本文最后更新于280 天前,其中的信息可能已经过时,如有错误请留言
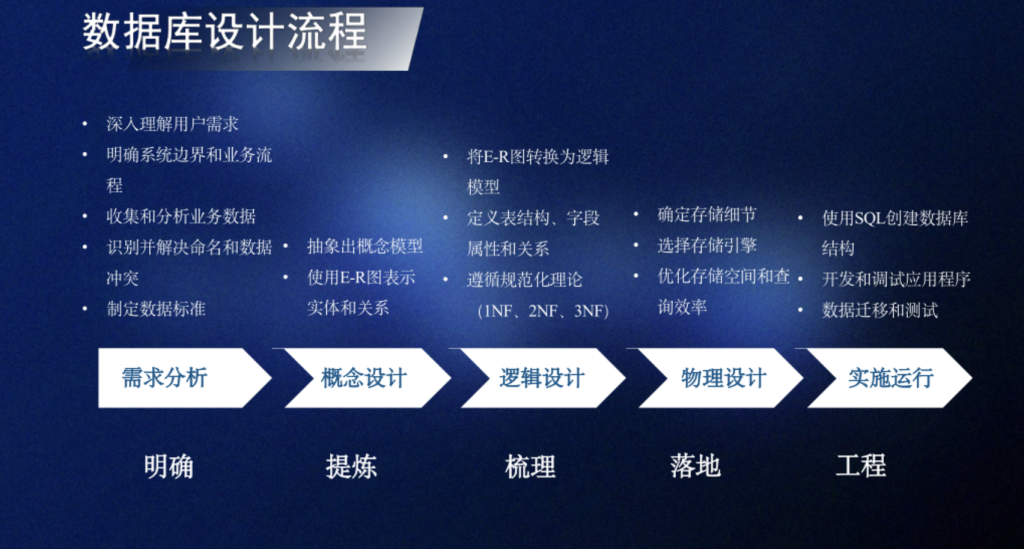
超参数优化
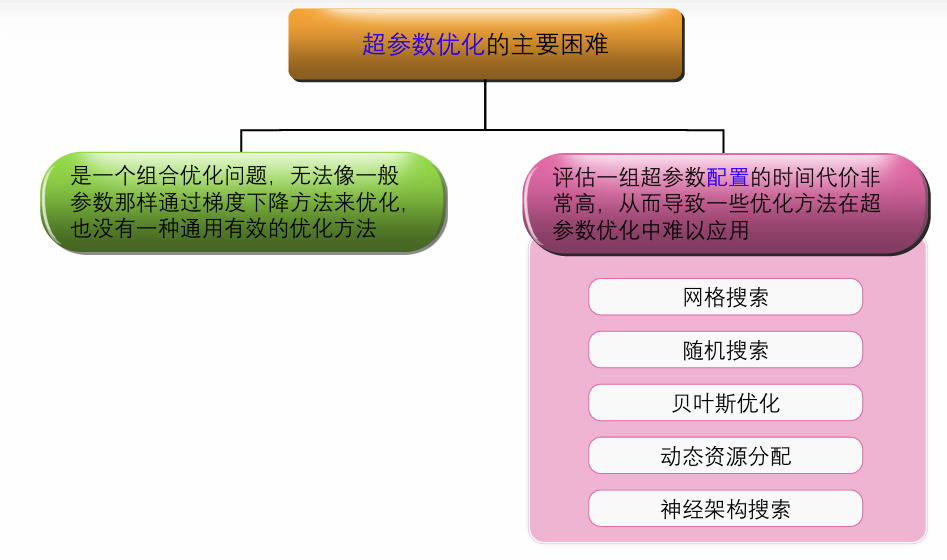
在神经网络中,除了可学习的参数之外,还存在很多超参数,对网络性能的影响也很大不同的机器学习任务往往需要不同的超参数






网络正则化 Regularization
由于神经网络的拟合能力非常强,模型训练的目标是最小化损失函数,其在训练数据上的错误率往往都可以降到非常低,甚至可以到0,从而导致过拟合
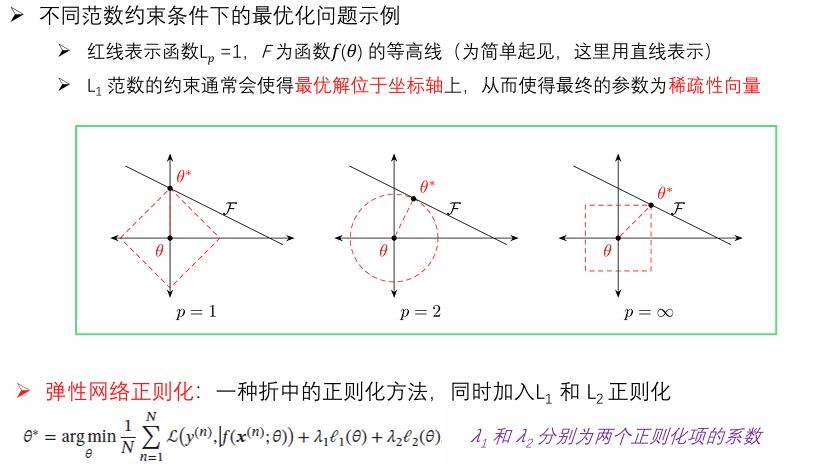
正则化的核心思想是通过在损失函数中添加额外的 “正则项”(如 L1 正则、L2 正则),对模型参数进行 “约束” 或 “惩罚”,限制模型复杂度(例如让参数值更小、更稀疏),从而降低模型复杂度,提升泛化能力。
L1和L2正则化

权重衰减(Weight Decay)

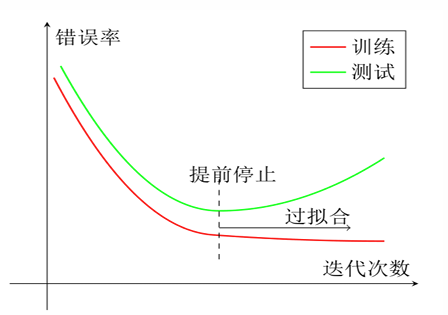
提前停止(Early Stop)
使用梯度下降法进行优化时,可以用验证集上的错误来代替期望错误.当验证集上的错误率不再下降,就停止迭代在实际操作中,验证集上的错误率变化曲线并不一定是平衡曲线,很可能是先升高再降低,因此提前停止的具体停止标准需要根据实际任务进行优化
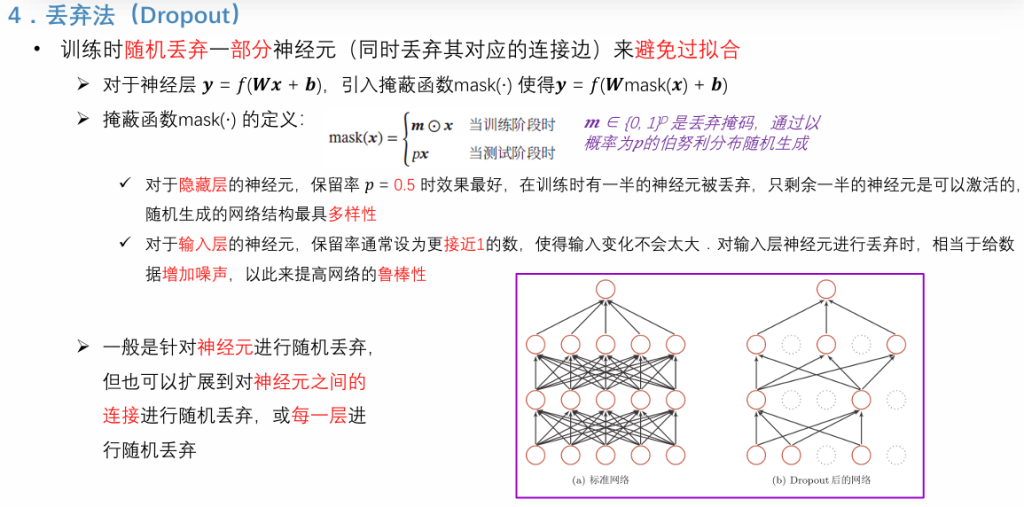
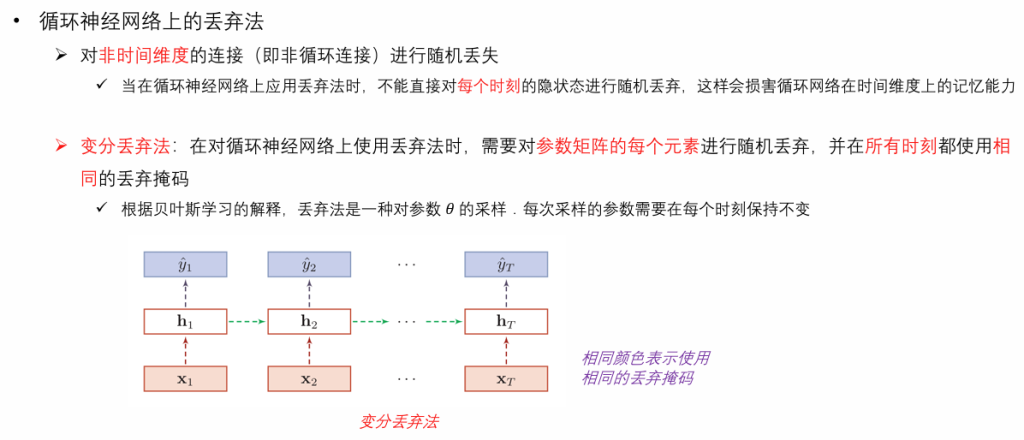
丢弃法(Dropout)

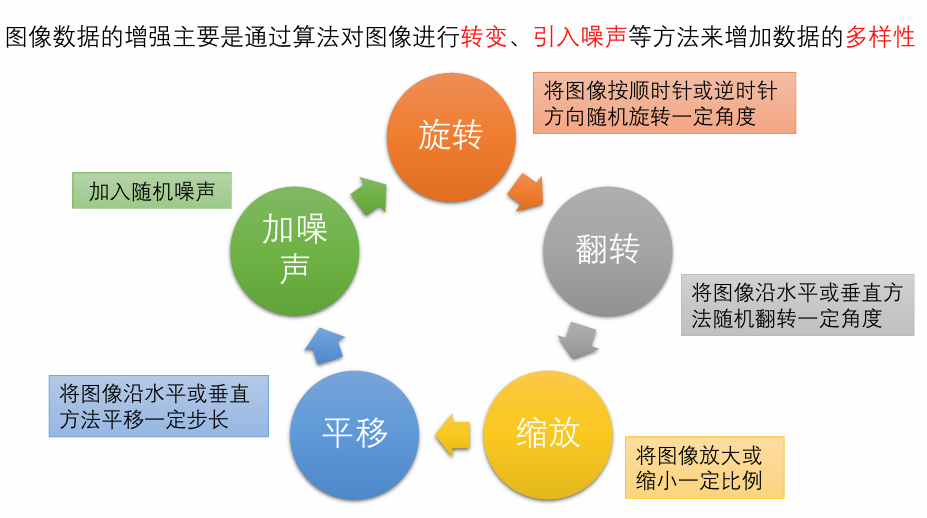
数据增强(Data Augmentation)
标签平滑(Label Smoothing)