基础查询
单表简单查询
5.1查询指定字段 WHERE
SELECT 字段1, 字段2, ..., 字段n
FROM 表名
[WHERE 条件]; -- 可选:筛选符合条件的记录
USE lib;
//在书目表(tb_bibliography)中,查询全部图书的图书名称和作者名,即显示 name 和 author 列的内容
SELECT name, author FROM tb_bibliography;5.2 查询所有字段 *
SELECT *
FROM `数据库名`.`表名`
[WHERE 条件];
USE lib;
SELECT * FROM tb_bibliography;5.3 定义字段别名 AS
SELECT 字段名 AS 别名 FROM 表名;
-- 多个字段同时定义别名
SELECT 字段1 AS 别名1, 字段2 AS 别名2, ..., 字段n AS 别名n
FROM 表名;5.4 查询指定记录WHERE
-- 基础语法:查询指定字段的指定记录
SELECT 字段1, 字段2, ... -- 或用 * 查询所有字段
FROM 表名
WHERE 筛选条件; -- 核心:通过条件定位指定记录
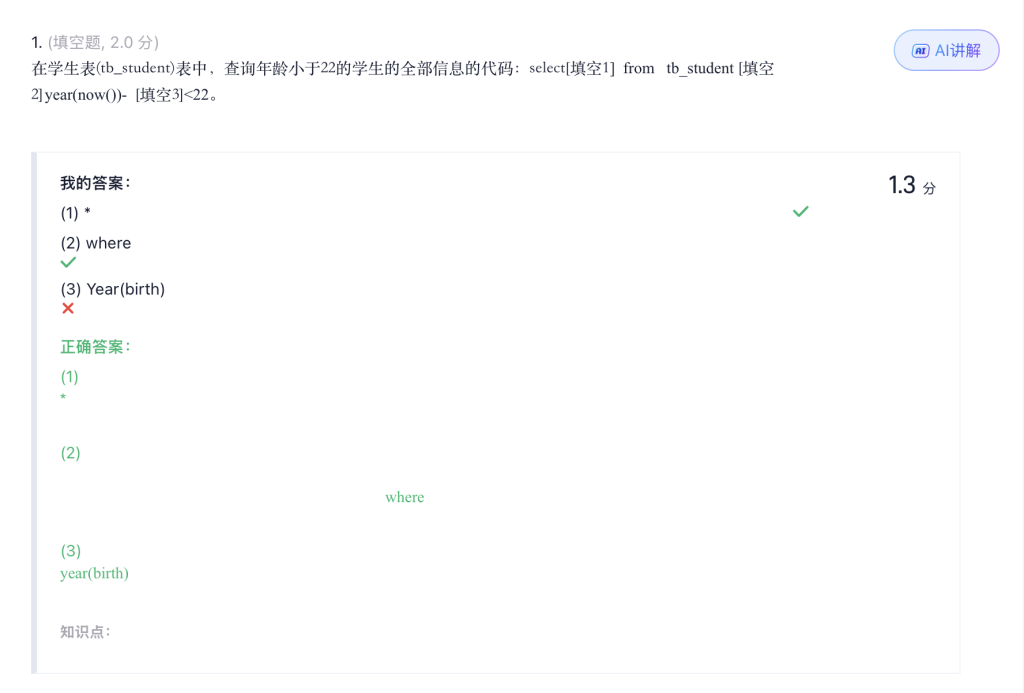
//查询学生表(tb_student)学生编号(stu_num)为“16100101”的学生的全部信息
select *from tb_student where stu_num ="16100101";5.5 带不等号的查询 <> !=
使用 <> 查询年龄不等于20的学生(推荐,通用)
SELECT name, age FROM tb_student WHERE age <> 20;
使用 != 查询性别不等于“男”的学生(仅MySQL/SQL Server可用)
SELECT name, gender FROM tb_student WHERE gender != '男';5.6 比较大小的查询 > <
查询学生表(tb_student)中学生年龄大于25的学生的全部信息
select *from tb_student where year(now())-year(birth)> 25;5.7 多重条件查询 And Or
逻辑运算符
- 与:两个都为真才为真
- 或:双方只要有一个为真就为真
- 抑或:当左右状态不等时为真,否则为假
-- 查询年龄<>20且学院ID<>1的学生
SELECT * FROM tb_student WHERE age <> 20 AND college_id <> 1;
-- 从tb_student表中,查询姓名是“马诗”“邹睿睿”“马又云”中任意一个的所有记录
SELECT * FROM tb_student
WHERE name='马诗' OR name='邹睿睿' OR name='马又云';
-- 从tb_bibliography表中,查询作者是“王若宾” 且 出版时间是2020年的所有记录
SELECT * FROM tb_bibliography
WHERE author='王若宾' AND pub_time=2020;5.8 按范围查询 Between And
-- 正向查询:字段值在 [最小值, 最大值] 区间内
SELECT 字段1, 字段2, ... -- 或 * 查询所有字段
FROM 表名
WHERE 字段 BETWEEN 最小值 AND 最大值;
-- 反向查询
SELECT 字段1, 字段2, ...
FROM 表名
WHERE 字段 NOT BETWEEN 最小值 AND 最大值;
-- 从tb_bibliography表中,查询出版时间在2015到2019之间的图书的名称和出版时间
SELECT name, pub_time FROM tb_bibliography
WHERE pub_time BETWEEN 2015 AND 2019;
DATEDIFF(结束时间, 开始时间)5.9 或者关系的简洁实现 IN
查询条件为多个或者时,可使用关键字IN,比使用多个或者关系以“OR”连接的表达更为简洁
SELECT 字段1, 字段2, ... -- 或 * 查询所有字段
FROM 表名
WHERE 字段名 IN (值1, 值2, ..., 值n);-- 从tb_bibliography表中,查询出版社是“人民邮电出版社”或“高等教育出版社”的图书名称和出版社信息
-- IN表示“属于指定集合中的任意一个”,等价于多个OR条件的组合
SELECT name,publishing FROM tb_bibliography
WHERE publishing IN ('人民邮电出版社','高等教育出版社');5.10 限制输出数量的查询 LIMIT m,n / n
-- 语法:LIMIT 条数(返回前 N 条记录)
SELECT 字段1, 字段2, ... -- 或 * 查询所有字段
FROM 表名
LIMIT n; -- n 为正整数,代表要返回的记录条数
-- m:起始偏移量(0 = 第一条记录),n:返回条数
LIMIT m, n;
在书目表(tb_bibliography)中,显示第二本书到第五本书的图书名称(name)
SELECT name FROM tb_bibliography LIMIT 1,4;5.11 查找空值 IS NULL
IS NUL用于判断字段值是否为空(NULL的条件关键字(不能用=或<>判断 NULL)
-- 查询tb_bibliography表中,intro(简介)字段值为空的所有记录
SELECT * FROM tb_bibliography WHERE intro IS NULL;5.12 消除结果中的重复值 DISTINCT
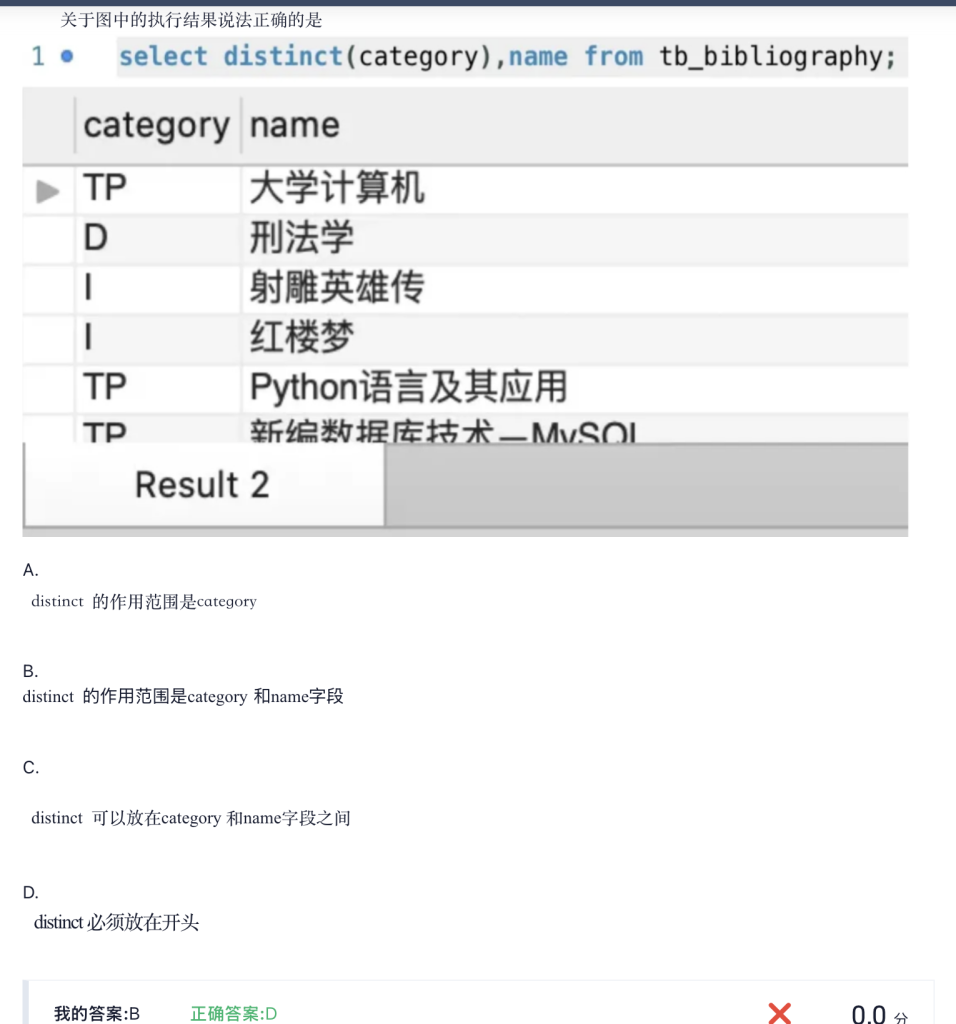
关键字 DISTINCT把查询结果中重复的内容去掉,仅显示有区别的信息,DISTINCT 关键字仅针对一个
字段,而非多个字段的组合。
-- 示例:查询图书表中所有不重复的出版社名称(消除出版社重复值)
SELECT DISTINCT publishing
FROM tb_bibliography;5.13 模糊查询 LIKE ‘_ / %’
模糊查询用不精确的数据,依赖 LIKE 关键字和通配符
SELECT 字段1, 字段2, ... -- 或用 * 查询所有字段
FROM 表名
WHERE 字符串字段名 LIKE '模糊匹配模式'
[其他子句]; -- 可选:ORDER BY、LIMIT等| 通配符 | 含义 | 示例 |
|---|---|---|
| % | 匹配 0 个、1 个或多个任意字符(长度不限) | ‘ 张 %’ 匹配所有以 “张” 开头的字 |
| _ | 匹配恰好 1 个任意字符(长度固定 1 位) | ‘ 张_’ 匹配以 “张” 开头的 2 字字 |
若需查询包含 % 或 _ 的原始数据,需用转义字符/,它只会影响紧跟在它后面的那个字符。
/%代表普通字符%
USE lib;
-- 从tb_bibliography表中,查询名称包含“计算”的记录的name字段
SELECT name FROM tb_bibliography WHERE name LIKE "%计算%";
-- 从tb_bibliography表中,查询简介包含“教材”的记录的name和intro字段
SELECT name, intro FROM tb_bibliography WHERE intro LIKE "%教材%";
-- 从tb_student表中,查询名称以“马”开头的记录的name字段
SELECT name FROM tb_student WHERE name LIKE "马%";
-- 从tb_student表中,查询名称以“马”开头且长度为2字的记录的name字段(_匹配1个字符)
SELECT name FROM tb_student WHERE name LIKE "马_";
-- ESCAPE '/':指定/为转义符,这里匹配的是原始字符“/90/%”(避免%被当作通配符)
SELECT name,intro FROM tb_bibliography
WHERE intro LIKE "%/90/%%" ESCAPE '/';
-- ESCAPE '/':指定/为转义符,这里匹配的是原始字符“_”(避免_被当作通配符)
SELECT name,intro FROM tb_bibliography
WHERE intro LIKE "%学术研究/_个人阅读都非常适合%" ESCAPE '/';
A:_ 匹配 1 个任意字符,正好匹配最后一位 5
B:% 匹配任意长度后缀,能匹配“西安交通大学…”
C:这里用的是 =,_ 不再是通配符,只是普通字符;除非字段真的等于“计算统计_”,否则匹配不到
D:/% 表示把 % 当作普通字符匹配,所以能匹配包含“90%”的文本。
利用函数查询
案例5.14 聚合函数的使用 AVG COUNT MAX MIN SUM
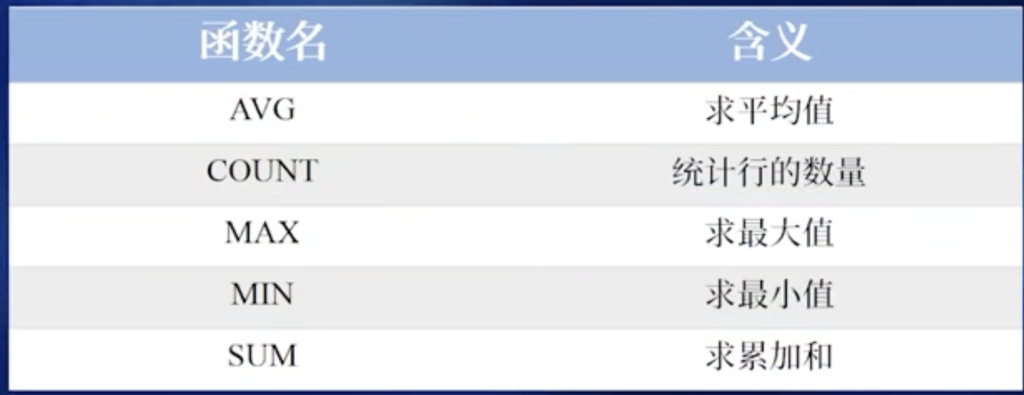
AVG
-- 全表统计:计算指定字段的平均值
SELECT AVG(数值型字段名) [AS 别名]
FROM 表名
[WHERE 筛选条件];
-- 分组统计:按指定字段分组后,计算每组内该字段的平均值
SELECT 分组字段名, AVG(数值型字段名) [AS 别名]
FROM 表名
[WHERE 筛选条件]
GROUP BY 分组字段名;COUNT
-- 统计所有符合条件的记录行数(包含NULL值)
SELECT COUNT(*) [AS 别名]
FROM 表名
[WHERE 筛选条件];
-- 统计指定字段非NULL值的数量
SELECT COUNT(字段名) [AS 别名]
FROM 表名
[WHERE 筛选条件];
-- 统计指定字段不重复且非NULL值的数量
SELECT COUNT(DISTINCT 字段名) [AS 别名]
FROM 表名
[WHERE 筛选条件];SUM
SELECT SUM(数值型字段名) [AS 别名]
FROM 表名
[WHERE 筛选条件];
SELECT 分组字段名, SUM(数值型字段名) [AS 别名]
FROM 表名
[WHERE 筛选条件]
GROUP BY 分组字段名;
SELECT SUM(DISTINCT 数值型字段名) [AS 别名]
FROM 表名
[WHERE 筛选条件];不存在 SUM*,因为会自动忽略NULL值
MAX() ,MIN()
-- 全表统计:获取指定字段的最大值
SELECT MAX(字段名) [AS 别名]
FROM 表名
[WHERE 筛选条件];
-- 全表统计:获取指定字段的最小值
SELECT MIN(字段名) [AS 别名]
FROM 表名
[WHERE 筛选条件];
-- 分组统计:按指定字段分组后,获取每组内该字段的最大值
SELECT 分组字段名, MAX(字段名) [AS 别名]
FROM 表名
[WHERE 筛选条件]
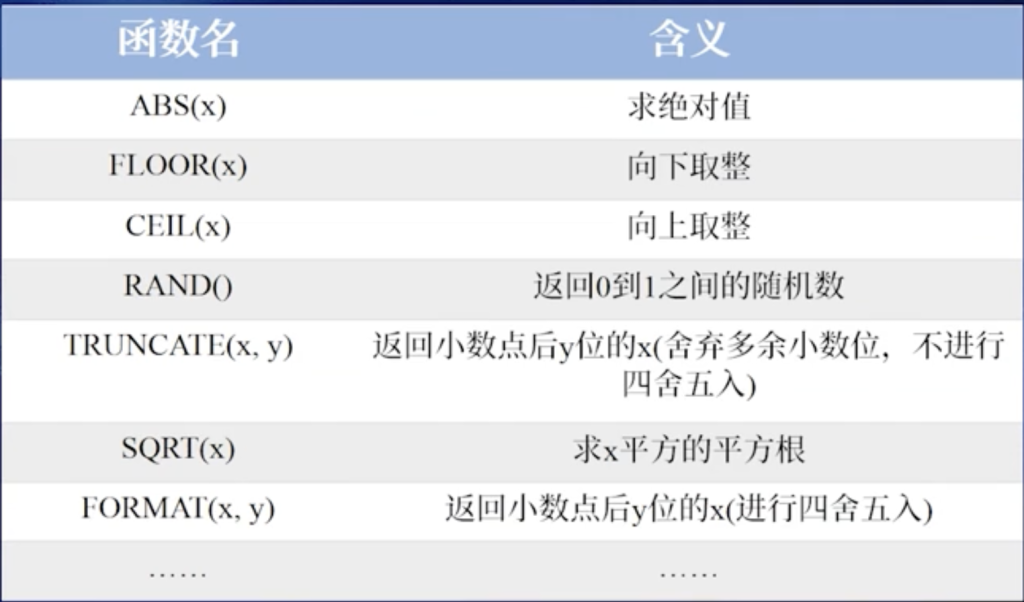
GROUP BY 分组字段名;案例5.15 数学函数的使用 ABS RAND
ROUND(x, y) 是 数值四舍五入函数,用于将数值 x 按指定精度(保留 y 位小数)进行四舍五入,返回四舍五入后的数值结果
| 函数 | 核心作用 | 返回类型 | 核心场景 |
|---|---|---|---|
ROUND(x,y) | 对数值四舍五入到指定精度 | 数值型 | 数值计算、统计结果处理 |
FORMAT(x,y) | 对数值 ** 格式化(含四舍五入)** 并转为字符串 | 字符串型 | 结果展示、可读性优化 |
SELECT ABS(5), ABS(-5); -- 5, 5
SELECT FLOOR(1.5), FLOOR(-1.5); -- 1, -2(1.5向下取整为1;-1.5向下取整为-2)
SELECT CEIL(1.5), CEIL(-1.5); -- 2, -1(1.5向上取整为2;-1.5向上取整为-1)
-- 5. 使用RAND函数生成0到1之间的随机浮点数(每次执行结果不同)
SELECT RAND();
-- 6. 使用TRUNCATE函数截断小数:保留指定小数位数,直接截断(不四舍五入)
SELECT TRUNCATE(3.1415926, 2); -- 3.14(保留2位小数,截断后的值)
-- 7. 使用SQRT函数计算平方根:返回非负数的平方根
SELECT SQRT(4), SQRT(5); -- 2, 2.2360679775(4的平方根是2;5的平方根是近似值)
-- 保留3位小数:3.1415926 四舍五入后为 3.142(第4位是5,进1)
SELECT FORMAT(3.1415926, 3);
-- ROUND:返回数值3.15,可直接用于后续计算
ROUND(3141.59, 2) AS round_result,
-- round_result: 3141.59(数值型,可做 3141.59 + 100 = 3241.59)
-- FORMAT:返回字符串"3,141.59",带千位分隔符,仅用于展示
FORMAT(3141.59, 2) AS format_result;
-- format_result: "3,141.59"(字符串型,若做 "3,141.59" + 100 会报错)案例5.16 字符串函数的使用 INSTR

-- 切换到lib数据库
USE lib;
-- 1. UPPER:将字符串转为大写
SELECT UPPER('hello'); -- 结果:HELLO
-- 2. LOWER:将字符串转为小写
SELECT LOWER('HELLO'); -- 结果:hello
-- 3. LEFT:取字符串左侧的指定长度字符(取'hello'前3个字符)
SELECT LEFT('hello',3); -- 结果:hel
-- 4. RIGHT:取字符串右侧的指定长度字符(取'hello'后3个字符)
SELECT RIGHT('hello',3); -- 结果:llo
-- 5. SUBSTRING:截取字符串(参数:原字符串, 起始位置, 长度;从'hello'第2位开始取3个字符)
SELECT SUBSTRING('hello',2,3); -- 结果:ell(注意:多数数据库中起始位置从1开始)
-- 6. LENGTH:计算字符串长度('hello'是5个字符;'你好'在部分数据库中占4字节,结果可能为4)
SELECT LENGTH('hello'), LENGTH('你好'); -- 结果:5, 4(不同数据库对中文字符的长度计算可能不同)
-- 7. INSTR:查找子串在原字符串中的首次出现位置(没找到返回0)
SELECT INSTR('hello','e'), INSTR('hello','T'), INSTR('hello','i');
-- 结果:2('e'在第2位)、0('T'不存在)、0('i'不存在)
-- 8. LPAD:左填充字符串(将'world'填充到10位,不足部分用'hello'循环填充)
SELECT LPAD('world', 10, 'hello'); -- 结果:hello wor('world'长度5,补5位:取'hello'的前5位)
-- 9. INSERT:替换字符串(参数:原字符串, 起始位置, 替换长度, 新子串;在'hello'第2位开始,替换1个字符为'T')
SELECT INSERT('hello', 2, 1, 'T'); -- 结果:hTllo案例5.17 日期和时间函数的使用
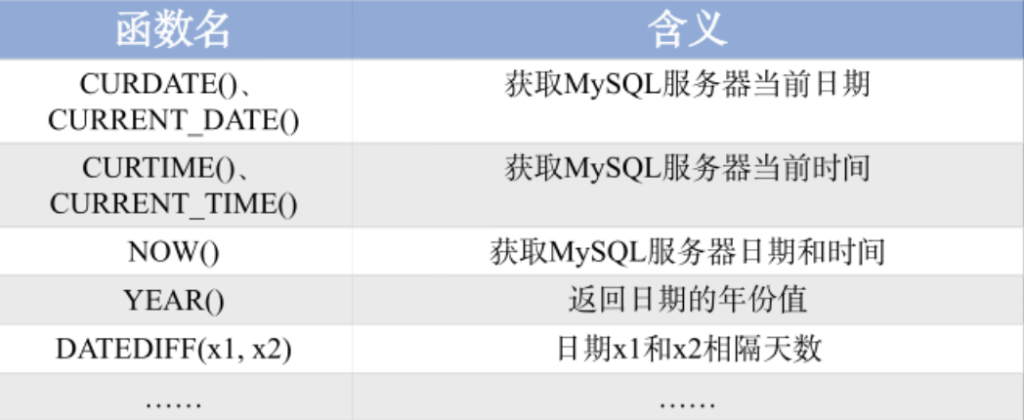
# 查询当前系统日期(CURDATE()和CURRENT_DATE()是等效函数)
SELECT CURDATE(), CURRENT_DATE();
结果示例:2025-11-25, 2025-11-25
# 查询当前系统时间(CURTIME()和CURRENT_TIME()是等效函数)
SELECT CURTIME(), CURRENT_TIME();
结果示例:15:30:45, 15:30:45
# 查询当前系统的日期+时间(NOW()返回当前完整的时间戳)
SELECT NOW();
#结果示例:2025-11-25 15:30:45
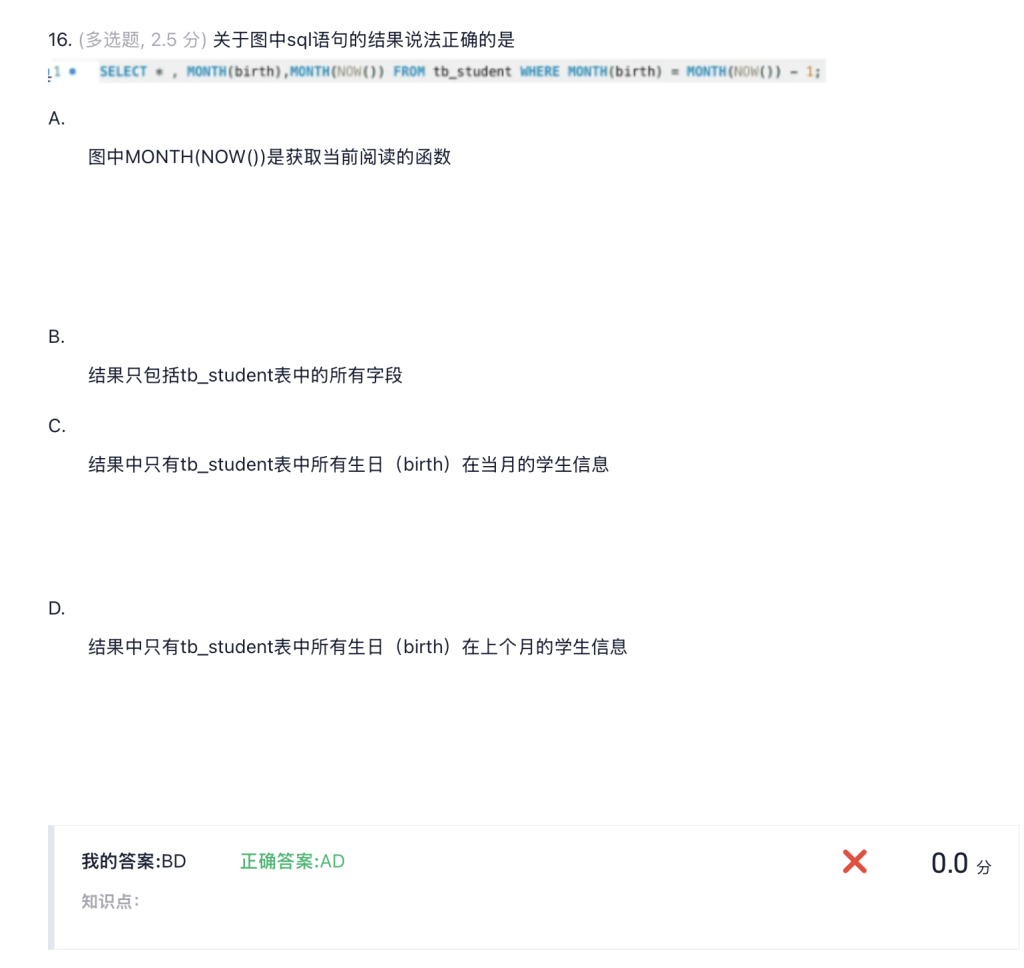
# 从学生表(tb_student)中查询学生姓名,并计算学生年龄
#YEAR(NOW()):取当前年份;YEAR(birth):取学生出生日期的年份;两者相减得到年龄
SELECT name, YEAR(NOW())-YEAR(birth) FROM tb_student;
#结果示例:"张三", 20
# 从借阅表(tb_record)中查询学生编号,并计算借阅时长(天数)
DATEDIFF(结束日期, 开始日期):返回两个日期之间的天数差(return_time是归还日期,borrow_time是借阅日期)
SELECT stu_num, DATEDIFF(return_time, borrow_time) FROM tb_record;
#结果示例:"2025001", 7分组查询
5.18 单字段分组查询 Group BY
GROUP BY的作用是将表中记录按指定字段的值 “分组”,相同值的记录会被归为一组;通常搭配聚合函数(COUNT统计数量、SUM求和等),实现 “按组统计” 的需求
-- 1. 仅分组(等价于DISTINCT单个字段去重)
SELECT 分组字段 FROM 表名 GROUP BY 分组字段;
-- 2. 分组+聚合统计
SELECT 分组字段, 聚合函数(字段) FROM 表名 GROUP BY 分组字段;
USE lib;
-- 1. 按“图书分类(category)”分组,查询所有不重复的分类(等价于SELECT DISTINCT category FROM tb_bibliography)
SELECT category FROM tb_bibliography GROUP BY category;
-- 2. 按“图书分类(category)”分组,统计每个分类下的图书总数
SELECT category, COUNT(*) FROM tb_bibliography GROUP BY category;
-- 说明:
-- - GROUP BY category:按图书分类分组
-- - COUNT(*):统计每组(每个分类)下的记录数量(即该分类的图书数)
-- 3. 按“学院(school)”分组,统计每个学院的学生数量
SELECT school, COUNT(school) FROM tb_student GROUP BY school;
-- 说明:
-- - GROUP BY school:按学生所属学院分组
-- - COUNT(school):统计每组(每个学院)下的学生数量(school非空的记录数)
- D:
若SELECT中写分组列:分组列在每组内的值是相同的,所以可以直接展示;
若SELECT中写列函数(即聚合函数,如 COUNT、SUM、AVG):聚合函数会对每组数据计算出一个汇总结果(比如每组的数量、总和);

5.19 多字段分组查询
多字段分组查询是指通过多个字段的组合对数据进行分组,只有当所有分组字段的值完全一致时,记录才会被归为同一组
SELECT
分组字段1,
分组字段2,
...,
分组字段n,
聚合函数(统计字段1) [AS 别名1],
聚合函数(统计字段2) [AS 别名2]
FROM 表名
[WHERE 分组前筛选条件]
GROUP BY 分组字段1, 分组字段2, ..., 分组字段n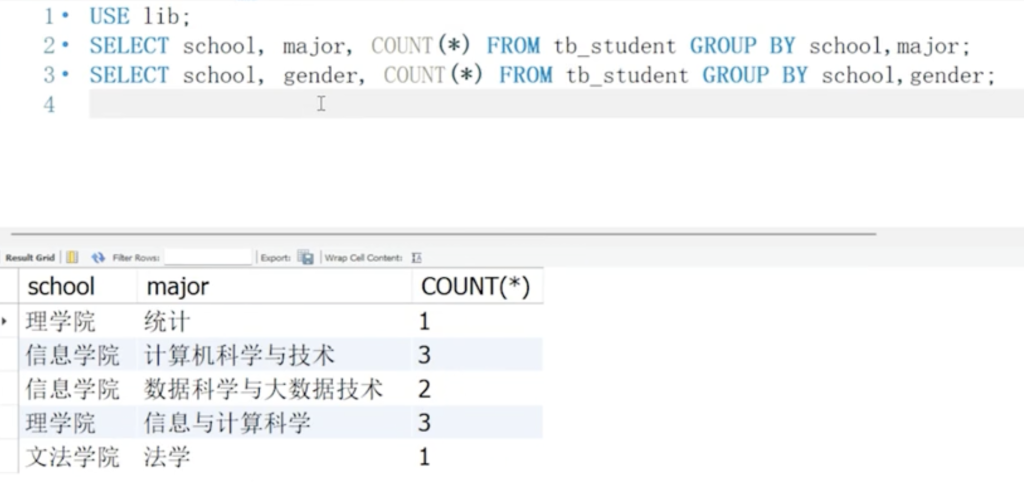
5.20 回溯分组查询 Group By WITH ROLLUP
在分组统计的基础上,自动添加 “分组小计” 和 “总计” 行,实现 “多级汇总” 的效果
SELECT 分组字段1, 分组字段2, 聚合函数(字段)
FROM 表名
GROUP BY 分组字段1, 分组字段2 WITH ROLLUP;
SELECT school,major, COUNT(*) FROM tb_student GROUP BY school, major WITH rollup;
SELECT school,gender, COUNT(*) FROM tb_student GROUP BY school,gender WITH rollup;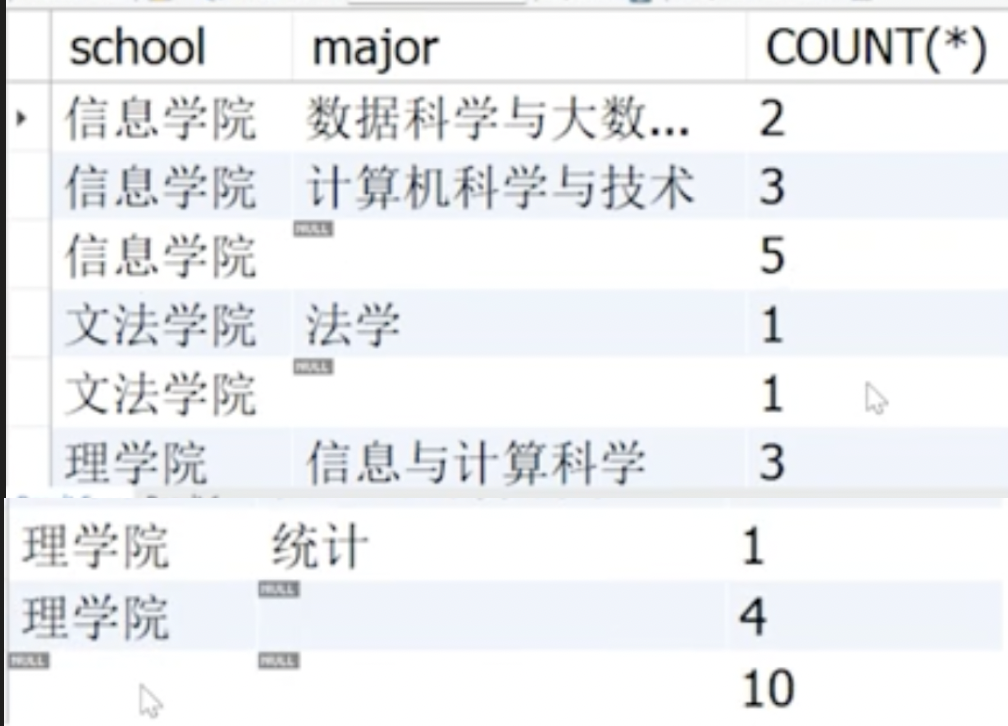


5.21 HAVING关键字
WHERE和HAVING的核心区别
| 维度 | WHERE | HAVING |
|---|---|---|
| 执行时机 | 分组之前执行 | 分组之后执行 |
| 筛选对象 | 原始记录(行) | 分组后的结果(组) |
| 支持的条件 | 只能用字段 / 常量,不能用聚合函数 | 可以用聚合函数 / 分组字 |
若强行用WHERE代替HAVING,会出现两种情况:
WHERE是分组前筛选 “行”,无法识别分组后的聚合结果
若条件是 “聚合函数”:数据库直接报错(WHERE不支持聚合函数);HAVING是作用于GROUP BY之后,筛选的是分组后的 “组”
若条件是 “分组字段”:虽然语法不报错,但逻辑变成 “分组前筛选行”,和 “分组后筛选组” 的需求完全不同。
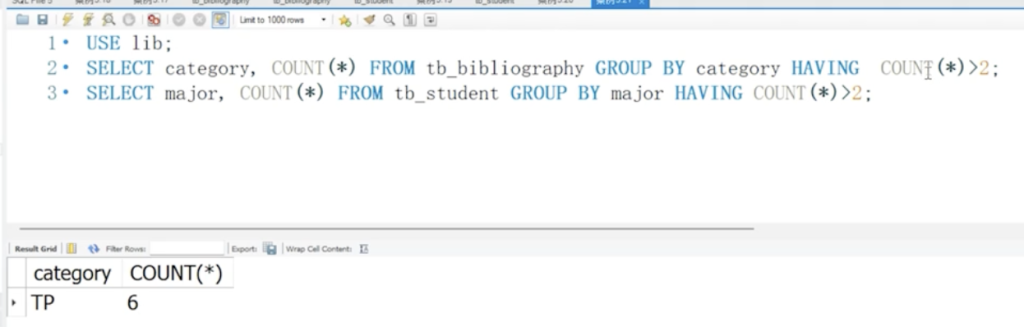

- 选项 A:错误。
with rollup能用于单字段分组(比如单字段分组后,汇总该字段的总数)。 - 选项 B:正确。分组完成后,
with rollup会在结果中添加一行 / 多行,用NULL填充分组字段,代表 “向上汇总” 的结果 - 选项 C:正确。结合
count()等聚合函数时,with rollup会自动统计 “第 1 层分组(最细粒度)、第 2 层分组(上一级汇总)、第 3 层分组(更上层汇总)…… 直到总汇总” 的数量。 - 选项 D:正确

排序 ORDER BY ASC DESC
5.22 排序查询
SELECT 字段名 FROM 表名 ORDER BY 字段名 [ASC/DESC];
ORDER BY:指定排序的依据字段;
ASC:升序(默认,可省略);
DESC:降序(必须显式写)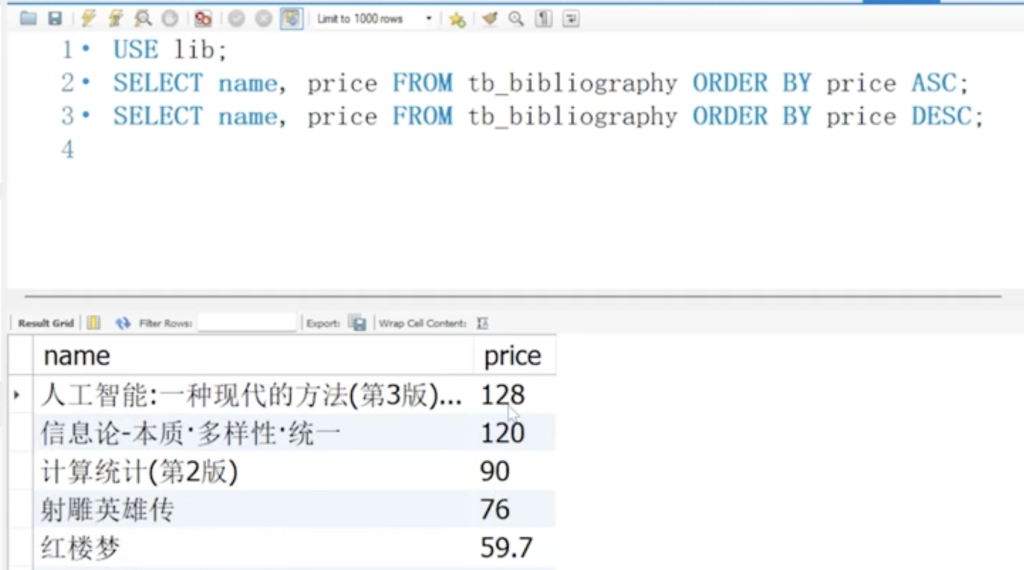
5.23 多字段排序
SELECT 字段名 FROM 表名 ORDER BY 字段名1, 字段名2... [ASC/DESC];
- 多字段排序的优先级:字段 1 > 字段 2 > …(先按字段 1 排,字段 1 相同再按字段 2 排);
- 每个字段可单独指定排序方式(ASC 升序 / DESC 降序),未指定则默认 ASC。
连接查询
案例5.24 建立实例表
-- 创建t1表
CREATE TABLE t1 (
id INT,
name1 CHAR(5)
) CHARACTER SET UTF8MB4;
-- 创建t2表
CREATE TABLE t2 (
id INT,
name2 CHAR(5)
) CHARACTER SET UTF8MB4;
-- 向t1表插入数据
INSERT INTO t1 (id, name1) VALUES
(1, '张三'),
(2, '李四'),
(NULL, 't1');
-- 向t2表插入数据
INSERT INTO t2 (id, name2) VALUES
(1, '王五'),
(2, '赵六'),
(NULL, 't2');内连接 INNER JOIN
在 MySQL 里:JOIN 默认就是 INNER JOIN
- INNER JOIN(内连接):只要两边能匹配的行(交集)
- OUTER JOIN(外连接):在匹配行之外,还会保留一边或两边不匹配的行,并用 NULL 补齐另一边的列
- LEFT OUTER JOIN:保留左表全部
- RIGHT OUTER JOIN:保留右表全部
案例5.25 等值与非等值连接

# 第一问
-- 功能:查询t1表和t2表中id相等的记录(内连接),返回所有字段
SELECT * FROM t1 INNER JOIN t2 ON t1.id = t2.id;
# 第二问
-- 功能:从学生表(tb_student)和学生信息表(tb_inf_student)中,
-- 查询学生学号、姓名、爱好、籍贯(通过学号关联两张表)
SELECT t1.stu_num, t1.name, t2.hobby, t2.ori_loca
FROM tb_student t1
INNER JOIN tb_inf_student t2 ON t1.stu_num = t2.stu_num;
# 第四问
-- 功能:关联学生表、借阅记录表、图书表、书目表,
-- 查询学生学号、姓名、图书名称(通过学号、条形码、ISBN依次关联四张表)
SELECT t1.stu_num, t1.name, t4.name
FROM tb_student t1
JOIN tb_record t2 ON t1.stu_num = t2.stu_num -- 学生表关联借阅表(学号)
JOIN tb_book t3 ON t2.barcode = t3.barcode -- 借阅表关联图书表(条形码)
JOIN tb_bibliography t4 ON t3.ISBN = t4.ISBN; -- 图书表关联书目表(ISBN)
# 第五问
-- 功能:与第四问结果一致(用“多表逗号分隔+WHERE条件”的方式实现关联),
SELECT t1.stu_num, t1.name, t4.name
FROM tb_student t1, tb_record t2, tb_book t3, tb_bibliography t4
WHERE t1.stu_num = t2.stu_num -- 学生表关联借阅表
AND t2.barcode = t3.barcode -- 借阅表关联图书表
AND t3.ISBN = t4.ISBN; -- 图书表关联书目表ON后面跟的是表关联条件,WHERE后面跟的是结果过滤条件
案例5.26 自连接
- 若某个表与自身进行连接,称为自表连接(或自身连接),简称自连接。
- 连接本质上仍然是内连接,它是把一张表当成两张表来连接,从而得到需要的查询结果。
- 使用自连接时,需要为表指定至少两个不同的别名;且对所有查询字段的引用,必须用表别名限定 —— 否则 SELECT 操作会因无法准确定位字段而失败
-- 功能:找到与“管理信息系统实用教程(第2版)”同作者的所有图书(包含自
-- 逻辑:将书目表(tb_bibliography)自连接(自己和自己关联),通过作者字段匹配
SELECT
t2.name, -- 图书名称
t2.author -- 图书作者
FROM tb_bibliography t1 -- 别名t1:作为“参照图书”的表
JOIN tb_bibliography t2 -- 别名t2:作为“匹配同作者”的表(自连接)
ON t1.author = t2.author -- 关联条件:t1和t2的作者相同
WHERE
t1.name = "管理信息系统实用教程(第2版)"; -- 过滤条件:参照图书是指定书名案例5.27 自然链接 NATURAL JOIN
任务:用自然连接显示图书表(tb_book)中每本书的索书号(barcode)、ISBN 号(ISBN),以及书目表(tb_bibliography)的图书名称(name)和作者(author)
自然连接是自动使用表内相同字段作为连接条件的连接过程(所以两个表中应该有相同的元素),且会在查询结果集中去掉重复的属性;自然连接使用的关键字是NATURAL JOIN
-- -------------- 第一条SQL:关联图书表和书目表 --------------
-- 功能:查询图书的条形码、ISBN,以及对应书目的名称、作者
-- 逻辑:通过NATURAL JOIN(自然连接)关联tb_book和tb_bibliography
-- 自然连接的规则:自动匹配两张表中“名称相同的字段”作为关联条件
SELECT
t1.barcode, -- 图书表的条形码
t1.ISBN, -- 图书表的ISBN
t2.name, -- 书目表的图书名称
t2.author -- 书目表的作者
FROM tb_book t1 -- 别名t1:图书表
NATURAL JOIN tb_bibliography t2; -- 自然连接书目表(自动匹配同名字段,通常是ISBN)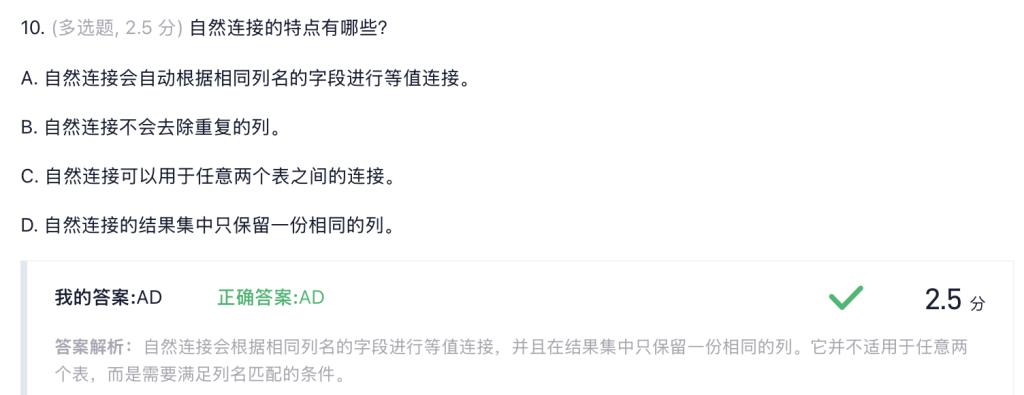
案例5.28 左外链接 …LEFT JOIN …ON…

-- 1. t1左连接t2(保留t1所有记录,匹配t2中id相等的记录)
SELECT * FROM t1
LEFT JOIN t2 ON t1.id = t2.id;
-- 2. 学生表左连接借阅表(保留所有学生,匹配其借阅记录)
SELECT * FROM tb_student t1
LEFT JOIN tb_record t2 ON t1.stu_num = t2.stu_num;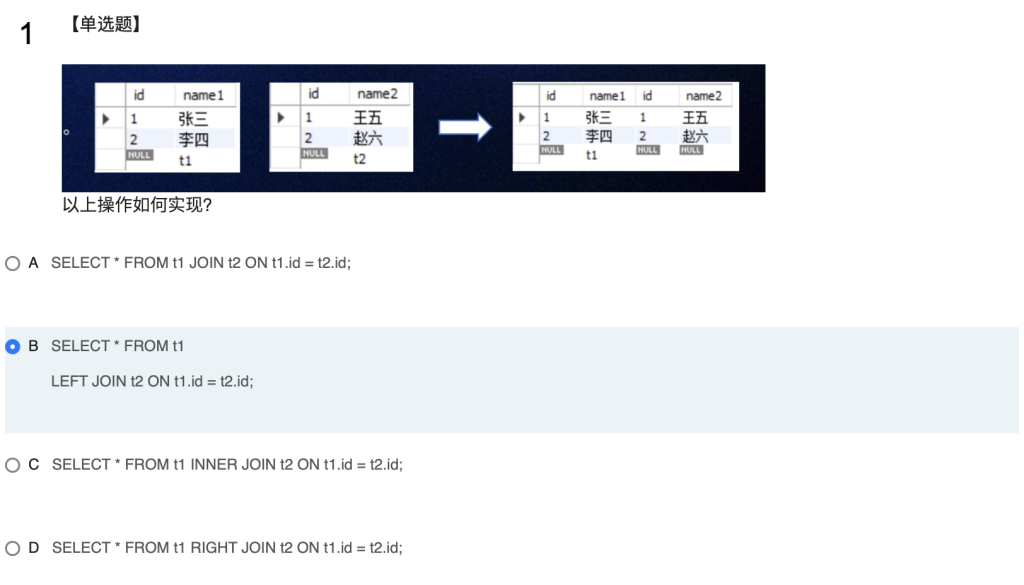
题目中最终结果保留了t1表的所有记录(包括id=NULL的t1行),同时匹配t2表中id相等的记录(t2中无匹配的部分显示为NULL 这正是 **LEFT JOIN(左连接)的特性:
案例5.29 右外链接 …RIGHT JOIN… ON…
也称为Right Outer Join,RIGHT JOIN会返回右表的所有记录,即使左表中没有匹配的记录。如果左表中没有匹配项,则结果集中左表的字段将为NULL
-- 1. t1右连接t2:保留t2所有记录,匹配t1中id相等的记录(t1无匹配则补NULL)
SELECT * FROM t1 RIGHT JOIN t2 ON t1.id = t2.id;
-- 2. 借阅表(tb_record)右连接学生表(tb_student):保留所有学生,匹配其借阅记录(无借阅则补NULL)
SELECT * FROM tb_record t2 RIGHT JOIN tb_student t1 ON t1.stu_num = t2.stu_num;
案例5.30 交叉链接 …CROSS JOIN…

-- 1. t1和t2交叉连接:返回t1和t2的所有行的笛卡尔积(即两表行数的乘积)
SELECT * FROM t1 CROSS JOIN t2;
-- 2. 学生表和学生信息表交叉连接:返回两表所有行的组合,查询学生学号、姓名及信息表的爱好、籍贯
SELECT t1.stu_num,t1.name,t2.hobby,t2.ori_loca
FROM tb_student t1
CROSS JOIN tb_inf_student t2;嵌套查询
“嵌套在主查询里的 SELECT 语句” 就叫子查询(也叫嵌套查询)
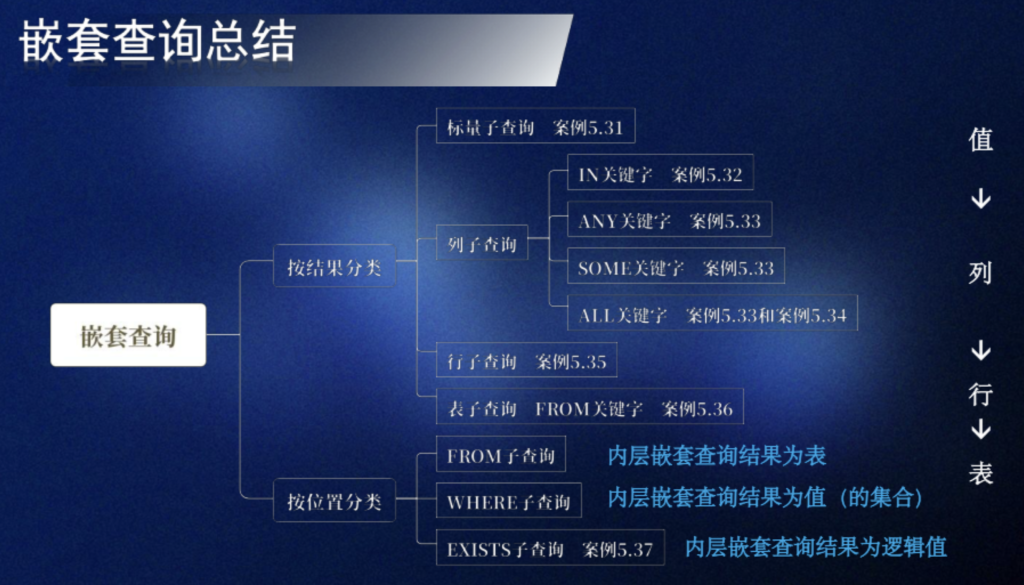
案例5.31 标量子查询
标量子查询的查询结果是一个标量数据,而非集合数据
查询书目表(tb_bibliography)中,条码号(barcode)为 “TP311.13” 图书
但中 tb_bibliography 表并没有 barcode 一列,需要先通过子查询查找到 tb_book 表中 barcode 值为 “TP311.13” 的图书的 ISBN,进而通过这个 ISBN 再确定 tb_bibliography 表中 name 和 author 的信息
-- 1. 根据图书条形码查图书的名称和作者
SELECT name, author FROM tb_bibliography -- 从书目表tb_bibliography取书名、作者
WHERE ISBN=(
SELECT ISBN FROM tb_book -- 子查询:从图书表tb_book查条形码对应的ISBN
WHERE barcode="TP311.13" -- 筛选条件:条形码是TP311.13
);查询后面加了一个条件嘛,怎么就成子查询了:确实看起来像 “加了个条件”,但核心区别在于:这个条件的值不是直接写死的,而是通过另一个 SELECT 语句动态查出来的
案例5.32 列子查询 IN
列子查询是指子查询返回的结果集是 N 行 1 列,该结果通常来自对表某个字段的查询结果。带 IN 关键字的子查询是最常用的一类子查询,在使用 IN 关键字进行查询时,子查询语句返回的结果应该是一个数据列中的多个值,如果仅返回 1 个数值,则可用标量子查询代替
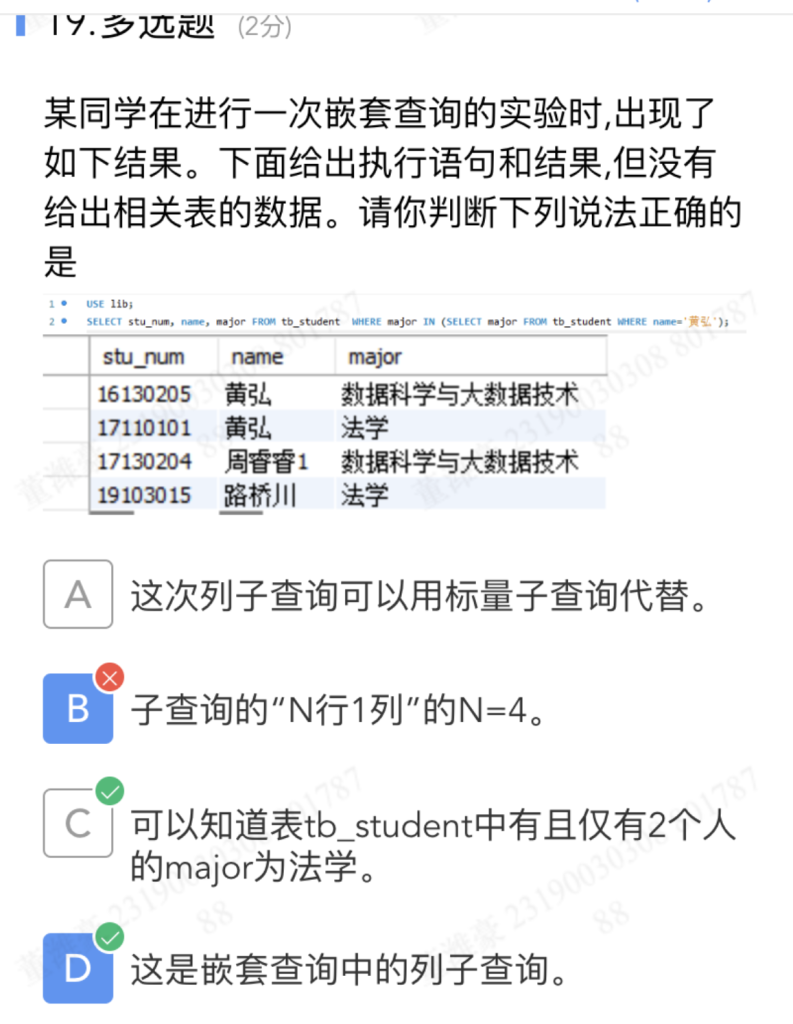
- (1)查询学生表(tb_student)中和黄弘相同专业学生读者的学号(stu_num),姓名(name)和专业(major)。
- (2)查询学生表(tb_student)中还未还书的读者的学号(stu_num)和姓名(name)

-- 1. 查询和“黄弘”同专业的学生信息
SELECT stu_num, name, major FROM tb_student -- 从学生表取学号、姓名、专业
WHERE major IN ( -- 条件:专业属于子查询的结果(IN用于匹配多个值)
SELECT major FROM tb_student -- 子查询:先查“黄弘”对应的专业
WHERE name='黄弘' -- 筛选条件:学生姓名是“黄弘”
);
-- 2. 查询有未归还图书的学生学号和姓名
SELECT stu_num, name FROM tb_student -- 从学生表取学号、姓名
WHERE stu_num IN ( -- 条件:学号属于子查询的结果
SELECT stu_num FROM tb_record -- 子查询:从借阅表查“未归还”对应的学号
WHERE return_time IS NULL -- 筛选条件:归还时间为空(代表未归还)
);- 标量子查询:只能返回单个值(一行一列),所以用
=匹配; - 你现在用的
IN子查询:能返回多个值(一列多行),所以用IN匹配这些值- 子查询只返回 “计算机” 一个值(标量),可以用
=
子查询可能返回 1001、1002、1003 多个值,就得用IN来匹配
- 子查询只返回 “计算机” 一个值(标量),可以用

- D ✅:EXISTS 就是判断子查询有没有返回行(有→TRUE/1,无→FALSE/0)。
- C ❌:EXISTS 不关心具体返回值,只关心“是否存在”。
- A ❌:多列比较通常是 (a,b) IN (SELECT a,b …) 这种“行子查询”,不是 EXISTS 的典型表述。
- B ✅(考试常规答案):很多情况下 EXISTS 找到第一条匹配就停,常被认为比 IN 更高效(实际还看数据/索引/优化器)。
案例5.33 5.34 ALL & ANY
用列子查询为例,
查询学生表(tb_student)中
- (1)比信息学院出生日期最大的还要大的所有学生记录,使用 ALL 关键字,显示学生的姓名(name)、出生日期(birth)和所属学院(school), 同样的结果尝试用 max () 函数再实现一次。
- (2)比信息学院出生日期最小的还要小的所有学生记录,使用 ALL 关键字,显示学生的姓名(name)、出生日期(birth)和所属学院(school)
- (3)比信息学院出生日期最小的还要大的所有学生记录,使用 ANY 关键字,显示学生的姓名(name)、出生日期(birth)和所属学院(school)
- (4)比信息学院出生日期最大的还要小的所有学生记录,使用 ANY 关键字,显示学生的姓名(name)、出生日期(birth)和所属学院(school)
要“超过整个集合的极值”时(比最大还大 / 比最小还小),用ALL
想表达“超过集合里某个门槛就行”(存在即可)时,用ANY
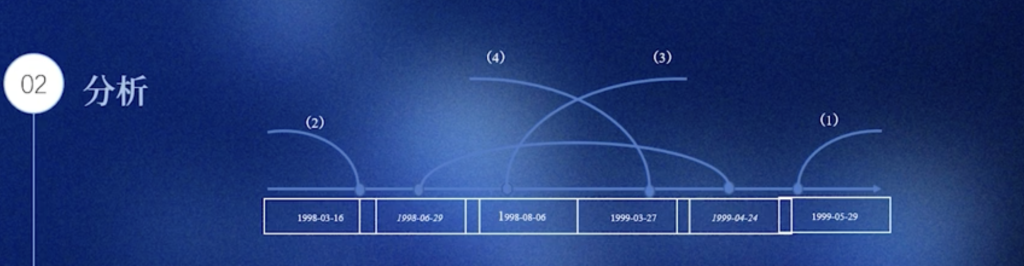
# 1. 显示信息学院学生,按出生日期升序排列
SELECT birth, school FROM tb_student
WHERE school="信息学院" -- 筛选“信息学院”的学生
ORDER BY birth ASC; -- 按出生日期(birth)从小到大排序(ASC是升序,可省略)
# 2. 查出生日期比“信息学院最大出生日期”还大的学生
SELECT name, birth, school FROM tb_student
WHERE birth > ALL(
SELECT birth FROM tb_student WHERE school = "信息学院"
);
# 3. 查出生日期比“信息学院最小出生日期”还小的学生
SELECT name, birth, school FROM tb_student
WHERE birth < ALL(
SELECT birth FROM tb_student WHERE school = "信息学院"
);
# 4. 查出生日期比“信息学院最小出生日期”还大的学生
SELECT name, birth, school FROM tb_student
WHERE birth > ANY(
SELECT birth FROM tb_student WHERE school = "信息学院"
);
# 5. 查出生日期比“信息学院最大出生日期”还小的学生
SELECT name, birth, school FROM tb_student
WHERE birth < ANY(
SELECT birth FROM tb_student WHERE school = "信息学院"
);- 任务:查询书目表(tb_bibliography)中,每种类型中最贵的图书名称(name)和价格(price)。使用 ANY 关键字。
- 由于要求查找每个类型下的价格最大值,分组后必然返回的是多组数据,如果用 max () 函数的返回值作为条件,那需要单独多次执行,而用 ANY 关键字可实现一条语句查询出每个类型图书的最高价格。
SELECT name, price FROM tb_bibliography
-- 筛选条件:价格等于“各分类下的最高价格”中的任意一个
WHERE price=ANY(
-- 子查询:按category(分类)分组,计算每个分类下的最高价格
SELECT MAX(price) FROM tb_bibliography
GROUP BY category
);但上述代码有一个问题:
这本书的 price 恰好等于某个类别的最大价(不管它属于哪个类别)
而我们需要的是
这本书的 (category) 对应的最大价 = 这本书的 price”
这时候用之前的 SQL 查询 “各分类最高价的书籍”,会把 “不是本类最高价、但刚好等于其他类最高价” 的书也查出来,外层查询的条件只是price等于这个列表里的任意一个值,完全没关联 “当前行属于哪个分类”,解决方案是使用行子查询
案例5.35 行子查询 (列1, 列2, …, 列n) =

如果不用行子查询,你就得拆成两个条件,并且要保证它们来自同一条记录(同一个子查询结果):
WHERE author = (SELECT author FROM ... WHERE name=...)
AND category = (SELECT category FROM ... WHERE name=...)-- 第一个查询:根据书籍名称,找“同一作者+同一分类”的所有书籍
SELECT name, author, category FROM tb_bibliography
WHERE (author, category) = ( -- 条件:作者和分类 同时等于子查询的结果
-- 子查询:先找到“管理信息系统实用教程(第3版)”对应的作者和分类
SELECT author, category FROM tb_bibliography
WHERE name="管理信息系统实用教程(第3版)"
);
-- 第二个查询:根据学生姓名,找“学号前2位相同+同一学院”的所有学生
SELECT stu_num, name, school FROM tb_student
WHERE (LEFT(stu_num,2), school) = ( -- 条件:学号前2位 + 学院 同时等于子查询的结果
-- 子查询:先找到“邹睿睿”对应的学号前2位和学院
SELECT LEFT(stu_num,2), school -- LEFT(stu_num,2):取学号的前2个字符
FROM tb_student WHERE name='邹睿睿'
);| 特点 | 列子查询 | 行子查询 |
|---|---|---|
| 返回结果 | 单列(可多行 / 单行,单列) | 多列(多列,仅单行) |
| 匹配方式 | 单个字段匹配(比如只比价格) | 多个字段组合匹配(比如同时比作者 + 分类) |
| 语法特征 | 用=/IN等匹配单个列 | 用(字段1,字段2)匹配一组列 |


案例5.36 表子查询

-- 最终查询:获取ISBN、书籍名称,以及对应的记录数量
SELECT ISBN, name, COUNT(*)
-- 从“子查询生成的临时表tb”中查询数据
FROM(
-- 子查询:先关联tb_book和tb_bibliography表,筛选状态为1的记录
SELECT b.ISBN, name -- 从关联结果中取ISBN和书籍名称
FROM tb_book b -- 别名b代表tb_book表(书籍表)
-- 左连接tb_bibliography表(书目信息表),关联条件是ISBN一致
LEFT JOIN tb_bibliography bi ON b.ISBN=bi.ISBN
WHERE status='1' -- 筛选条件:书籍状态为1(通常代表“可用”等含义)
) AS tb -- 将子查询结果命名为临时表tb
GROUP BY ISBN; -- 按ISBN分组,统计每个ISBN对应的记录数— ON 用来指定两张表连接的“匹配条件”(这里是通过ISBN字段关联) LEFT JOIN tb_bibliography bi ON b.ISBN=bi.ISBN
因为要根据图书的借阅状态,将图书对应的ISBN和书的名字显示出来,但是无法从书目表中直接获得该结果,因为只有图书表才有借阅状态,因此需要左连接,完全保留状态信息
案例5.37 子查询 EXISTS
- (1)查询学生表(tb_student)中,是否有学生读者的姓名是 “黄弘”
- (2)查询书目表(tb_bibliography)中,库存数为 0 的书目名称(name)
关键字 EXISTS 构造子查询时
当子查询的结果集不为空时,则 EXISTS 返回的结果为 TRUE,外层查询语句进行查询;
当子查询的结果集为空时,则 EXISTS 返回的结果为 FALSE,外层查询语句不进行查询。
-- 1. 检查tb_student表中是否存在名为“黄弘”的学生
-- EXISTS会返回1(存在)或0(不存在)
SELECT EXISTS(SELECT name FROM tb_student WHERE name='黄弘');
-- 2. 从tb_bibliography表中查询“在tb_book表中没有对应ISBN”的书籍名称
-- NOT EXISTS表示“子查询无结果时才满足条件
SELECT name FROM tb_bibliography
WHERE NOT EXISTS(
-- 子查询:检查tb_book中是否有相同ISBN的记录
SELECT ISBN FROM tb_book
WHERE tb_book.ISBN=tb_bibliography.ISBN
);联合查询
UNION关键字
UNION用于合并多个 SELECT 查询结果集成一个统一的结果集
对应位置的字段数据类型必须兼容(优先以第一个 SELECT 子句的字段类型为准,比如第一个是字符串,第二个也需是字符串 / 可隐式转换为字符串的类型)
1. 一班表(class_1)原始数据
| id(学号) | name(姓名) | score(分数) | |
|---|---|---|---|
| 101 | 张三 | 88 | |
| 102 | 李四 | 95 | |
| 103 | 王五 | 79 | |
| 104 | 赵六 | 92 | (注意:赵六在两张表中重复出现,分数相同) |
2. 二班表(class_2)原始数据
| id(学号) | name(姓名) | score(分数) | |
|---|---|---|---|
| 201 | 孙七 | 85 | |
| 202 | 周八 | 90 | |
| 104 | 赵六 | 92 | (与一班的赵六完全重复) |
| 203 | 吴九 | 81 |
-- 查询一班和二班的所有学生成绩,自动去除重复记录
SELECT id, name, score FROM class_1
UNION
SELECT id, name, score FROM class_2;执行结果(去重后,无重复的赵六)
| id(学号) | name(姓名) | score(分数) | |
|---|---|---|---|
| 101 | 张三 | 88 | (一班数据) |
| 102 | 李四 | 95 | (一班数据) |
| 103 | 王五 | 79 | (一班数据) |
| 104 | 赵六 | 92 | (仅保留 1 条重复记录) |
| 201 | 孙七 | 85 | (二班数据) |
| 202 | 周八 | 90 | (二班数据) |
| 203 | 吴九 | 81 | (二班数据) |
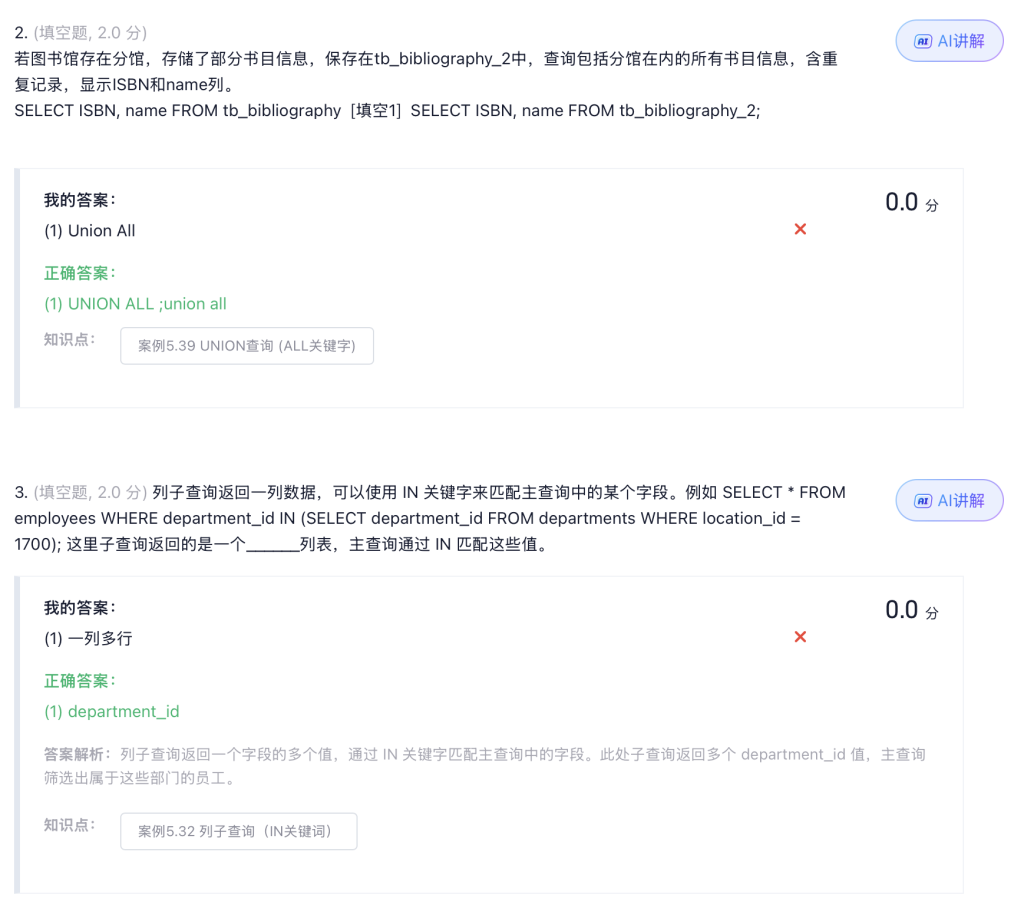
UNION查询 (ALL关键字)
-- 查询一班和二班的所有学生成绩,保留所有重复记录,且也不会自动排序
SELECT id, name, score FROM class_1
UNION ALL
SELECT id, name, score FROM class_2;执行结果(保留重复,赵六出现 2 次)
| id(学号) | name(姓名) | score(分数) | |
|---|---|---|---|
| 101 | 张三 | 88 | (一班数据) |
| 102 | 李四 | 95 | (一班数据) |
| 103 | 王五 | 79 | (一班数据) |
| 104 | 赵六 | 92 | (一班的赵六) |
| 201 | 孙七 | 85 | (二班数据) |
| 202 | 周八 | 90 | (二班数据) |
| 104 | 赵六 | 92 | (二班的赵六,重复保留) |
| 203 | 吴九 | 81 | (二班数据) |
例题:

- 选项 A:单层子查询无法 “每个国家” 动态计算平均值(会返回单个全局平均值,而非按国家分组的平均值),逻辑错误
- 选项 B:临时表 + JOIN 是替代方案,但并非 “嵌套查询” 的处理方式,不符合题干中 “嵌套查询特例应对” 的要求
- 选项 C:相关子查询会通过
country_id关联主表与子查询,为每个机构动态计算其所属国家的平均学生数量,是嵌套查询中处理 “按关联条件动态分组计算” 的典型思路,符合需求 - 选项 D:“忽略嵌套查询” 与题干要求的 “嵌套查询处理” 矛盾,且直接分组筛选无法实现 “机构与本国平均值比较” 的逻辑
精准匹配和模糊匹配

name=’黄’ 是精确匹配,不是模糊匹配(不是 LIKE ‘黄%’)。所以子查询 结果集为空 ⇒ EXISTS(…) 返回 0(FALSE)
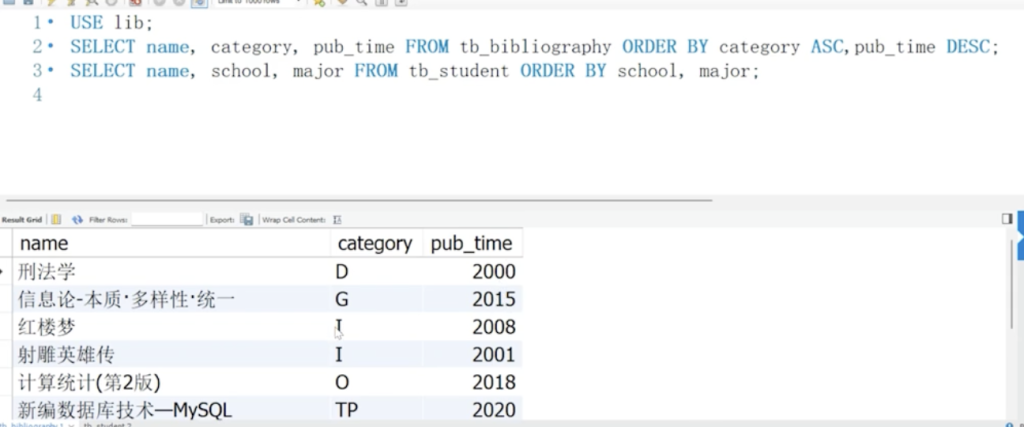
排序
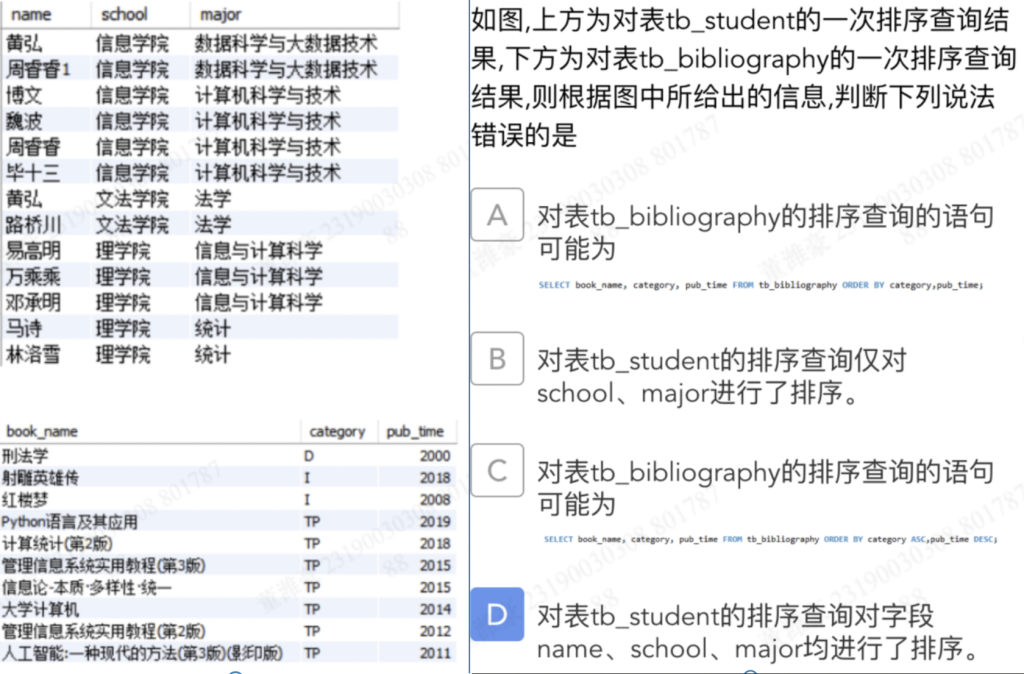
A 错(A 默认 pub_time 也是 ASC,不符合图里年份从大到小
D 错 结果是先按 school 分组,同一 school 内再按 major 分组,但 name 并没有按字母/拼音顺序排列(例如信息学院计算机专业里“博文、魏波、周睿睿、毕十三”并非按 name 排序)
Union

A 对B错:ALL 的作用就是不去重,也不会“自动排序”(排序要靠 ORDER BY)
C 错:ORDER BY 不是只对 tb_bibliography_2 排序,而是对合并后的整体排序
D 对:执行顺序先 UNION ALL 合并,再 ORDER BY 排序

UNION 会去除重复行,而 UNION ALL 保留所有行,因此 UNION ALL 的执行效率更高
两者都要求列数和数据类型兼容,不能直接合并不同结构的查询结果

这是错的,只要兼容即可

- A 错:MySQL/SQL 一般字段名大小写不敏感(尤其列名),写 isbn 不会因为小写就取不到。
- B 对:UNION 要求两边 列数相同,并且对应列的数据类型要可兼容(通常考试会表述为类型/长度一致或兼容)
- C 对:能查看两表所有图书的 isbn,name,且 不重复(因为 UNION 会去重)。
- D 对:UNION 本身就等价于 UNION DISTINCT,再加 distinct 结果不变(语法上通常写 UNION 或 UNION DISTINCT)
Distinct
DISTINCT 的去重是对整行结果生效
- A ✅ 对,D ❌ 错:distinct(category) 不是一个“函数调用”,而是 SELECT DISTINCT 里的 表达式写法。distinct 的作用范围是 category 和 name 的组合(整行)
- B ❌ 错:distinct 不能放在两个字段中间(它是 SELECT DISTINCT … 的语法)
- C ✅ 对:在这种用法下 distinct 必须紧跟在 select 后面(放在开头)
如果我今年可以一直恪守自我,牢记使命,明年的今天就可以向以前的朋友们问好了,我得自己战胜黑暗,你远离他们本身就是对他们的影响,他们会怀疑自己,质疑自己的过去,他们的回忆中会有一段空缺,所以不能再这样了,我不能如此自私
搜索语句和结果的对照

- A:pub_time IN (‘2015′,’2018′,’2019’) —— 精确匹配图中结果的三个年份
- D:pub_time BETWEEN 2015 AND 2019(包含 2015 和 2019)——会覆盖 2015~2019;而表里在这个区间内刚好只有 2015、2018、2019 这些记录,所以结果也一致
为什么 B、C 不选:
- B:BETWEEN 2015 AND 2020 会把 2020 的那条(图上表里确实有 2020)也查出来,结果会多一条
- C:pub_time = 2015 or 2018 or 2019 写法错误,因为 SQL 里 OR 连接的是布尔条件,而你写的 2018、2019 并不是“等于 2018/2019”的意思,它们只是数字常量,所以结果会变成恒真,查出几乎全部数据

表子查询
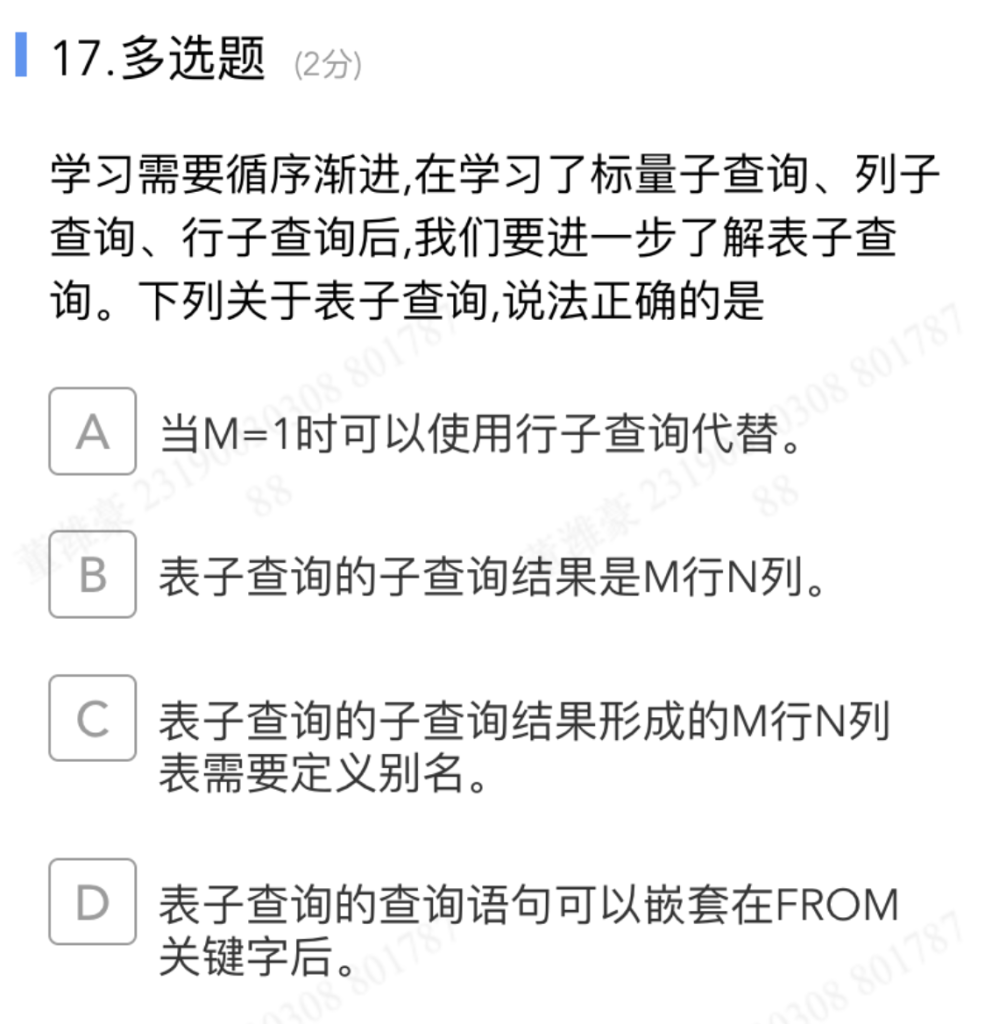
- A 对:表子查询结果是 M 行 N 列。当 M=1(只有一行)时,它就退化成 行子查询(1 行 N 列),很多场景下可以用行子查询来表达同样的含义。
- B 对:表子查询(派生表/derived table)的子查询结果就是 M 行 N 列。
- C 对:放在 FROM 后的子查询形成的是一张“临时表”,必须起别名(MySQL 等数据库要求)。例:SELECT * FROM (SELECT … ) AS t;
- D 对:表子查询最典型的用法就是把查询语句嵌套在 FROM 后面当作一张表来查
Group by / Count

- A 对:GROUP BY 按给定列的取值把结果分组,再对每组做统计/汇总,最终得到分组汇总结果。
- B 对:有 GROUP BY 时,SELECT 里出现的列一般要么是分组列,要么是聚合函数(如 COUNT/SUM/AVG/MAX/MIN),聚合函数对每一组返回一个值。
- C 对:COUNT(*) 统计的是行数,不管某些列是否为 NULL,只要该行存在就会被计入。
- D 对:COUNT(列名) 只统计该列非 NULL 的行数,遇到 NULL 会被忽略。
列子查询和行子查询

子查询部分 SELECT MAX(price) … 只返回 1 列(MAX(price) 这一列),但会按 category 分组返回多行(每个类别一行最大值),所以是 N 行 1 列 ⇒ 列子查询。
首先排除表子查询,如果没有看到(a,b) = (SELECT …) 这种形式,就说明不是行子查询,所以就是列子查询
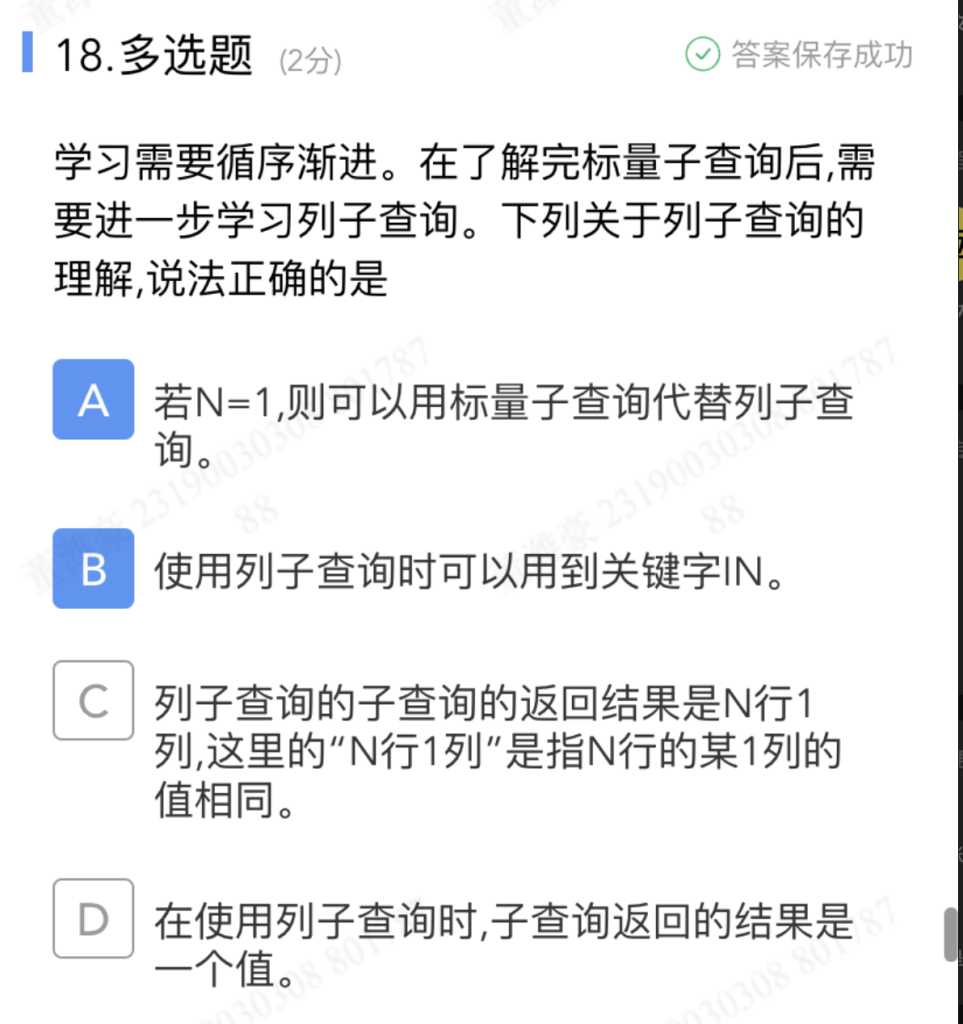
- A 对:列子查询返回 N 行 1 列。当 N=1(只返回 1 行 1 列)时,就退化成标量子查询,可以用标量子查询来写。
- B 对:列子查询常和 IN / ANY / ALL 等一起用,比如:x IN (SELECT col FROM …)。
- C 对:记住即可
- D 错:子查询返回“一个值”是标量子查询(1 行 1 列)的特点;列子查询一般是多个值(一列多行)

列名显示会有差异,但统计结果是一致的
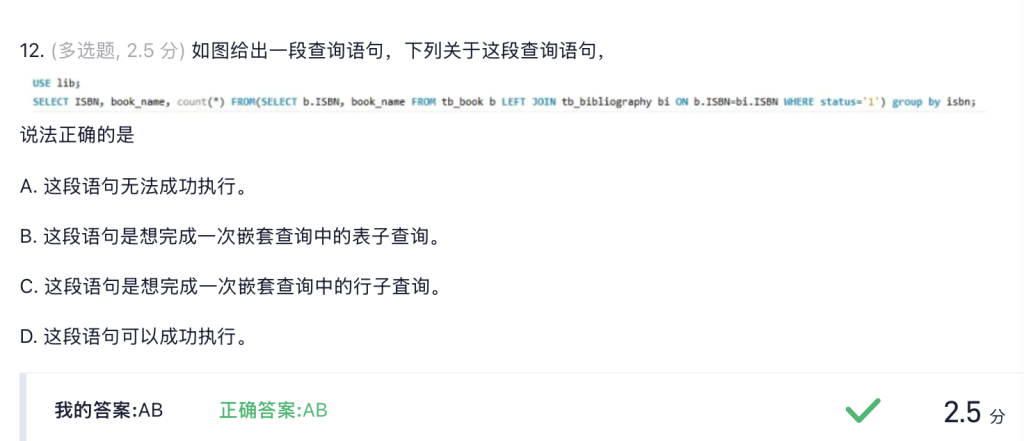
当使用 `GROUP BY` 时,`SELECT` 列表中的非聚合列必须全部出现在 `GROUP BY` 子句中(除非数据库启用了非标准的宽松模式,如 MySQL 的 `ONLY_FULL_GROUP_BY` 未开启)。但**标准 SQL 及严格模式下,此语句会因 `book_name` 未分组而报错**
NULL
选项 A:select 1 xor null;
XOR(异或)的逻辑是 “两个值不同则为真”。但NULL是 “未知”,所以1 XOR NULL的结果是NULL(无法确定 “1” 和 “未知” 是否不同)。
选项 B:select 1&&null;
&&(逻辑与)的规则是 “全为真才为真”。1是真,但NULL是 “未知”,所以1 && NULL的结果是NULL(无法确定整体是否全为真)。
选项 C:select !null;
!(逻辑非)作用于NULL时,“未知” 的否定仍是 “未知”,结果是NULL。
选项 D:select 1 or null:OR(逻辑或)的规则是 “有一个为真则为真”。1本身是真,所以不管NULL是什么,1 OR NULL的结果是1(真),不为NULL

原因很简单:SQL 里判断 NULL 不能用 =,必须用 IS NULL。
D:is not null 查的是非空(反过来了)
A:speciality=”” 查的是空字符串,不是 NULL
C:speciality = null 永远不成立(结果是 UNKNOWN)
Group up with rollup
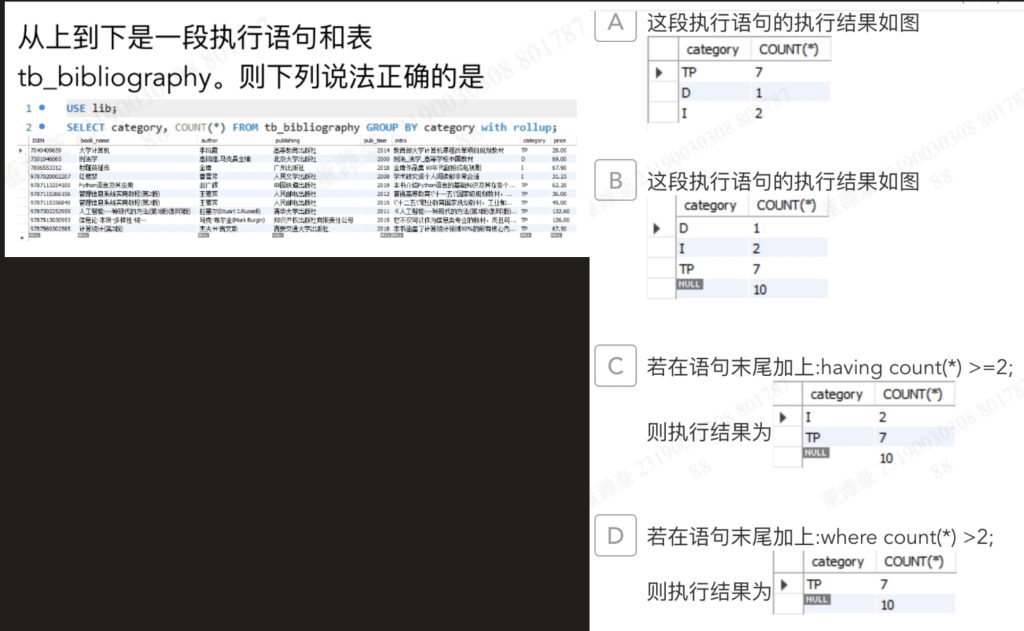
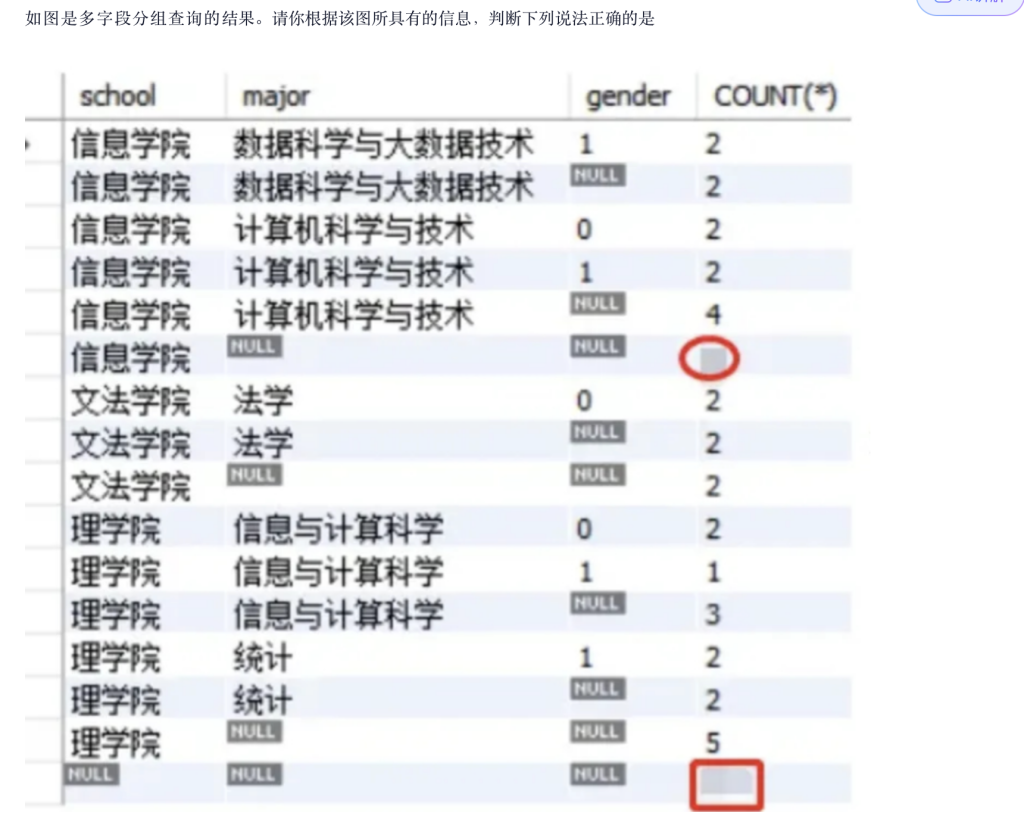
WITH ROLLUP 会在最后多出一行汇总:category = NULL,COUNT(*) = 总数
如果末尾加HAVING COUNT(*) >= 2,会把 D=1 过滤掉I=2、TP=7 保留汇总行 NULL=10 也满足 >=2,因此也会保留
Having
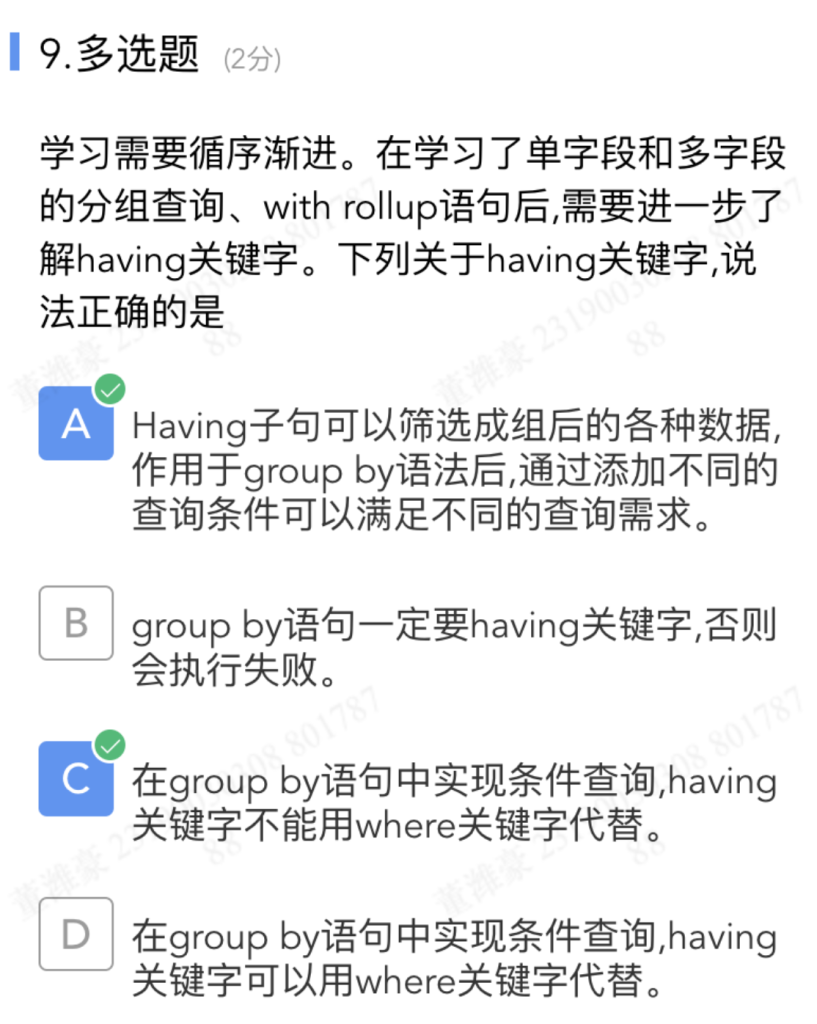
填空题

ALL ANY

分组查询


ROLLUP的价值在于生成多层级汇总,字段数越多,汇总层级越丰富(如3个字段可生成3层小计+1层总计),统计分析价值越高。若字段数=2,仅能生成1层小计+1层总计,效果有限;



15

Count 计算列中非NULL值个数
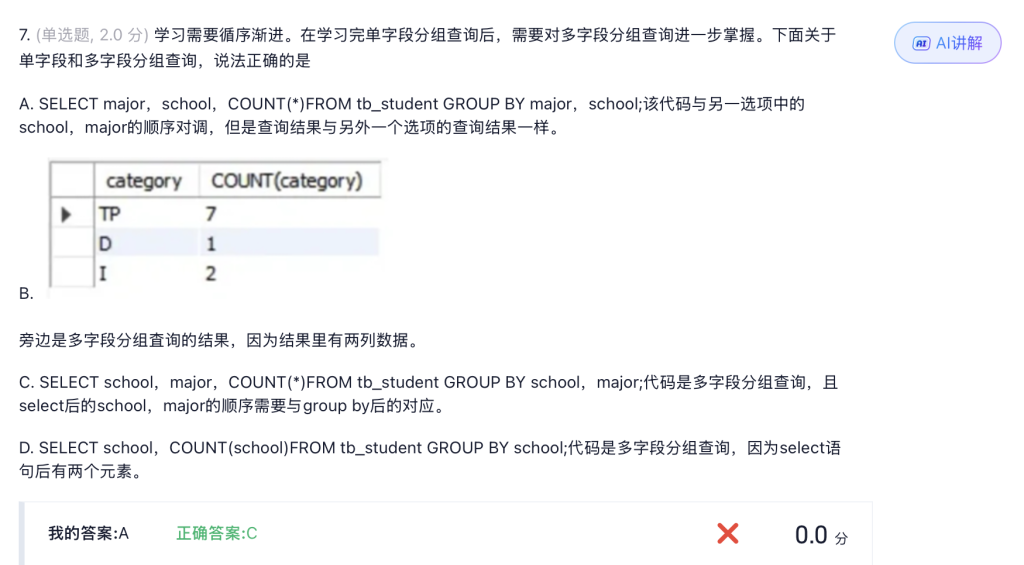

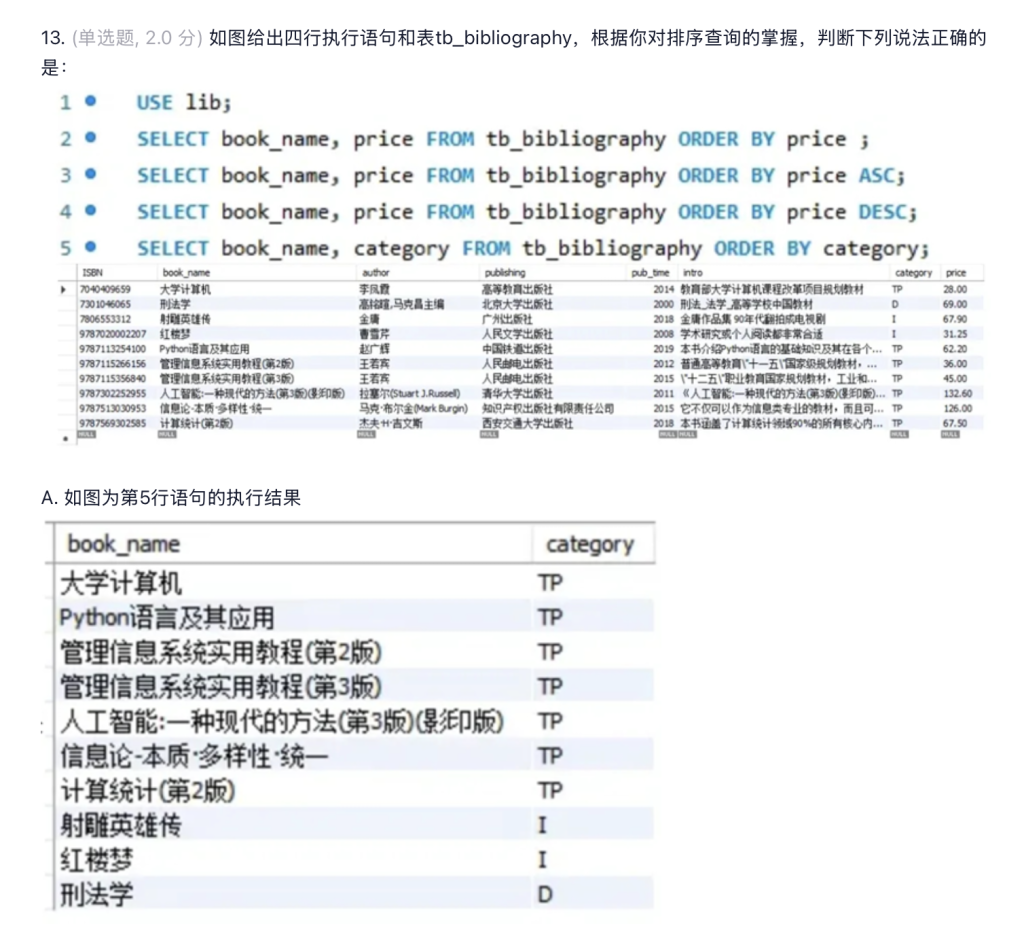
这个是错的,默认是升序



字符串






