为它在每次输入时都会随机改变遮盖的位置和词汇
为什么不总用 [MASK]?
如果训练时每次都把目标词直接替换成 [MASK],模型就会在预训练阶段过度“习惯”这种特殊符号,但在下游微调或真实使用时输入里通常不会出现 [MASK],从而造成预训练与微调之间的分布不一致;为了解决这个问题,BERT 对被选中的 15% 目标 token 采用混合替换策略:其中 80% 替换为 [MASK],10% 替换为随机 token,另外 10% 保持原样不变但仍要求模型预测原词,这样可以减少模型对 [MASK] 的依赖,同时让训练过程更贴近真实输入分布
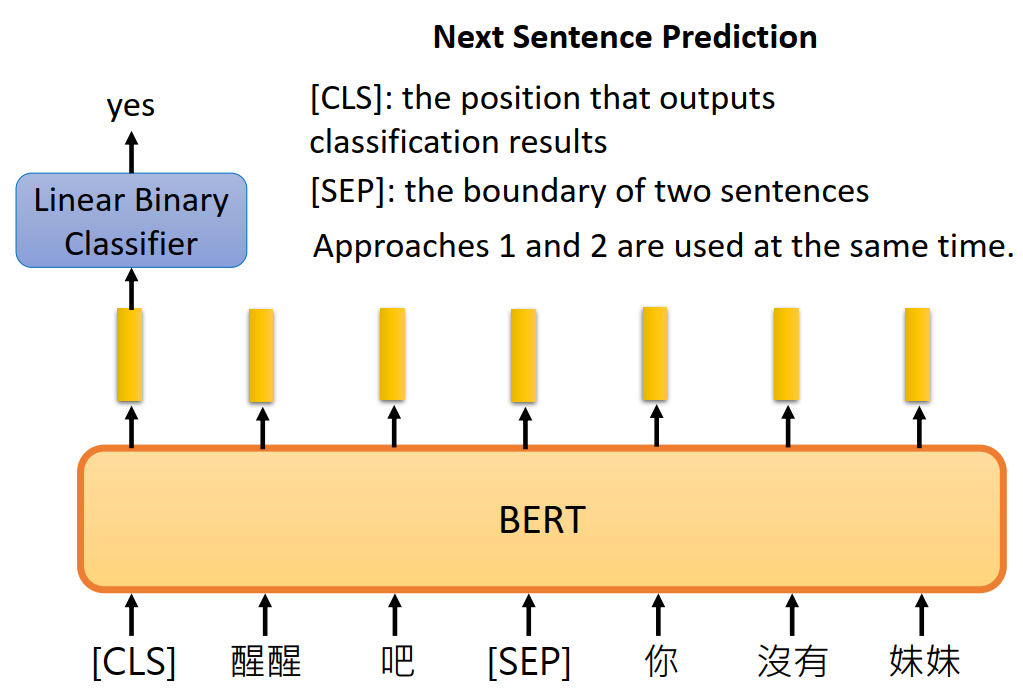
Next Sentence Prediction (NSP)
任务描述:给定一对句子,判断第二个句子是否是第一个句子的后续句子
目的:使模型能够理解句子间的逻辑关系,如连贯性、因果关系等,从而提高其在处理长文档或复杂文本时的能力。
实现方式:在预训练阶段,BERT构造了一个二分类任务,其中50%的时间B是A的真正后续句子(标签为“IsNext”),另外50%的时间B是从语料库中随机选择的句子(标签为“NotNext”)。模型通过最后一层Transformer输出的[CLS]标记的嵌入来进行预测。
预训练完成后,BERT 可以快速适应下游任务。在微调阶段,我们只需要为特定任务添加相应的输出层,然后在该任务的数据集上进行训练。得益于预训练的丰富表示,微调通常需要的训练数据量较少,效果却非常显著
应用领域:文本摘要
文本摘要有两种类型,一种是生成式的(Abstractive Summarization),输入是较长的原始文档,输出的内容不局限于在原文出现的句子,而是自主生成能够体现文章主要思想的较短的摘要;另外一种是抽取式的(Extractive Summarization),意思是从原始文档中选择部分能够体现主题思想的句子,摘要是由文中抽出的几个原始句子构成的
生成式文本摘要
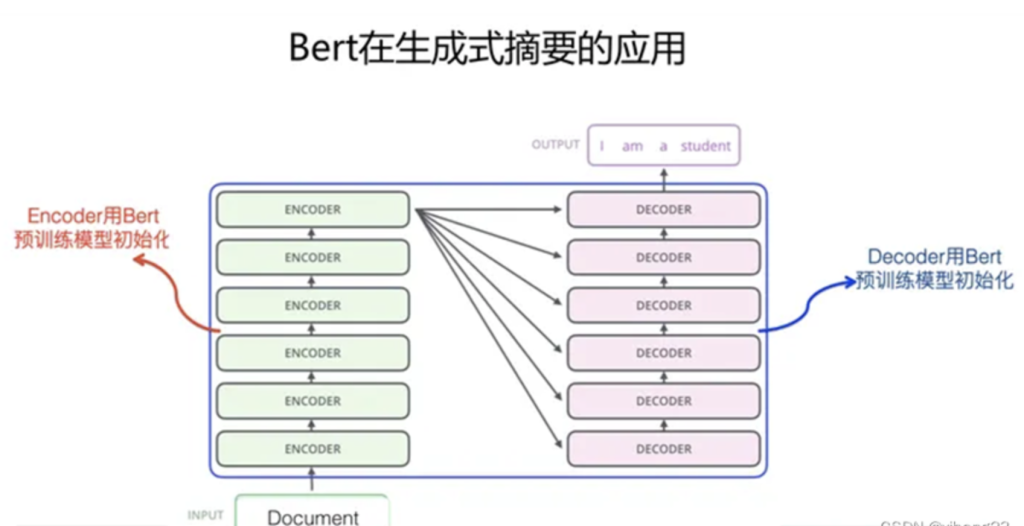
生成式摘要任务通常遵循Encoder-Decoder架构:文章首先由Encoder处理,随后Decoder生成摘要。在利用BERT的预训练模型进行此任务时,主要的应用方式有两种:一是在Encoder端,通过使用BERT预训练模型初始化Transformer参数;二是在Decoder端,尽管理论上可以利用BERT的预训练参数来初始化,但实验结果表明这一方法并不理想。原因在于BERT的预训练是基于双向语言模型进行的,而在Decoder阶段的文本生成任务中,生成过程通常是单向的,即从左到右逐个单词生成。这种单向生成过程与BERT的双向训练模式不兼容,导致BERT在预训练阶段获得的下文信息提示在Decoder端无法得到有效利用,从而限制了BERT预训练模型在Decoder端的应用效果
抽取式文本摘要
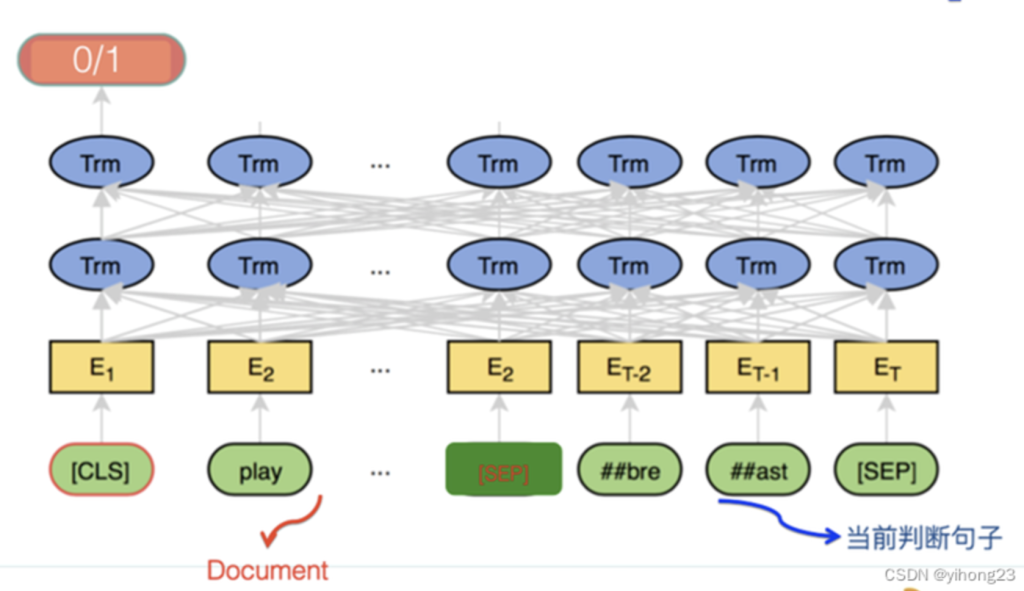
抽取式文本摘要则是个典型的句子分类问题。意思是模型输入文章整体的文本内容,给定文中某个指定的句子,模型需要做个二分类任务,来判断这个句子是不是应该作为本文的摘要。所以,抽取式文本摘要本质上是个句子分类任务,但是与常规文本分类任务相比,它有自己独特的特点,这个特点是:输入端需要输入整个文章内容,而分类的判断对象仅仅是当前要做判断的某个句子,整个文章只是对当前句子进行判断的一个上下文,但是又必须输入。而一般的文本或者句子分类,输入的整体就是判断对象,不存在多出来的这个上下文的问题。这是它和普通的文本分类任务的最主要区别。
所以说,对于抽取式文本摘要任务,尽管可以把它看成个句子分类任务,但是它的输入内容和输出对象不太匹配,这个是关键差异。于是,在模型输入部分如何表达这种句子和文章的隶属关系方面,需要花些心思。
如果要用Bert做抽取式摘要,也就是用Transformer作为特征抽取器,并用Bert的预训练模型初始化Transformer参数,以这种方式构建一个句子的二分类任务。从模型角度,Bert肯定是可以支持做这个事情的,只需要用Bert的预训练模型初始化Transformer参数即可。问题的关键是:如何设计并构建Transformer的输入部分?要求是:输入部分同时要输入文章整体的内容,并指出当前要判断的句子是哪个句子。所以,这里的关键是Transformer模型的输入和输出如何构造的问题,而模型本身应用Bert成果则没什么问题,算是一种常规的Bert应用
BERT 文本分类(SST-2)实操笔记
目标
用 Google 的 BERT 预训练模型 bert-base-uncased(从 Hugging Face 模型库下载),在 SST-2 情感分类数据上做一次微调训练,保存模型,并写脚本对新句子做预测
环境搭建(Windows + Anaconda + NVIDIA GPU)
在Anaconda Prompt中
conda create -n hf_bert_cls python=3.10 -y
conda activate hf_bert_cls
//安装 PyTorch
//安装 transformers 到当前环境
pip install -U pip
pip install -e .
//安装示例依赖
pip install -r examples\pytorch\text-classification\requirements.txt训练(官方 SST-2 情感二分类)
我做了训练,但只是BERT 的微调训练:在预训练模型已有语言理解能力的基础上,用少量标注数据把它适配成情感分类器,而不是从零训练一个全新的 BERT
预训练(Pretraining)
- 目标:让模型先学会通用的语言理解能力(词怎么搭配、句子怎么连贯、上下文语义是什么)。
- 数据:通常是海量无标注文本(不需要你给“正/负面”这种标签)。
- 结果:得到一个“会语言”的模型,比如 bert-base-uncased。
微调(Fine-tuning)
- 目标:让这个“会语言”的模型,学会一个具体任务(比如情感分类、垃圾邮件、意图识别)。
- 数据:需要有标签的数据(你这次 SST-2 就是情感标签)。
- 结果:得到一个“会做某个任务”的模型(你现在保存的 out_sst2)。
BERT 是一个“读懂文本”的模型(Encoder-only Transformer)。它预训练时主要做一种核心任务:
//进入仓库根目录
cd /d "D:\ext classification\transformers-main"
//运行训练命令
python examples\pytorch\text-classification\run_glue.py ^
--model_name_or_path bert-base-uncased ^
--task_name sst2 ^
--do_train --do_eval ^
--max_seq_length 128 ^
--per_device_train_batch_size 16 ^
--learning_rate 2e-5 ^
--num_train_epochs 1 ^
--fp16 ^
--output_dir .\out_sst2 ^
--max_train_samples 2000 ^
--max_eval_samples 500训练过程,具体来说为以下步骤:
- 自动下载 SST-2 数据集并缓存到用户目录
- 下载 bert-base-uncased 模型权重
- 对文本做分词编码(tokenizer)
- 在训练集上训练一轮(你限制了 2000 条)
- 保存模型到 out_sst2
- 在验证集上评估(你限制了 500 条),输出 accuracy
推理脚本并预测(predict.py)
Predict.py
from transformers import pipeline
clf = pipeline(
"text-classification",
model=r".\out_sst2",
tokenizer=r".\out_sst2",
device=0
)
//要判断的文本
print(clf("This movie is amazing!"))
print(clf("This movie is horrible."))输出形式为:
[{'label': 'LABEL_1', 'score': 0.94}]- LABEL_1 / LABEL_0:两类(正面/负面,SST-2 是情感二分类)
- score:模型对该判断的置信度(越接近 1 越确定)





