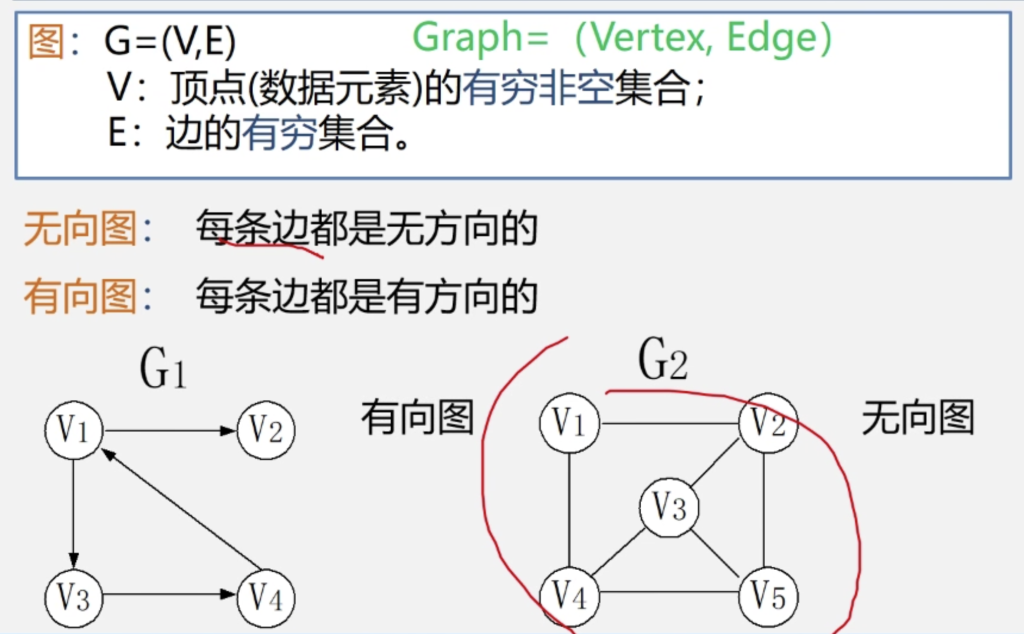
图(Graph)是一种较线性表和树更为复杂的数据结构。
在线性表中,数据元素之间仅有线性关系,每个数据元素只有一个直接前驱和一个直接后继;
在树形结构中,数据元素之间有着明显的层次关系,并且每一层上的数据元素可能和下一层中多个元素(即其孩子结点)相关,但只能和上一层中一个元素(即其双亲结点)相关;
而在图形结构中,结点之间的关系可以是任意的,图中任意两个数据元素之间都可能相关。
图的定义和术语
设图中顶点数为n,则:
对于无向图,边/弧的取值范围:0 — n(n-1)/2
对于有向图,边/弧的取值范围:0 — n(n-1)
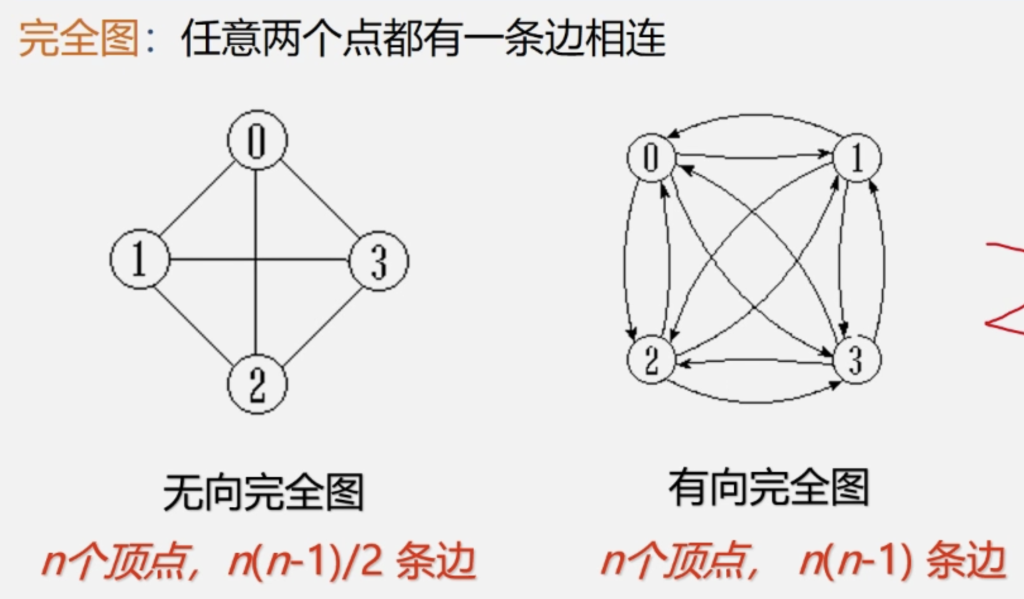
无向完全图:具有(Cn2) n(n-1)/2条边的无向图
有向完全图:具有 (2Cn2) n(n-1)条边的有向图
稀疏图:有很少边或弧的图(e<nlogn)
稠密图:有较多边或弧的图
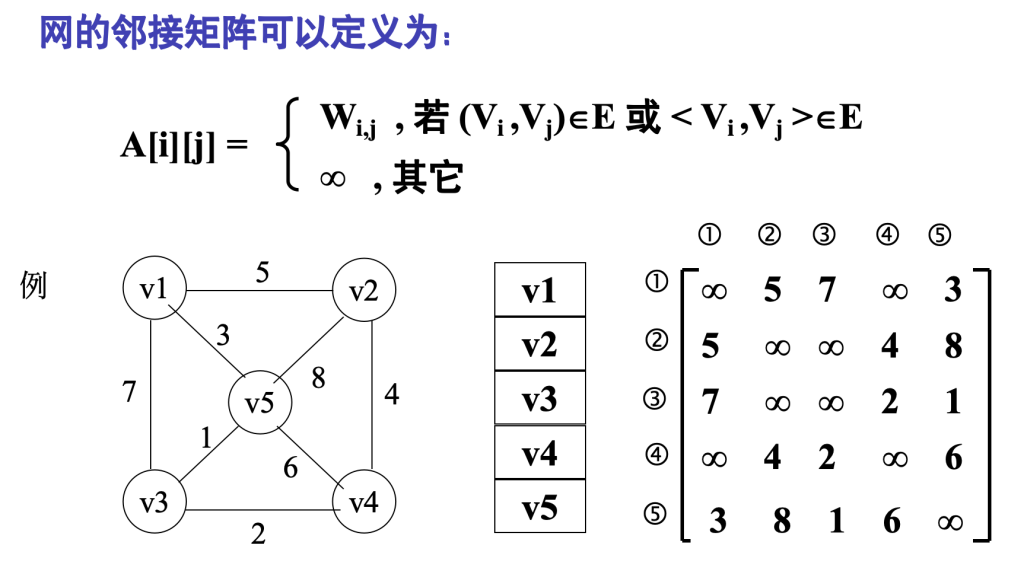
网:边/弧带权的图
邻接:有边/弧相连的两个顶点之间的关系
存在(vi, vj),则称vi和vj互为邻接点(无向图)
存在< vi, vj >,则称vi邻接到vj,vj邻接自vi(有向图)
关联(依附):边/弧与顶点之间的关系
存在(vi, vj)或< vi, vj >,则称该边/弧关联于vi和vj
离散数学中()中元素没有顺序区分,<>中元素有顺序区分
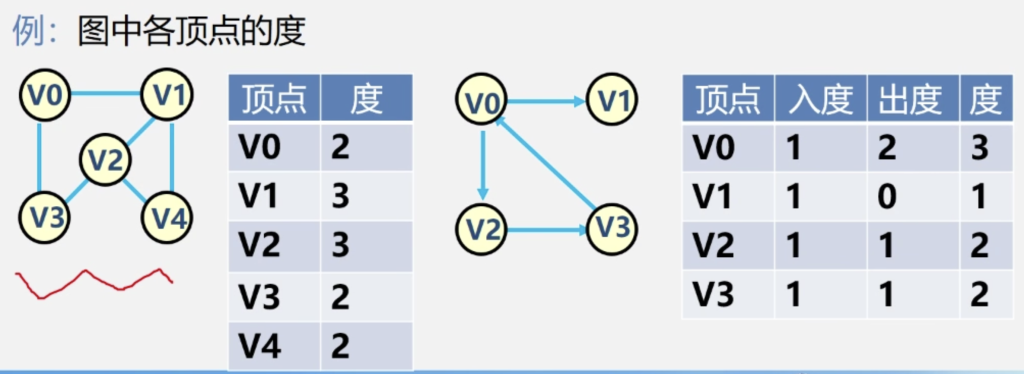
顶点的度:与该顶点相关联的边的数目,记为TD(v)
顶点v的入度是以v为终点的弧的数目,记作ID(v)
顶点v的出度是以v为起点的弧的数目,记作OD(v)
顶点v的度TD(v) = ID(v) + OD(v)
路径:接续的边构成的顶点的序列V={Vi0,Vi1,…… Vin},
路径长度:沿路径边的数目或沿路径各边权值之和
回路:第一个顶点和最后一个顶点相同的路径
简单路径:序列中顶点不重复出现的路径
简单回路:除了第一个顶点和最后一个顶点外,其余顶点不重复出现的回路
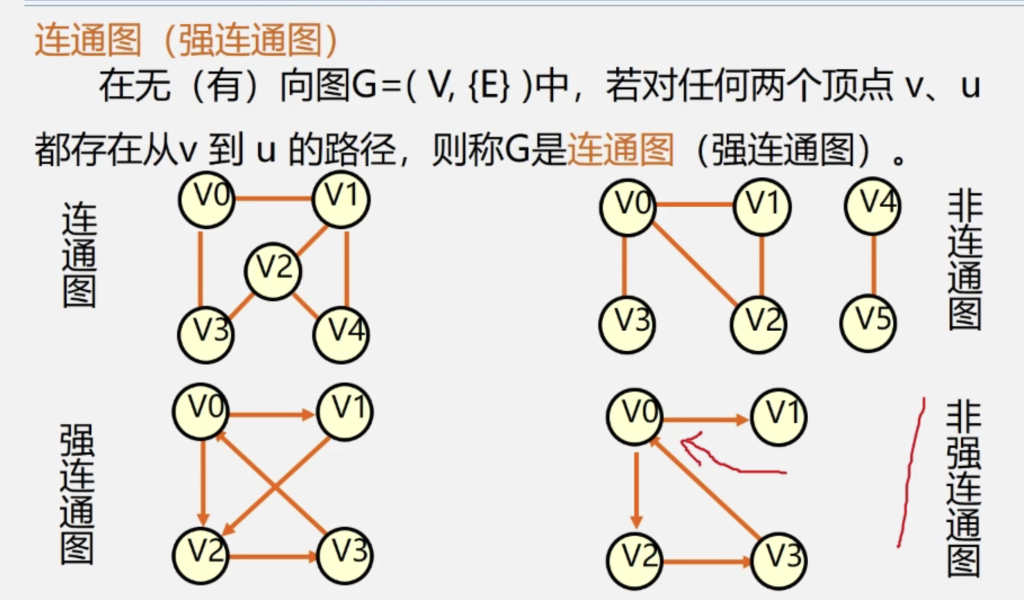
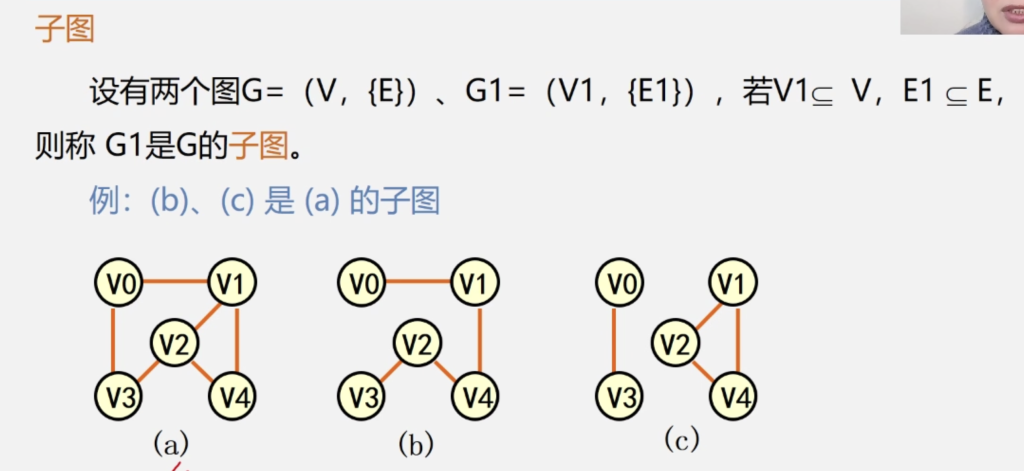
- 极大连通子图:
该子图是G的连通子图,将G的任何不在该子图中的顶点加入,子图不再连通。
简单来说即:在保持 “连通” 的前提下,这个子图已经 “装不下” 更多原图的顶点了 - 极小连通子图:
该子图是G的连通子图,在该子图中删除任何一条边,该子图不再连通
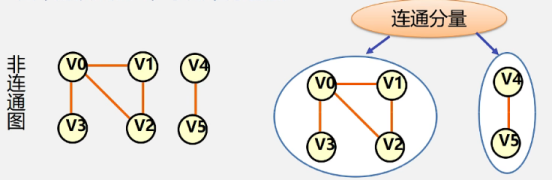
连通分量:无向图中的极大连通子图
强连通分量:有向图中的极大强连通子图
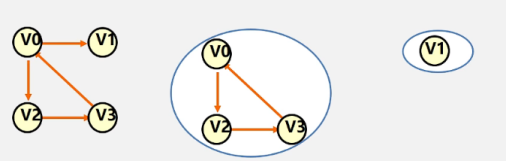
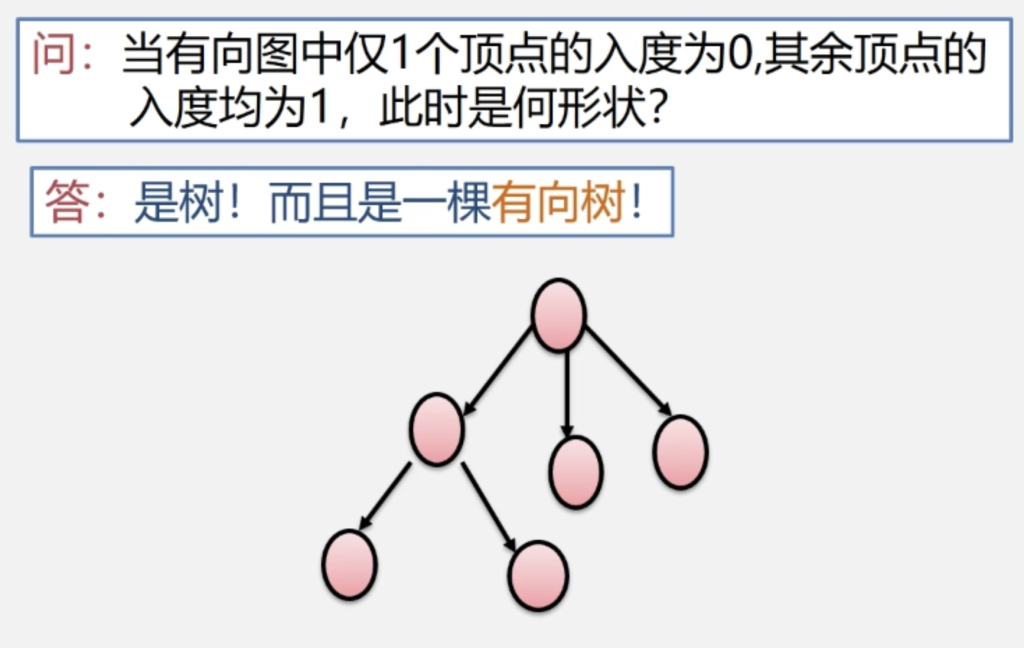
生成树:包含无向图G所有顶点的极小连通子图
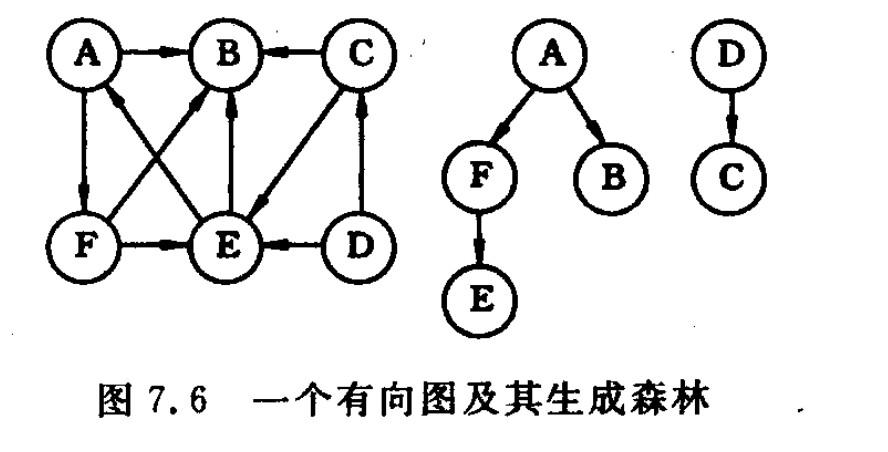
生成森林:对非连通图,由各个连通分量的生成树的集合
7.2 图的存储结构
图的逻辑结构:多对多。
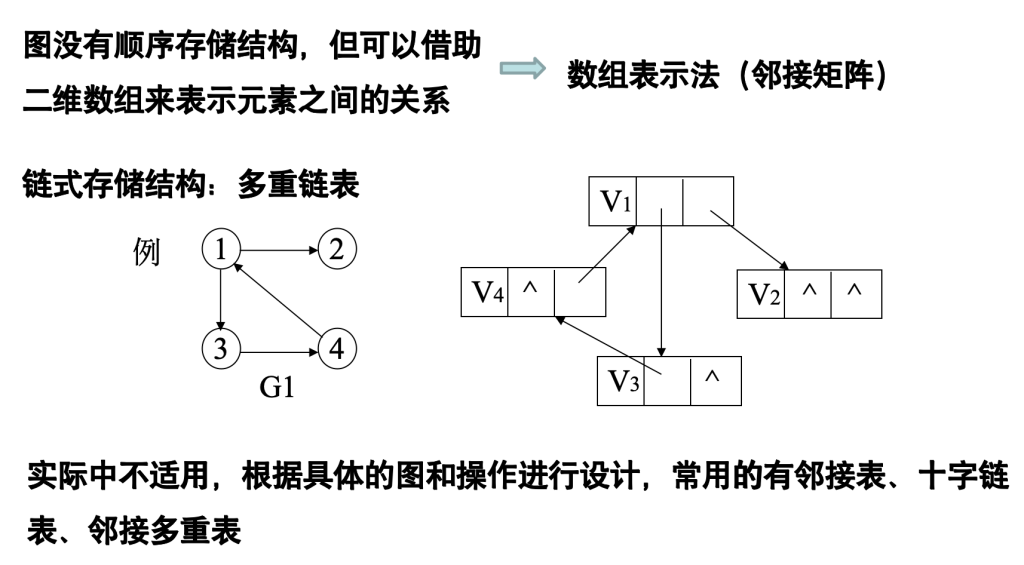
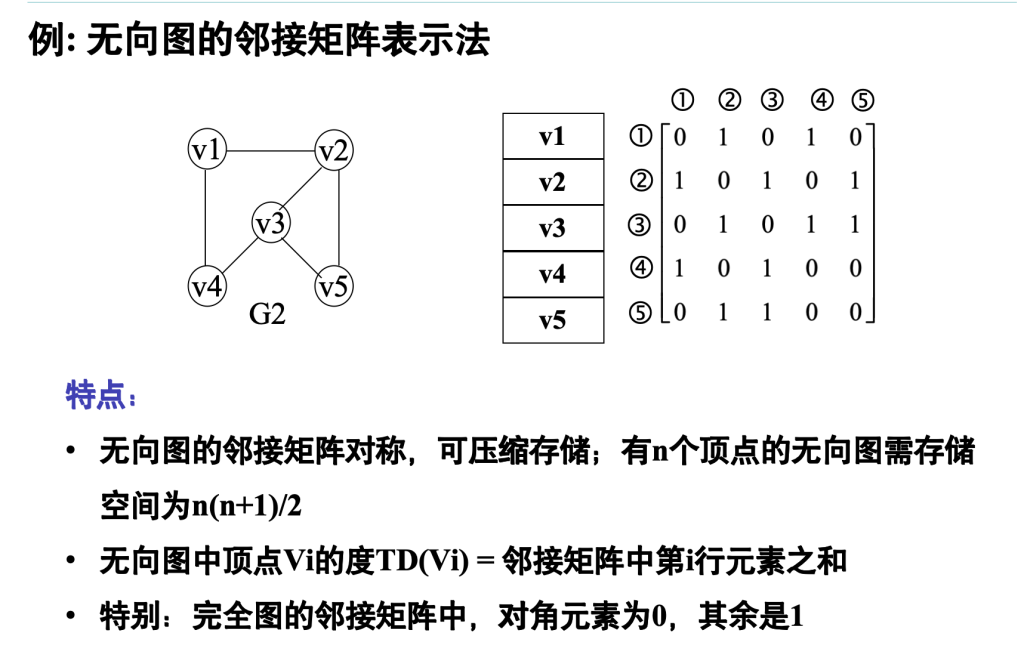
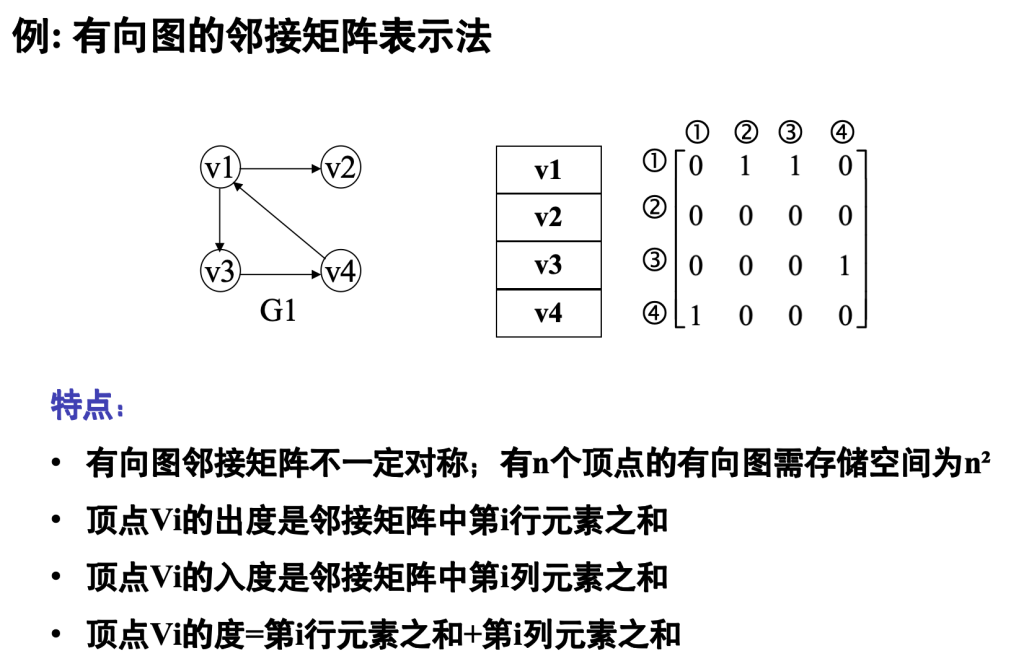
数组表示法(邻接矩阵)


邻接表表示法
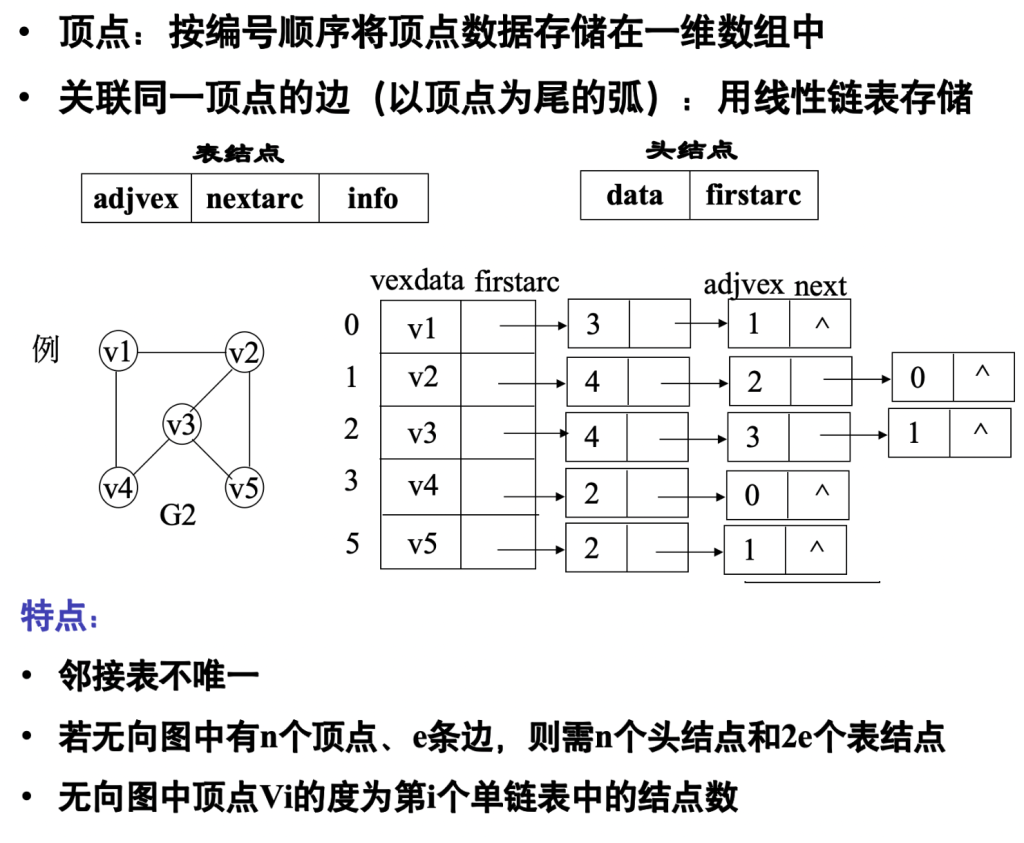
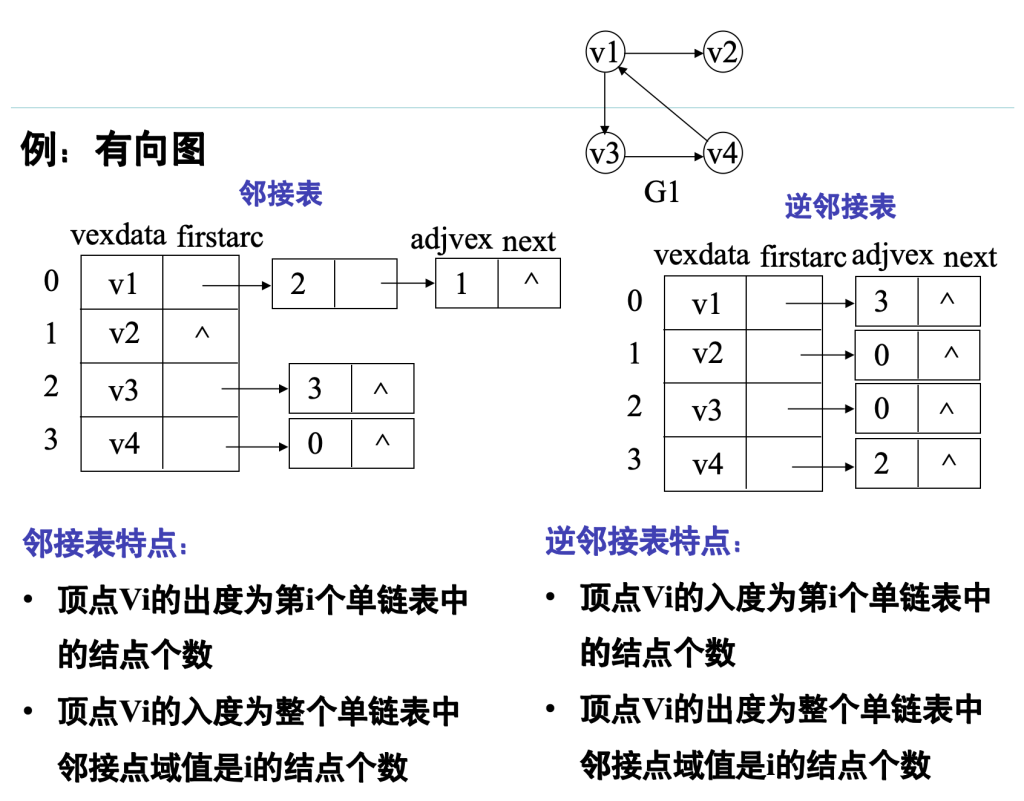

邻接表存储结构的局限性,以及针对不同图类型的改进方案
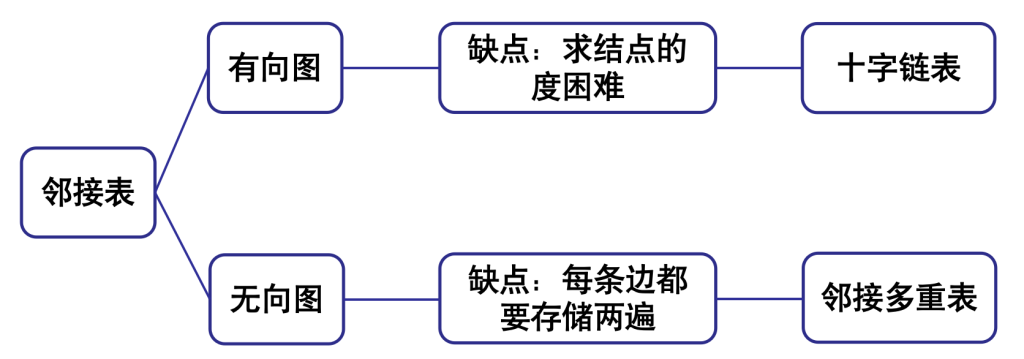
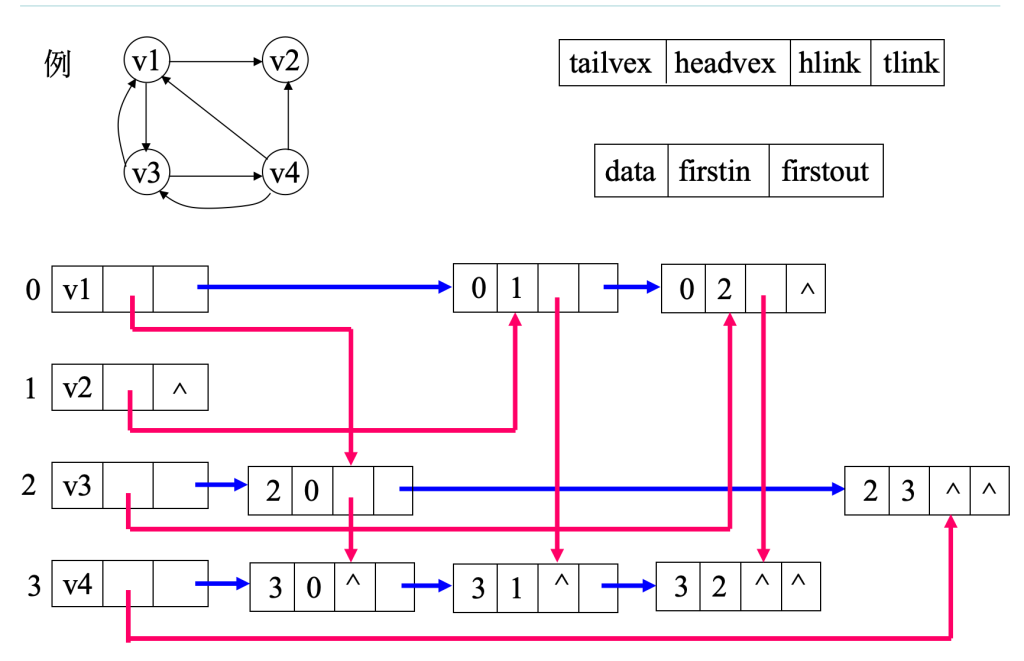
十字链表

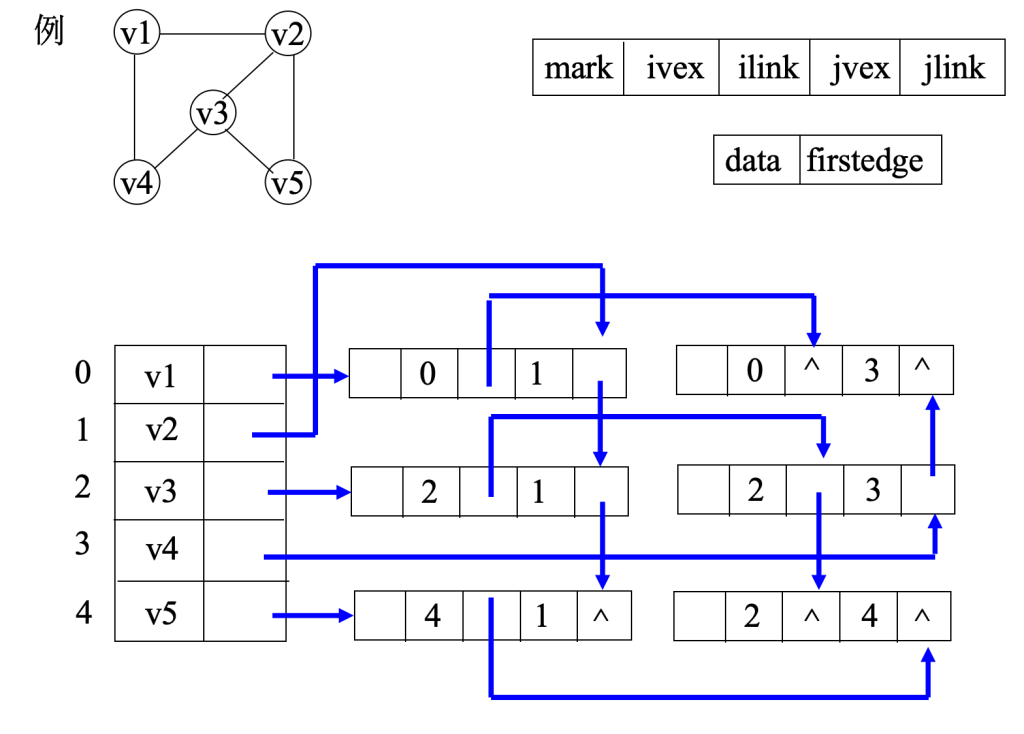
7.3 图的遍历
从图中某一顶点出发,对图中所有顶点访问一次且仅访问一次
图的遍历比树的要更复杂,因为图中可能存在回路,且图中的任一顶点都可能与其他顶点相通,在访问完某个顶点之后可能会沿着某些边又回到了曾经访问过的顶点。
怎样避免重复访问?
解决思路:设置辅助数组visited[n],用来标记顶点是否被访问过
初始状态visited[i]=0
顶点i被访问,改visited[i]为1,防止被多次访问
通常有两条遍历图的路径
- 深度优先搜索(Depth_First Search – DFS)
- 广度优先搜索(Breadth_First Search – BFS)
遍历的实质:找每个顶点的邻接点的过程
7.3.1 深度优先搜索 Depth_First Search – DFS
是树的先根遍历的推广
- 从图中某一顶点v出发,访问此顶点;
- 然后依次从v的未被访问的邻接点出发,深度优先搜索图
- 重复上述过程,直到所有与V有路径相通的顶点都被访问过
- 若此时图中尚有顶点未被访问,则另选图中一个未被访问的顶点做起点,重复上述过程,直到所有顶点都被访问过
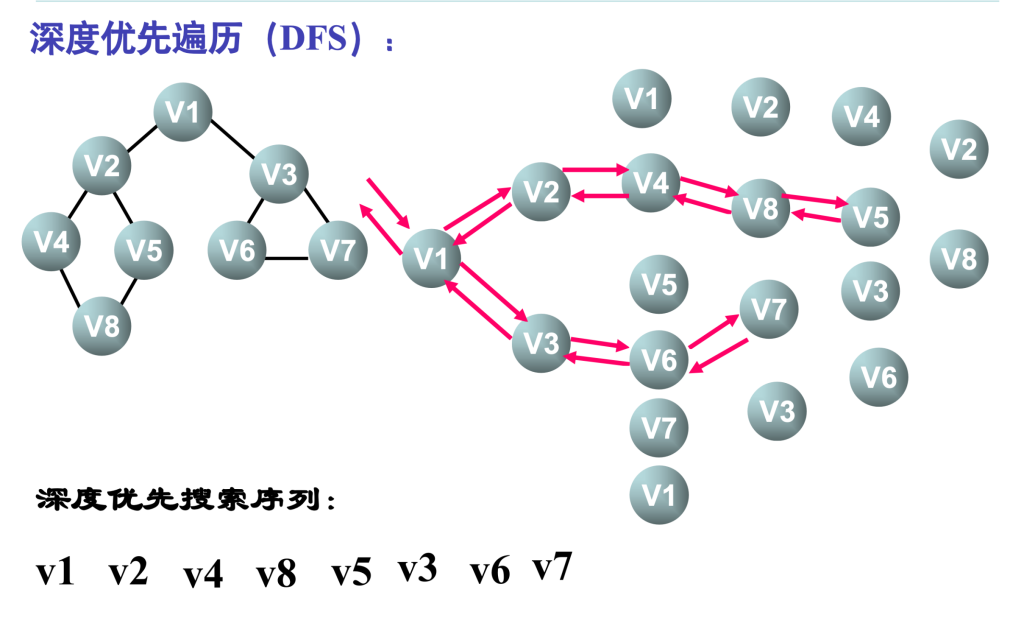
以图无向图 \(G_4\) 为例,深度优先搜索遍历图的过程如图 7.13 (b) 所示①。
假设从顶点 \(v_1\) 出发进行搜索,在访问了顶点 \(v_1\) 之后,选择邻接点 \(v_2\)。因为 \(v_2\) 未曾访问,
则从 \(v_2\) 出发进行搜索。依次类推,接着从 \(v_4, v_8 、v_5\) 出发进行搜索。在访问了 \(v_5\) 之后,由
于 \(v_5\) 的邻接点都已被访问,则搜索回到 \(v_8\)。由于同样的理由,搜索继续回到 \(v_4, v_2\) 直至
\(v_1\),此时由于 \(v_1\) 的另一个邻接点未被访问,则搜索又从 \(v_1\) 到 \(v_3\),再继续进行下去。由此,
得到的顶点访问序列为:
\(v_1 \rightarrow v_2 \rightarrow v_4 \rightarrow v_8 \rightarrow v_5 \rightarrow v_3 \rightarrow v_6 \rightarrow v_7\)
遍历操作中要解决的关键问题:
- “从图的某一顶点 V 出发”,如何选取出发顶点。解决方案:按存储结构排列顺序的第一个。
- “依次从 V 的未被访问的邻接点出发” 中 “依次”解决方案:按基本操作,先找第一邻接点,再找下一个,循环查找各邻接点。
- “未被访问的” 邻接点:解决方案:设访问标志数组 visited []
- 非连通图解决方案:从任意一个未被访问的结点出发调用算法
// 全局访问标志数组:标记顶点是否被访问
Boolean visited[ MAX ];
// 全局函数指针:指向顶点的访问操作函数
Status( *VisitFunc )( int v );
// 图的深度优先遍历(对外接口)
// 参数:G-图,Visit-顶点访问函数
void DFSTraverse (Graph G, Status (*Visit)(int v) )
{
VisitFunc = Visit; // 给全局函数指针赋值
// 初始化访问标志数组:所有顶点标记为“未访问”
for (v = 0 ; v < G.vexnnum ; ++v) visited[ v ] = FALSE;
// 遍历所有顶点(处理非连通图)
for (v = 0 ; v < G.vexnnum ; ++v)
// 若当前顶点未访问,从它开始深度优先搜索
if (!visited[ v ]) DFS (G, v);
}
// 深度优先搜索的递归实现
// 参数:G-图,v-当前访问的顶点
void DFS (Graph G, int v)
{
visited[ v ] = TRUE; // 标记当前顶点为“已访问”
VisitFunc( v ); // 执行顶点的访问操作(如输出)
// 遍历当前顶点v的所有邻接点:
// w从v的第一个邻接点开始,循环获取下一个邻接点
for(w=FirstAdjVex(G,v) ; w ; w=NextAdjVex(G,v,w) )
// 若邻接点w未访问,递归访问w
if (!visited[ w ]) DFS (G, w);
}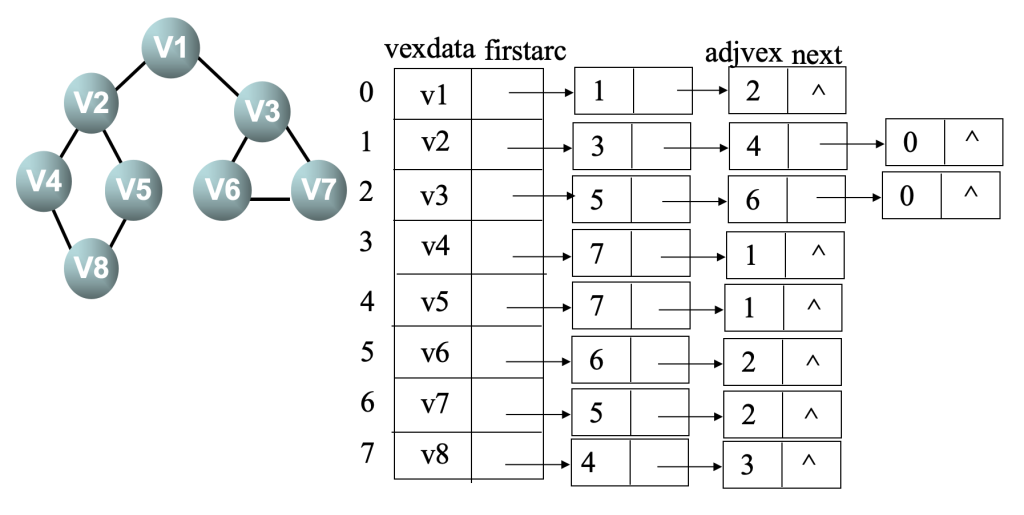
遍历图其耗费的时间则取决于所采用的存储结构。当用二维数组表示邻接矩阵作图的存储结构时,查找每个顶点的邻接点所需时间为 \(O(n^2)\),其中 n 为图中顶点数。而当以邻接表作图的存储结构时,找邻接点所需时间为 \(O(e)\),其中 e 为无向图中边的数或有向图中弧的数。由此,当以邻接表作存储结构时,深度优先搜索遍历图的时间复杂度为 \(O(n+e)\)。

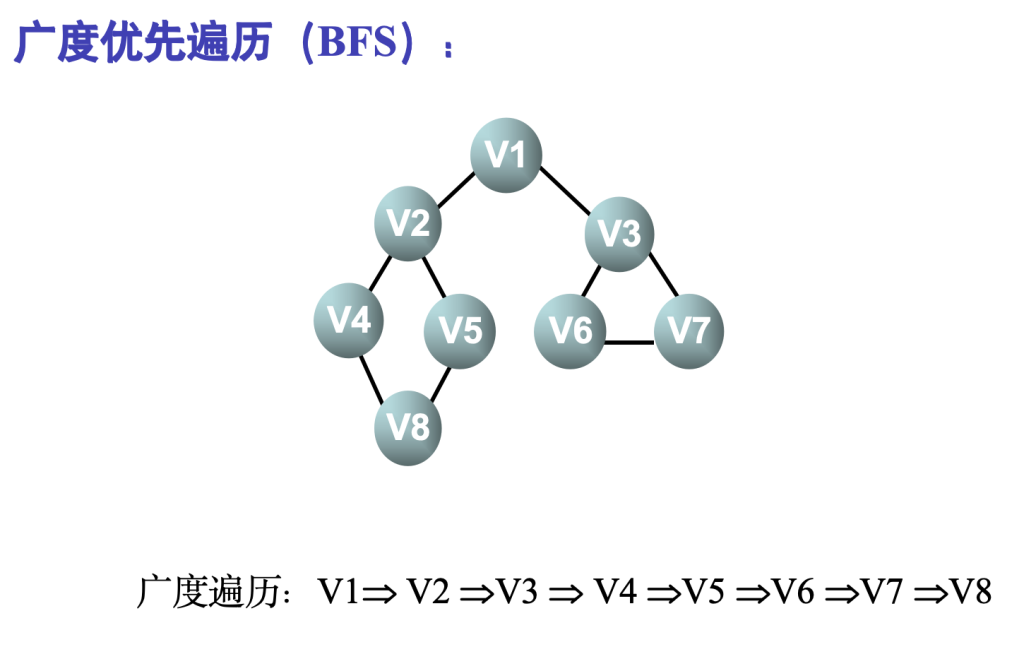
7.3.2 广度优先搜索 Breadth_First Search – BFS
类似于树按层次遍历的过程
- 从图中某一顶点v出发,访问此顶点;
- 然后访问v的各个未曾访问过的邻接点
- 然后分别从这些邻接点出发,依次访问它们的邻接点,并使“先被访问的顶点的邻接点”先于“后被访问的顶点的邻接点”被访问,直至图中所有已被访问的顶点的邻接点都被访问到
- 若此时图中尚有顶点未被访问,则另选图中一个未被访问的顶点作起点,重复上述过程,直到所有顶点都被访问过。
// 图的广度优先遍历(对外接口)
// 参数:G-图,visit-顶点访问函数(如输出顶点)
void BFSTraverse(Graph G, Status(*visit)(int v))
{
// 初始化访问标志数组:所有顶点标记为“未访问”
for (v = 0 ; v < G.vexnnum ; ++v )
visited[ v ] = FALSE;
// 初始化一个队列(用于暂存待处理的顶点)
InitQueue( Q );
// 遍历所有顶点(处理非连通图)
for (v = 0 ; v < G.vexnnum ; ++v )
// 若当前顶点未访问,从它开始广度优先搜索
if (!visited[ v ]) {
visited[ v ] = TRUE; // 标记当前顶点为“已访问”
visit(v); // 执行顶点的访问操作
EnQueue ( Q, v ); // 将当前顶点入队(后续处理它的邻接点)
// 队列非空时,循环处理队列中的顶点
while (!QueueEmpty( Q )) {
DeQueue( Q, u ); // 取出队头顶点u
// 遍历u的所有邻接点w
for(w=FirstAdjVex(G,u); w; w=NextAdjVex(G,u,w))
// 若邻接点w未访问
if (!visited[ w ]) {
visited[ w ] = TRUE; // 标记w为“已访问”
visit(w); // 访问w
EnQueue(Q,w); // 将w入队(后续处理w的邻接点)
} // if
} // while
} // if
}时间复杂度:邻接矩阵存储:\(O(n^2)\)(n 是顶点数)
邻接表存储:\(O(n+e)\)(e 是边 / 弧的数量)
分析上述算法,每个顶点至多进一次队列。遍历图的过程实质上是通过边或弧找邻接点的过程,因此广度优先搜索遍历图的时间复杂度和深度优先搜索遍历相同,两者不同之处仅仅在于对顶点访问的顺序不同
7.4 图的连通性问题
无向图的连通分量和生成树
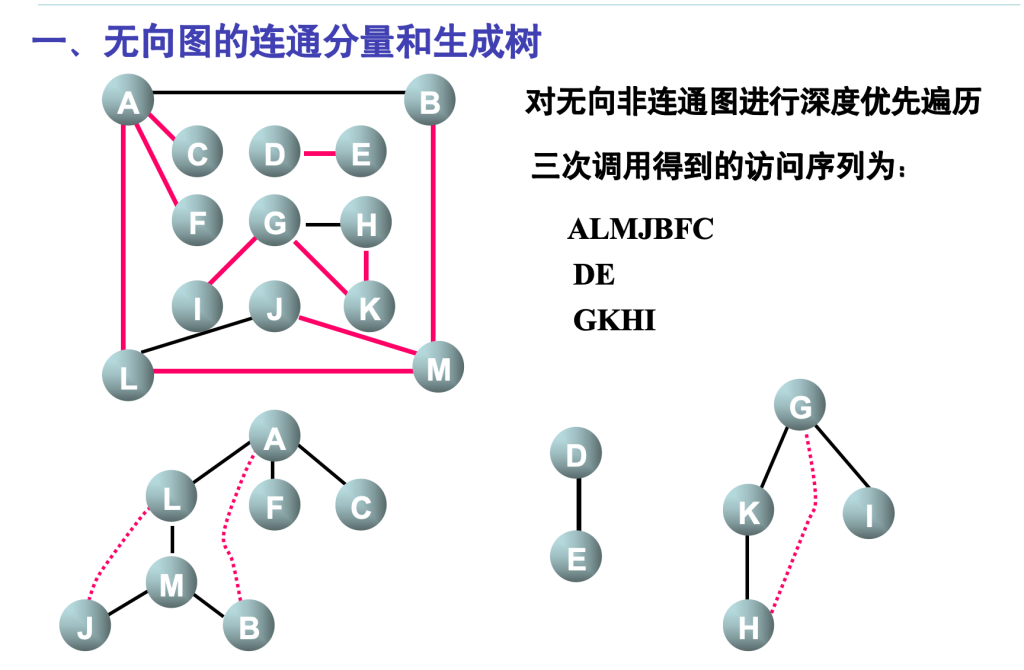
一个图可以有许多棵不同的生成树
所有生成树具有以下共同特点:
生成树的顶点个数与图的顶点个数相同
生成树是图的极小连通子图
一个有n个顶点的连通图的生成树有n-1条边
生成树中任意两个顶点间的路径是唯一的
在生成树中再加一条边必然形成回路
含n个顶点n-1条边的图不一定是生成树
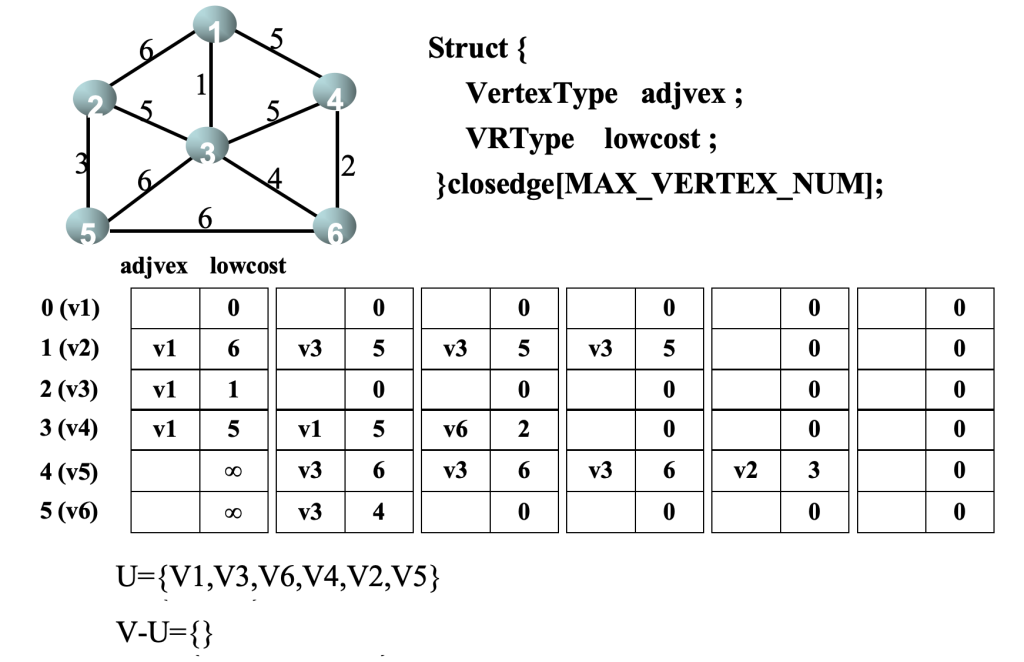
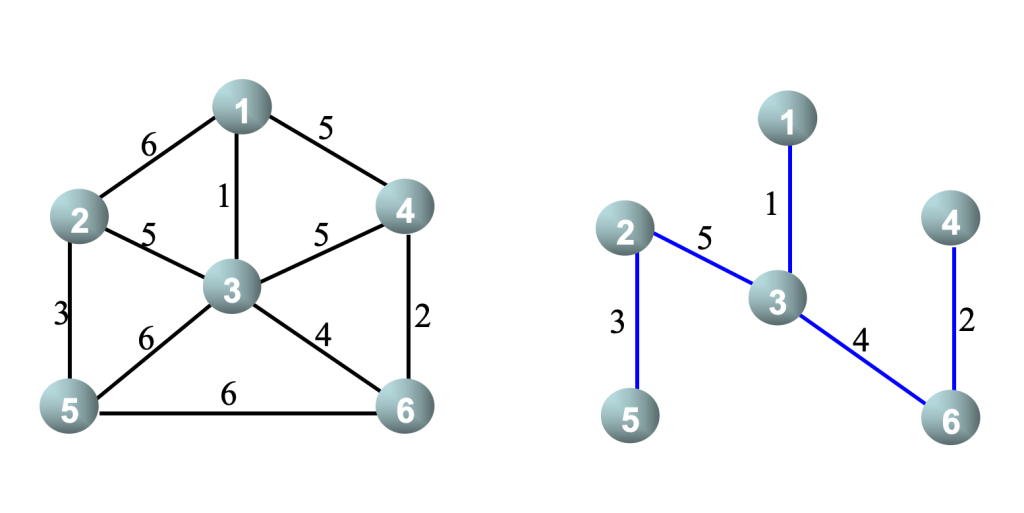
最小生成树



7.5 有向无环图及其应用
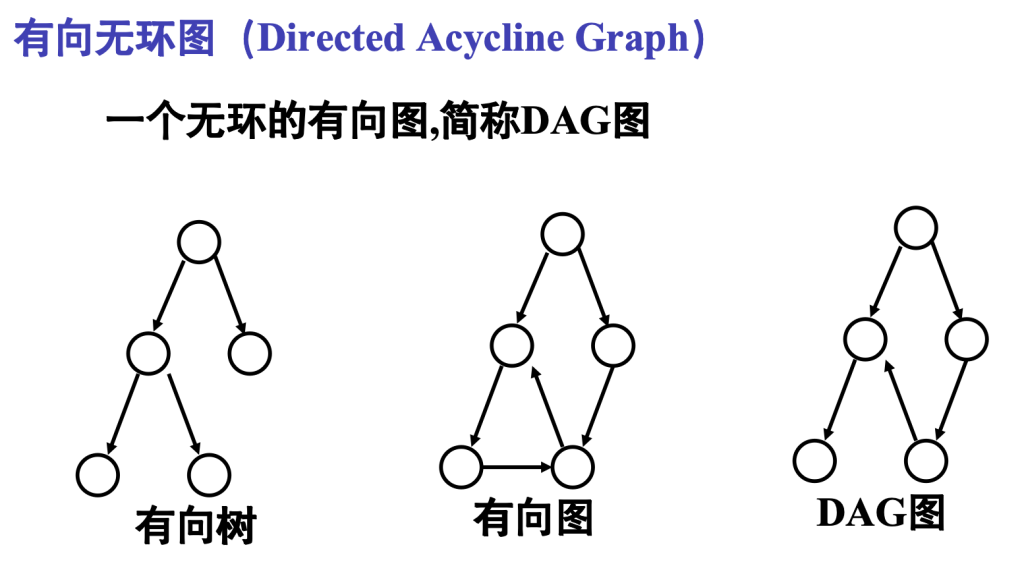
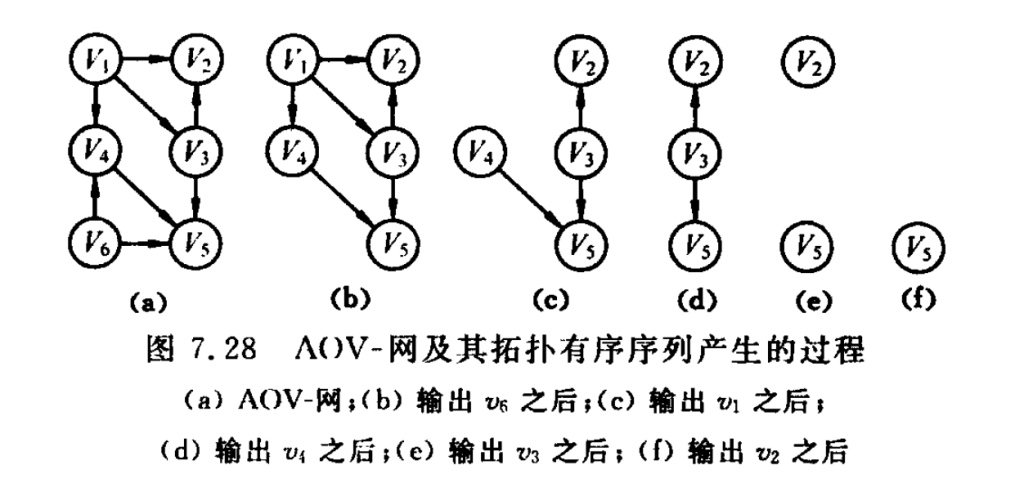
拓扑排序
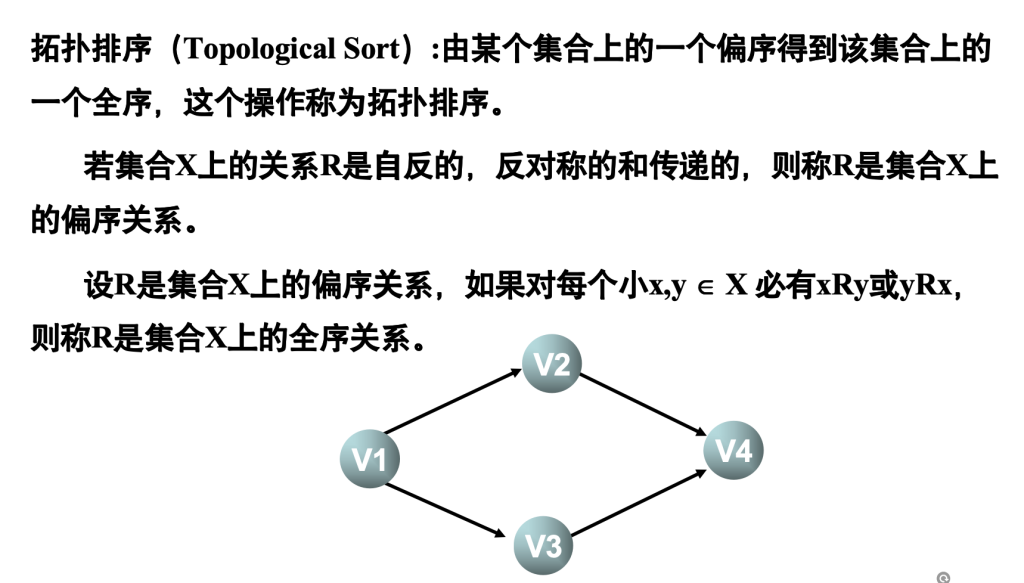
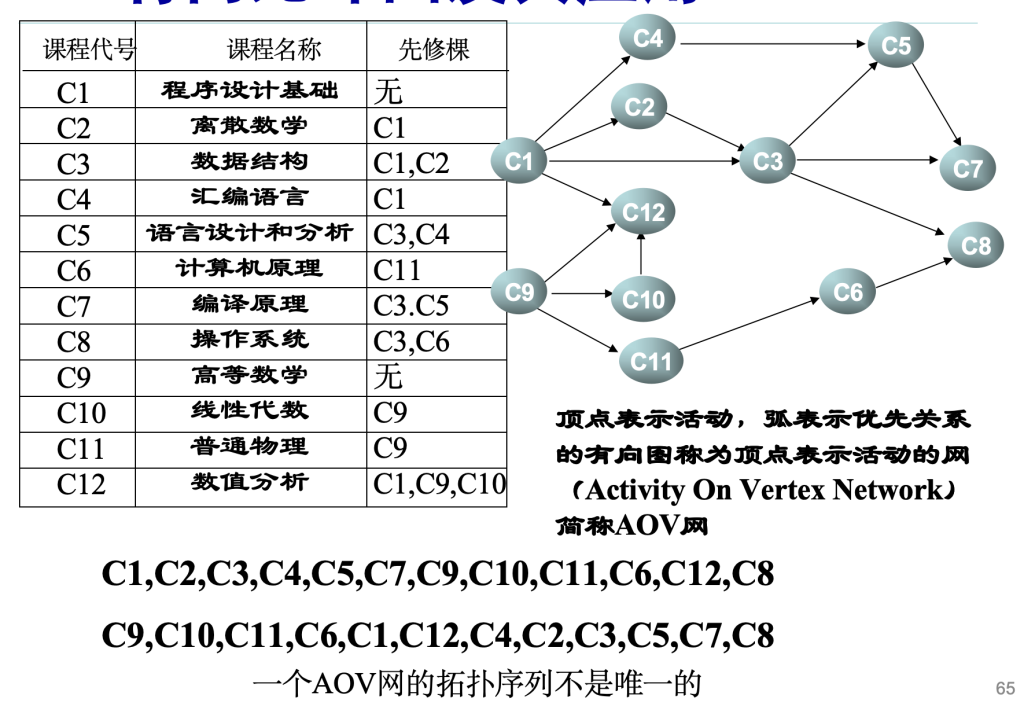
学生选修课程问题
顶点——表示课程
有向弧——表示先决条件,若课程i是课程j的先决条件,则图中有弧<i,j>
学生应按怎样的顺序学习这些课程,才能无矛盾、顺利地完成学业——拓扑排序

关键路径
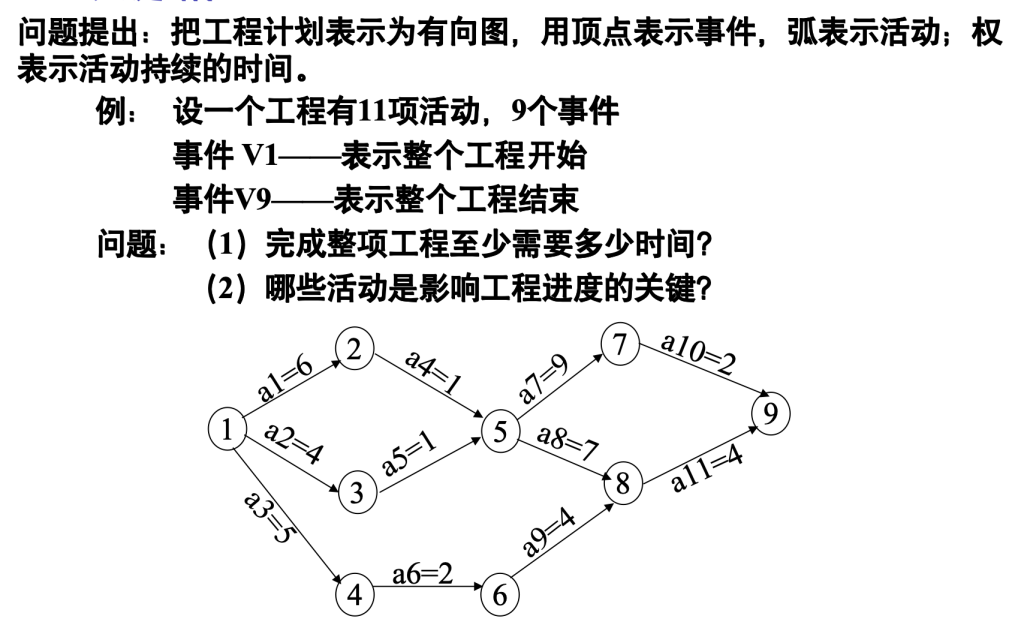

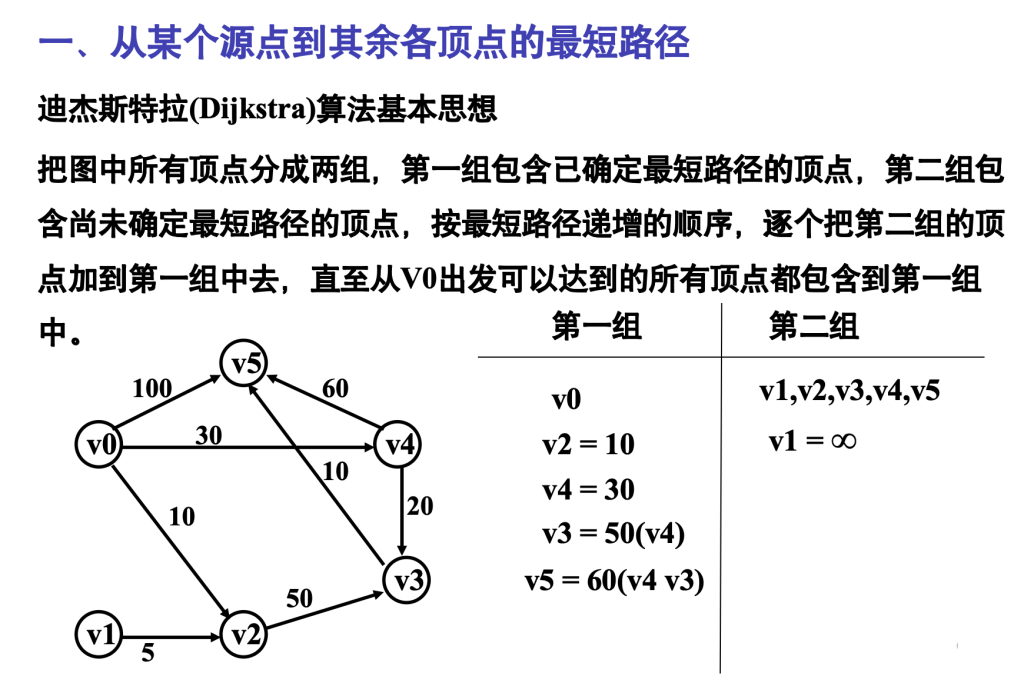
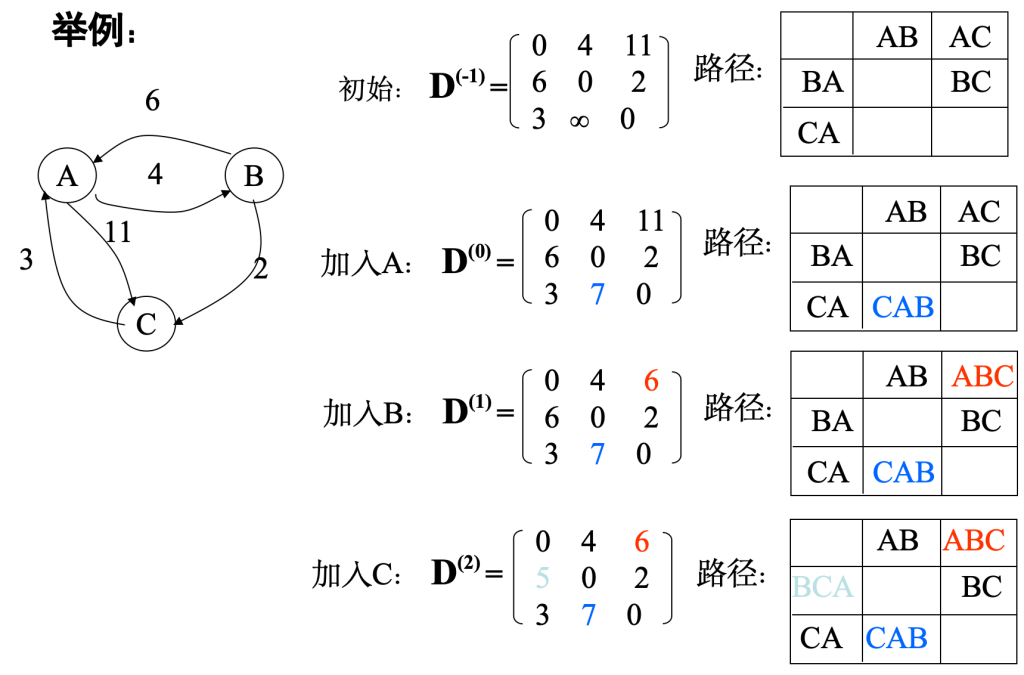
7.6 最短路径