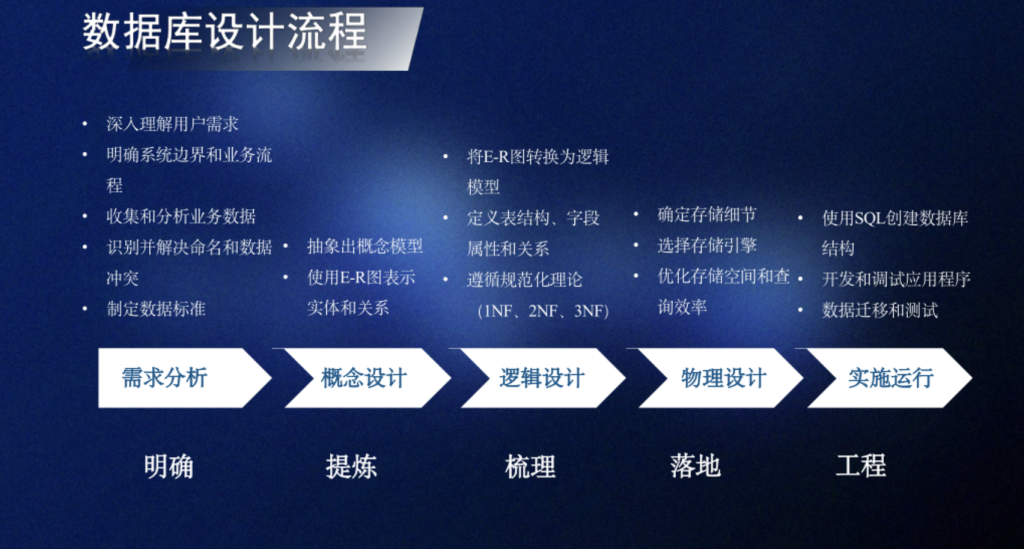
线性结构的特点:
- 唯一 “第一个” “最后一个” 数据元素
- 除第一个外,集合中的每个数据元素均只有一个前驱
除最后一个外,集合中的每个数据元素均只有一个后继
线性表的类型定义:同一种数据元素组成的一个有限序列
一个数据元素可以由若干个数据项item(记录record)组成
同一个线性表里放的每个元素,都是同一种“对象类型/数据类型”的实例(

- InitList(&L)
- 操作结果:构造一个空的线性表 L
- DestroyList (&L)
- 初始条件:线性表 L 已经存在
- 操作结果:销毁线性表 L
- ClearList (&L)
- 初始条件:线性表 L 已经存在
- 操作结果:将线性表 L 重置为空表
- ListEmpty(L)
- 初始条件:线性表 L 已经存在
- 操作结果:若线性表 L 为空表,返回 TRUE;否则返回 FALSE
- ListLength (L)
- 初始条件:线性表 L 已经存在
- 操作结果:返回线性表 L 中的数据元素个数
- GetElem (L, i, &e)
- 初始条件:线性表 L 已经存在,1<=i<=Listlength (L)
- 操作结果:用 e 返回线性表 L 中第 i 个数据元素的值
- LocateElem(L, e, compare()):
- 初始条件:线性表 L 已经存在,compare () 是数据元素判定函数
- 操作结果:返回 L 中第一个与 e 满足 compare () 的数据元素的位序。若不存在,返回 0
- PriorElem (L, cur_e, &pre_e)
- 初始条件:线性表 L 已经存在
- 操作结果:若 cur_e 是 L 的数据元素,且不是第一个,则用 pre_e 返回它的前驱,否则操作失败,pre_e 无定义
- NextElem(L, cur_e, &next_e):
- 初始条件:线性表 L 已经存在
- 操作结果:若 cur_e 是 L 的数据元素,且不是最后一个,则用 next_e 返回它的后继,否则操作失败,next_e 无定义
- ListInsert(&L, i, e)
- 初始条件:线性表 L 已经存在,1<=i<=Listlength (L)+1
- 操作结果:在 L 中第 i 个位置之前插入新的数据元素 e,L 的长度加 1
- ListDelete(&L, i, &e):
- 初始条件:线性表 L 已经存在且非空,1<=i<=Listlength (L)
- 操作结果:删除 L 的第 i 个数据元素,并用 e 返回其值,L 的长度减 1
- ListTraverse(L, visit())
- 初始条件:线性表 L 已经存在
- 操作结果:依次对 L 中的每个数据元素调用函数 visit ()。一旦 visit () 失败,则操作失败
以上所提及的运算是逻辑结构上定义的运算。只给出这些运算的功能是 “做什么”,至于 “如何做” 等实现细节,只有确定了存储结构之后才考虑。
线性表的 “插入元素” 操作,在逻辑上只是规定要把元素放到某个位置,但如果是顺序存储(比如数组),插入时可能需要大量移动后续元素来腾位置;如果是链式存储(比如链表),插入时只需要修改几个指针的指向。所以必须确定了存储结构,才能去考虑 “如何做” 这些操作的具体实现细节。
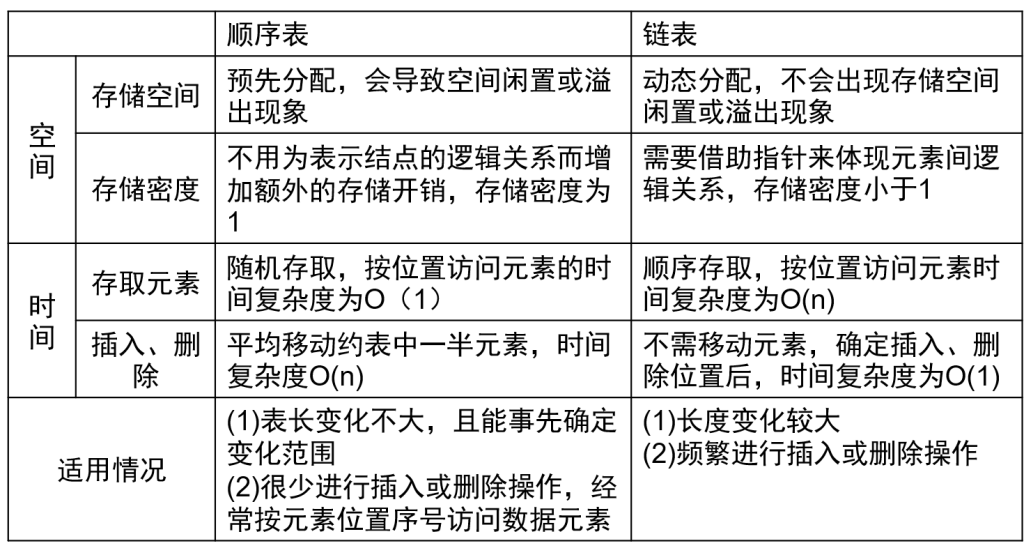
顺序表 – 线性表的顺序表示和实现
定义:线性表的逻辑结构 + 顺序存储结构(线性表的顺序表示),这种线性表称为顺序表
特点:以物理位置相邻表示逻辑关系,因此只要确定了存储线性表的起始未知,线性表中任一数据元素可随机存取,因此线性表的顺序存储结构是一种随机存取的存储结构
随机存取
随机存取可以直接通过 “下标”,在 \(O(1)\) 时间内获取任意位置的元素
比如数组 arr,要访问第 i 个元素,直接通过 arr[i] 就能瞬间定位,不需要遍历前面的元素,因为存储空间连续且大小相同
在高级程序设计语言中,通常用数组表示顺序存储的线性表
都有地址连续,随机存取,类型相同的特性
不同的是线性表的长度可变,但数组长度不可动态定义,可用一种动态分配的一维数组

数组指针elem指示线性表的基地址,一旦因插入元素而空间不足时,可进行再分配:
为顺序表增加一个大小为存储LISTINCREMENT个数据元素的空间

线性表,顺序表,数组的关系
- 线性表:抽象概念(逻辑结构)——一串有序元素 (a_1,\dots,a_n)
- 顺序存储的线性表(顺序表):线性表的顺序存储实现(物理结构)
- 数组:实现顺序表的常见载体(但数组≠顺序表,数组只是顺序表实现的载体)
- 数组 = 一排固定的格子(有编号)
- 顺序表 = 这排格子 + 以及一套规则(插删查)
- 他们的共同点:连续存储 + 下标访问 + 中间插入/删除都需要移动其他元素
插入操作
线性表的插入是指在第 i(1 ≤ i ≤ n+1)个元素之前插入一个新的数据元素 e,使长度为 n 的线性表
(a₁, a₂, … aᵢ₋₁, aᵢ … aₙ)变成 (a₁, a₂, … aᵢ₋₁, e, aᵢ … aₙ)
表长度变为 n+1
数据元素 aᵢ₋₁和 aᵢ 之间的逻辑关系发生了变化相应存储结构也要发生变化:
- 判断插入位置 i 是否合法
- 判断线性表的存储空间是否已满,若已满需要重新分配空间
- 将第 n 至第 i 位的元素(共 n-i+1) 个元素依次向后移动一个位置,空出第 i 个位置
- 将要插入的新元素 e 放入第 i 个位置
- 表长加 1,插入成功返回 OK
Status ListInsert_Sq (SqList &L, int i, ElemType e) {
if (i < 1 || i > L.length + 1) return ERROR; // i值不合法
if (L.length >= L.listsize) { // 当前存储空间已满,增加分配
newbase = (ElemType *) realloc (L.elem,
(L.listsize + LISTINCREMENT) * sizeof(ElemType));
if (!newbase) exit (OVERFLOW); // 存储分配失败
L.elem = newbase; // 新基址
L.listsize += LISTINCREMENT; // 增加存储容量
}
q = &(L.elem[i - 1]); // q为插入位置
for (p = &(L.elem[L.length - 1]); p >= q; --p)
*(p + 1) = *p; // 插入位置及之后的元素右移
*q = e; // 插入e
++L.length; // 表长加1
return OK;
}如果在第 i 个位置插入,需要移动的元素个数是:L.length – (i-1) = n – i + 1
在顺序存储结构的线性表中插入一个元素,约平均需移动表中一半元素
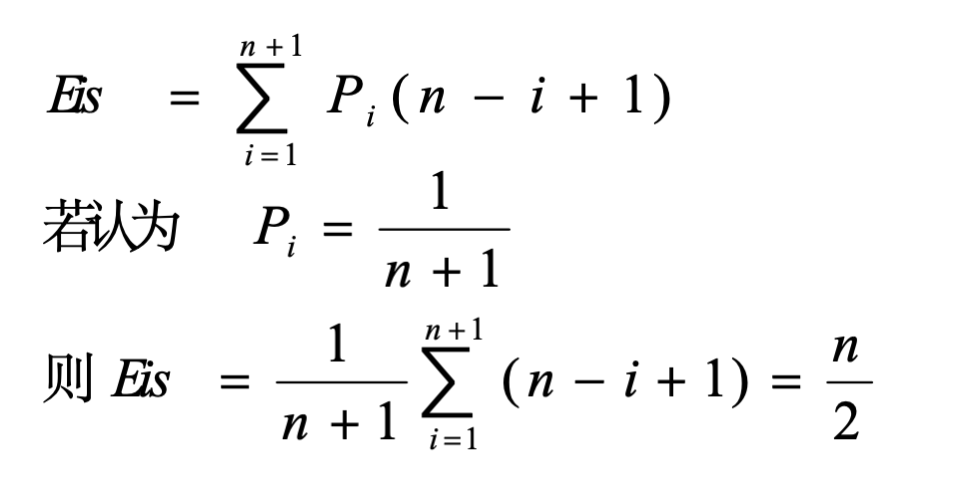
具体移动元素主要取决于插入位置(插入点在表中的位置分布),并与当前表长 n 有关。
∴ 时间复杂度为 \(O(n)\)
删除操作(ListDelete(&L,i, &e)):
将第 i(1 ≤i≤ n)个元素删除,使长度为 n 的线性表(a₁, a₂, … aᵢ₋₁, aᵢ, aᵢ₊₁… aₙ)变成 (a₁, a₂, … aᵢ₋₁, aᵢ₊₁… aₙ)表长度变为 n – 1
数据元素 aᵢ₋₁和 aᵢ₊₁之间的逻辑关系发生了变化相应存储结构也要发生变化
删除第 i (1<=i<=n) 个元素时,需将第 i+1 至第 n (共 n – i) 个元素向前移动一个位置
Status ListDelete_Sq ( SqList &L, int i, ElemType &e ) {
if ( i < 1 || i > L.length ) return ERROR; // i值不合法
p = &( L.elem [ i - 1 ] ) ; // p为被删除元素的位置
e = * p ; // 被删除元素的值赋给e
q = L.elem + L.length - 1 ; // 表尾元素的位置
for ( ++p ; p <= q ; ++p )
* ( p - 1 ) = * p ; // 被删除元素之后的元素左移
-- L.length ; // 表长减1
}同理可得时间复杂度为 \(O(n)\)
在顺序存储结构的线性表中删除一个元素,约平均需移动表中一半元素
线性表的查找(LocateElem(L, e, compare()):
查找第 1 个值与 e 满足 compare () 的元素的位置
从第一个元素开始,逐个查找直到找到或表结束为止
int LocateElem_Sq ( SqList L, ElemType e,
Status ( * compare ) ( ElemType, ElemType )) {
i = 1 ;
p = L.elem ;
while ( i <= L.length && ! ( *compare )( * p ++, e )) ++i ;
if ( i <= L.length ) return i ;
else return 0 ;
}时间复杂度:O (n)
顺序存储结构的特点
优点
- 逻辑关系相邻,物理位置相邻
- 可随机存取任一元素
- 存储空间使用紧凑
缺点
- 插入、删除操作需要移动大量的元素
- 分配空间需按固定大小分配,利用不充分
链表 – 线性表的链式表示和实现
是线性表的链式存储实现,包括
- 单链表
- 双链表(每个结点除了有指向后继结点的指针,还有指向前驱结点的指针 )
- 循环链表(单链表或双链表的基础上,让最后一个结点的指针指向头结点,形成一个环形结构 )
- 双向循环链表
数据域存储本身信息,还需指针域存储存储后继存储位置
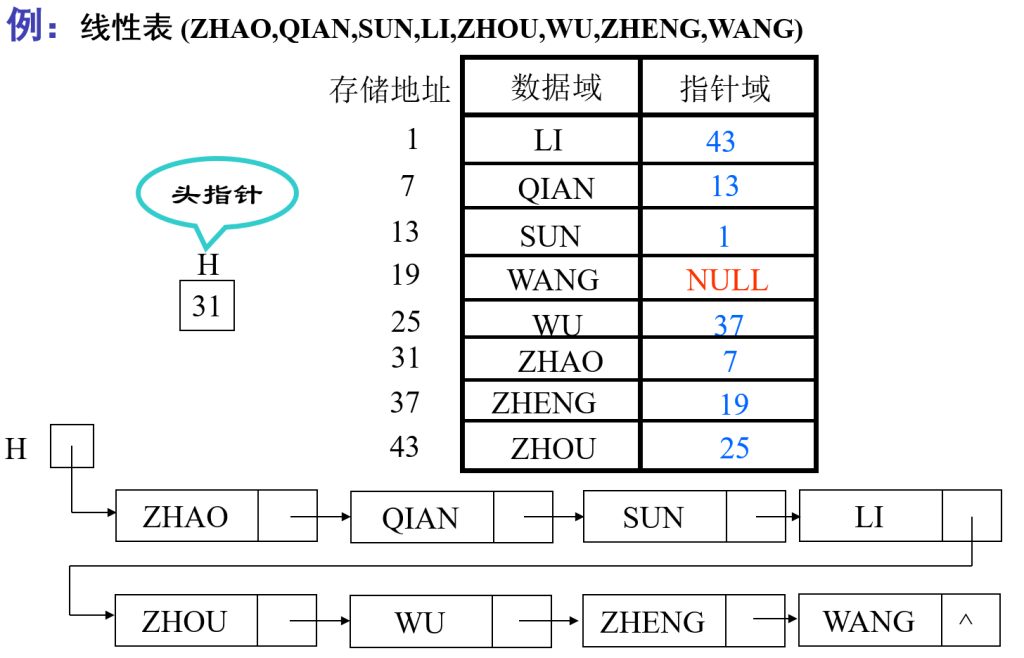
特点:
- 逻辑上相邻的数据元素在物理上不一定相邻,指针表示数据元素之间的逻辑关系
- 访问时只能通过头指针进入链表,并通过每个结点的指针域依次向后顺序扫描其余结点,所以寻找第一个结点和最后一个结点所花费的时间不同(顺序存取),所以代价是不能随机存取,查找速度慢
- 数组是静态结构
需预先分配连续固定大小的存储空间(如int arr[100]预分配存 100 个int的连续空间)
数据量超预分配时,要重新申请更大空间并复制原数据,操作繁琐;数据量少则会浪费空间
单链表是动态结构
无需提前分配空间。添加节点时,可通过内存分配函数(如 C 的malloc)动态申请单个节点空间,节点存数据和指向下一节点的指针,各节点空间可离散,由指针串联。不需要节点时,用free动态释放空间,能灵活根据数据增减调整,避免空间浪费或不足- 指针占用额外存储空间
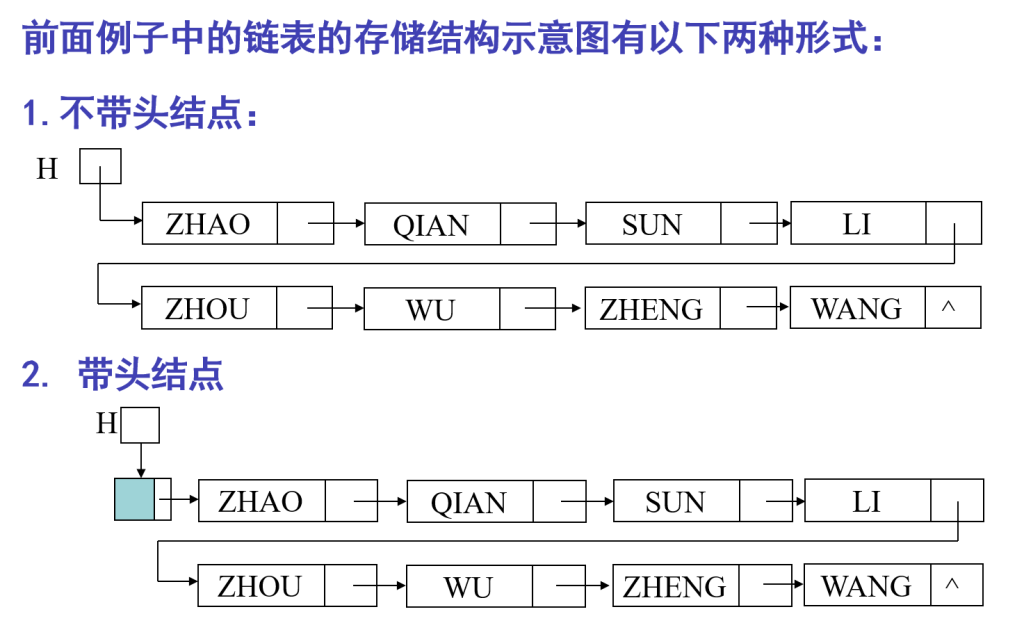
头指针,头结点
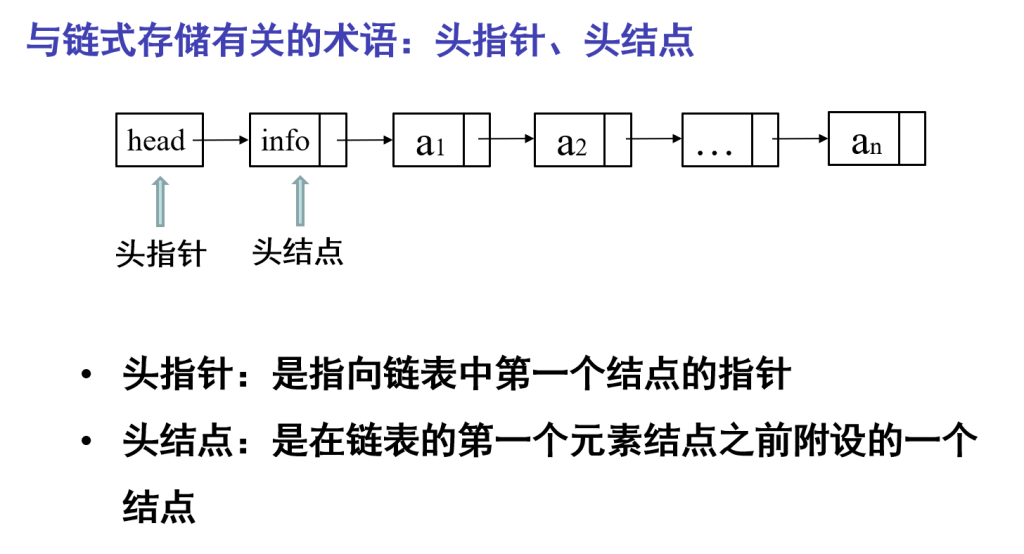
头结点的数据域可以不存储任何信息,头结点的指针域存储指向第一个元素结点的存储位置
作用是使所有链表(包括空表)的头指针非空,并使对单链表的插入、删除操作不需要区分是否为空表或是否在第一个位置进行,从而与其他位置的插入、删除操作一致。
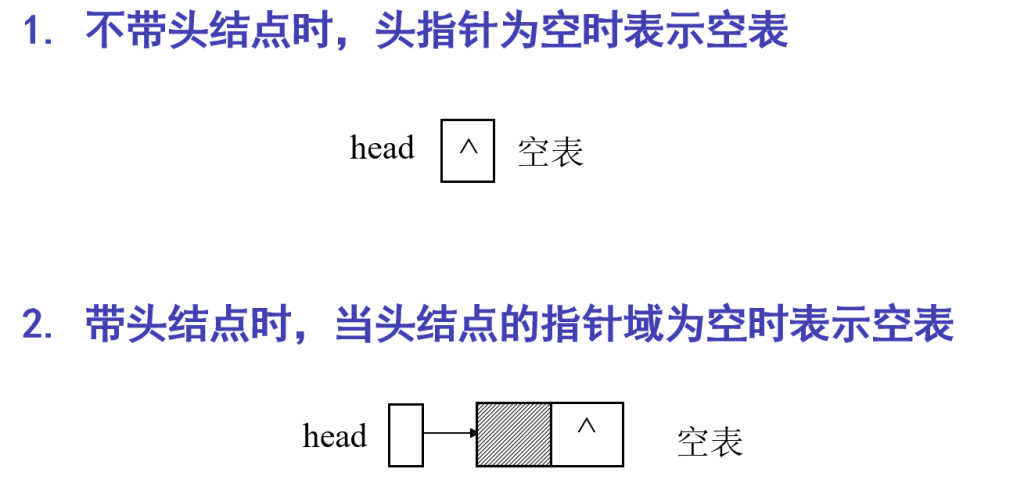
表示空表
单链表
结点中只含一个指针域的链表
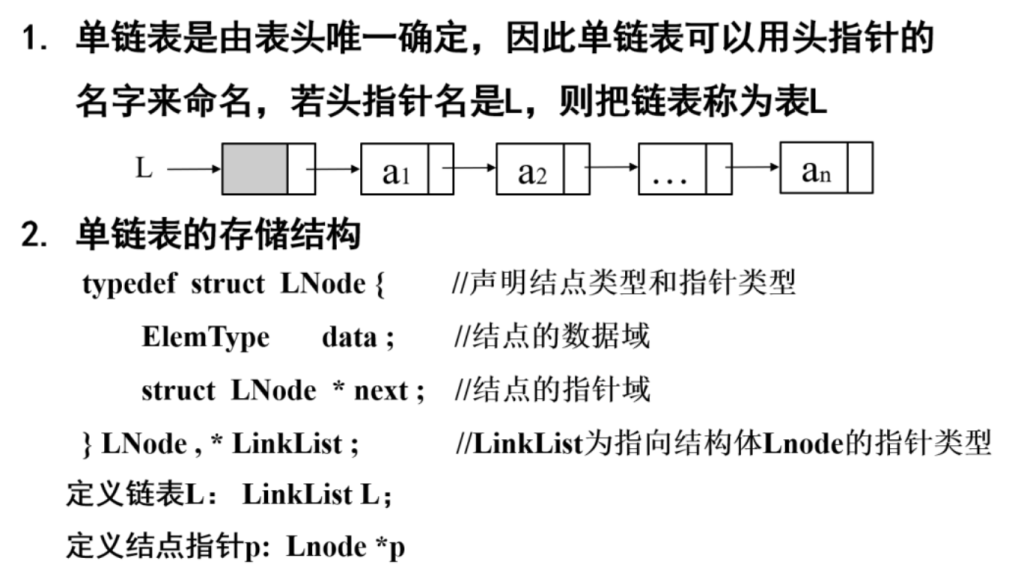
struct LNode *next 是一个指向LNode结构体类型对象的指针,可以省略struct关键字,存储的是下一个LNode结构体对象即我们所说的结点,其中包含着下一个结点的值和下下一个结点的地址
为什么说单链表由表头唯一确认:
只要给定一个表头(头指针),就能通过第一个结点的指针域找到第二个结点,最终能访问到单链表中的所有结点,最终得到一个完整且唯一的单链表结构,不会有第二种可能
查找操作

非随机存取的访问时间复杂度和随机存取的时间复杂度都是O(n),区别在哪里,优势是什么?
“O(n)”说的是:不知道目标在哪,要“查找”一个满足条件的元素(查找问题)
真正的区别:访问第 i 个元素的复杂度不同
随机存取(数组/顺序表)
- 已知下标 i,访问 a[i]:O(1)不用从头走到 i。
非随机存取(链表)
- 想访问第 i 个元素:必须从头一个个 next 走到 i:O(n)
所以随机存取的优势不是“查找更快”,而是定位第 i 个元素更快。
插入操作
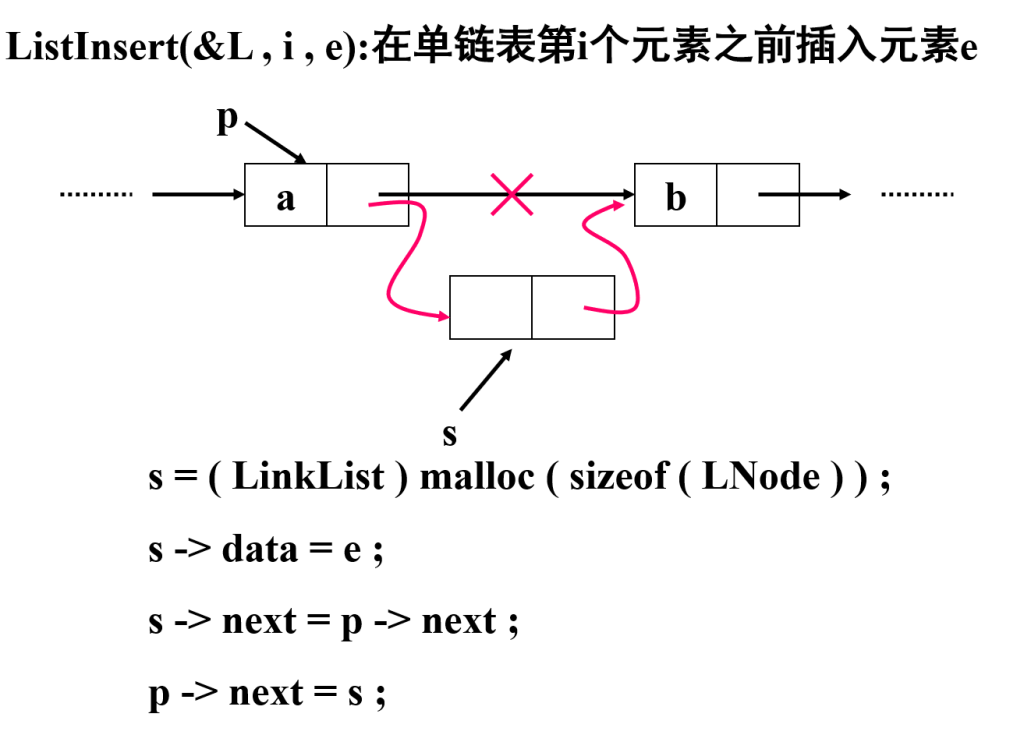
Status ListInsert_L(LinkList &L, int i, ElemType e)
{
p = L;
j = 0;
// 寻找第i-1个结点,p指向该结点
while (p && j < i - 1)
{
p = p->next;
++j;
}
// 若i值不合法(i < 1或i > 表长+1),返回错误
if (!p || j > i - 1)
return ERROR;
// 创建新结点s
s = (LinkList)malloc(sizeof(LNode));
s->data = e; // 存入数据e
s->next = p->next; // 新结点指向原第i个结点
p->next = s; // 原第i-1个结点指向新结点
return OK;
}不用移动元素,但由于不能随机存取元素,故需查找第 i 个元素,算法的时间复杂度为:O (n)
删除操作
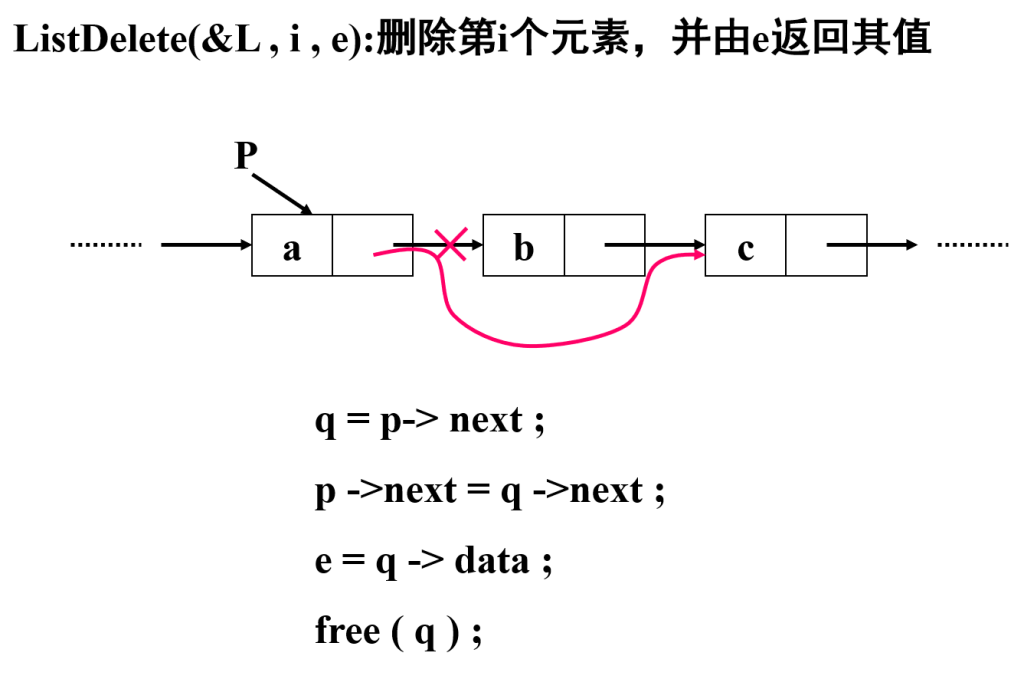
Status ListDelete_L(LinkList &L, int i, ElemType &e)
{
p = L;
j = 0;
while (p->next && j < i - 1)
{
p = p->next;
++j;
}
if (!(p->next) || j > i - 1) return ERROR;
q = p->next; // 临时保存被删除结点的地址以备释放
p->next = q->next; // 改变删除结点前驱结点的指针域
e = q->data; // 保存删除结点的数据域
free(q); // 释放删除结点的空间
return OK;
}创建单链表
动态建立单链表 — 逆序输入 n 个元素的值,建立带表头结点的单链表
void CreateList_L(LinkList &L, int n)
{
L = (LinkList)malloc(sizeof(LNode));
L->next = NULL; // 先建立带头结点的单链表
for (i = n; i > 0; --i)
{
p = (LinkList)malloc(sizeof(LNode)); // 生成新结点
scanf(&p->data); // 输入元素值
p->next = L->next; // 插入到表头
L->next = p;
}
}特点:先建一个空表,从线性表的最后一个数据元素开始,逐个生成结点插入链表的链头,时间复杂度为 O (n)
合并操作(有序)
将两个有序链表合并成一个有序链表
// 函数功能:将两个有序单链表La和Lb合并为一个新的有序单链表Lc(假设原链表按data域升序排列)
// 参数:
// La:第一个有序单链表的头指针(引用传递,指向头结点)
// Lb:第二个有序单链表的头指针(引用传递,指向头结点)
// Lc:合并后新链表的头指针(引用传递,用于返回结果)
void MergeList_L(LinkList &La, LinkList &Lb, LinkList &Lc)
{
LinkList pa, pb; // 声明遍历指针(此处原代码省略,补充完整)
pa = La->next; // pa指向La的第一个数据节点(跳过头结点,准备遍历La)
pb = Lb->next; // pb指向Lb的第一个数据节点(跳过头结点,准备遍历Lb)
Lc = pc = La; // 新链表Lc复用La的头结点作为自己的头结点,pc作为Lc的尾指针(用于拼接节点)
// 当两个链表都有未遍历的节点时,循环比较并合并
while (pa && pb) {
// 比较当前pa和pb指向节点的data值,选择较小的节点接入Lc
if (pa->data <= pb->data) {
pc->next = pa; // 将pa指向的节点接到Lc的末尾
pc = pa; // 尾指针pc移动到新的末尾(即pa当前节点)
pa = pa->next; // pa移动到La的下一个节点,继续遍历
} else {
pc->next = pb; // 将pb指向的节点接到Lc的末尾
pc = pb; // 尾指针pc移动到新的末尾(即pb当前节点)
pb = pb->next; // pb移动到Lb的下一个节点,继续遍历
}
}
// 当其中一个链表遍历完毕后,将另一个链表的剩余节点直接接到Lc末尾
// (如果pa非空则接pa的剩余部分,否则接pb的剩余部分)
pc->next = pa ? pa : pb;
free(Lb); // 释放Lb的头结点(因为Lb的所有数据节点已合并到Lc,原头结点无用)
}时间复杂度:O (Length (La)+Length (Lb))
回顾C知识点:
->相当于“通过指针访问成员的运算符”,如果pc是结构体或类对象本身,可以用Pc.value访问,但如果是指向其的指针则需要用Pc ->value的方式访问其中的值,等价于(*pc).data
La是指向头结点的指针,La->next是从头结点结构体中获取next变量,其值为第一个数据节点的地址
空间:顺序表需另开辟空间,而链表不需要另开辟空间,只是将原链表重新排列。
单循环链表(circular linked list)
表中最后一个结点的指针指向头结点,使链表构成环状(强调“单”是因为只有一个指针域)
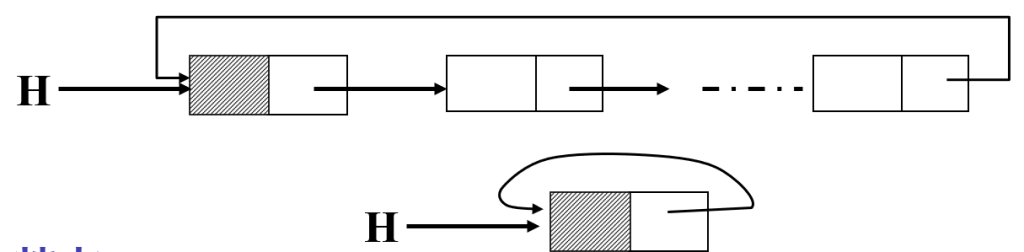
特点
- 从表中任一结点出发均可找到表中其他结点,提高查找效率
- 操作与单链表基本一致,循环条件不同
- 单链表:
p或p->next == NULL - 循环链表:
p或p->next == H
- 单链表:
- 带头结点的单循环链表为空的条件H->next = H
- 带头结点的单链表为空的条件是H->next==NULL
- 不带头结点的单链表 H==NULL
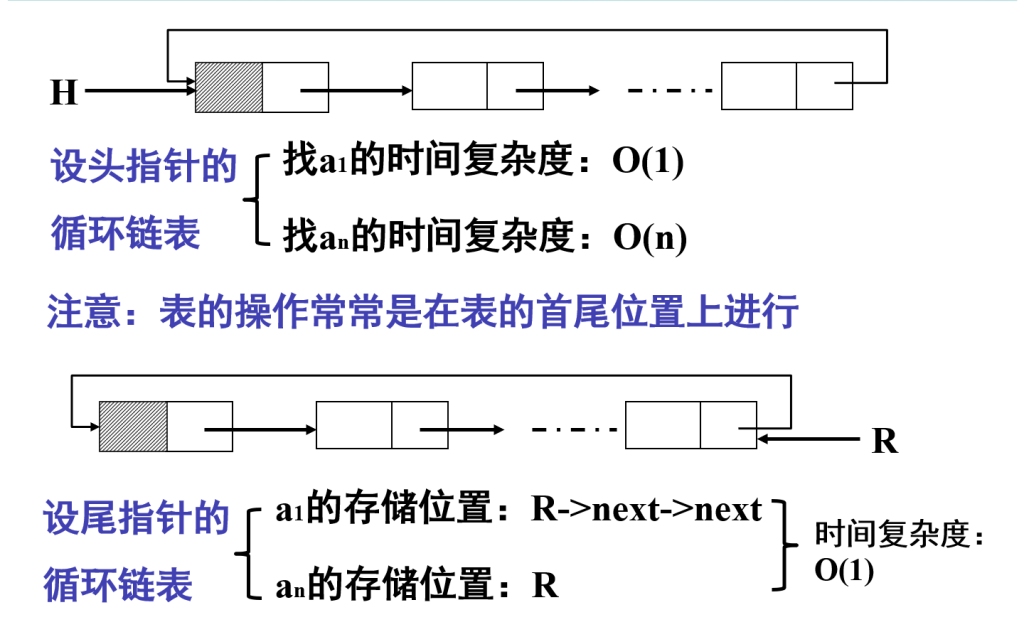
循环链表的操作(如插入、删除)常发生在首尾位置
设尾指针的循环链表,
能让 “访问首尾元素” 的操作都达到 O(1) 的时间复杂度,比设头指针的循环链表更高效(设头指针找尾元素需 O (n))
但是删除首元素为O(1),删除尾元素仍为O(n),因为需要删除/插入和访问/修改不同,删除需要找到前驱节点的next指针,修改其指向,也就是要找到倒数第二个节点需要从头节点一直遍历下去(现在只有尾节点和头节点是快速访问的)
合并操作 O(1)
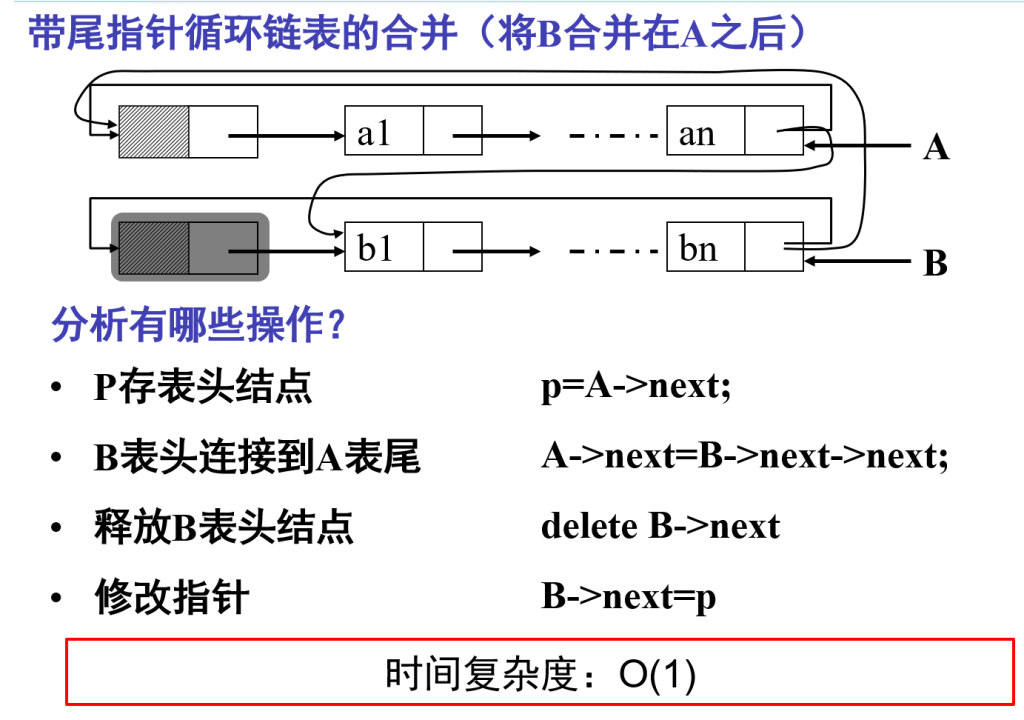
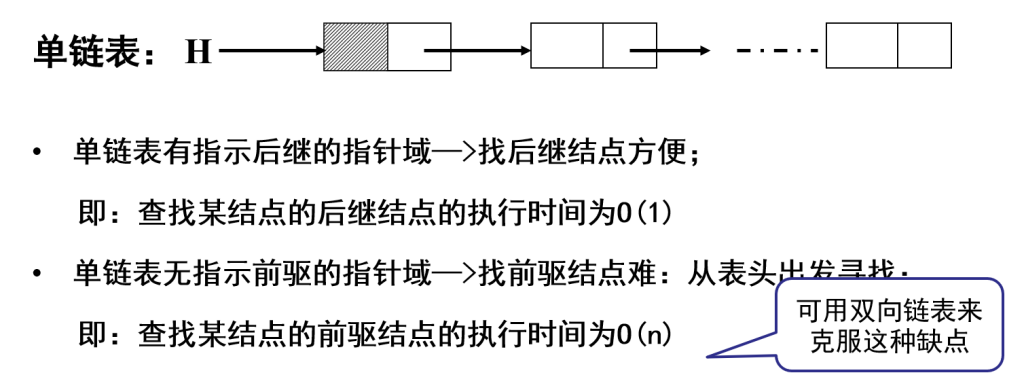
双向链表(double linked list)
每个结点增加一个指向其直接前驱的指针域prior,链表中形成了有两个方向不同的链
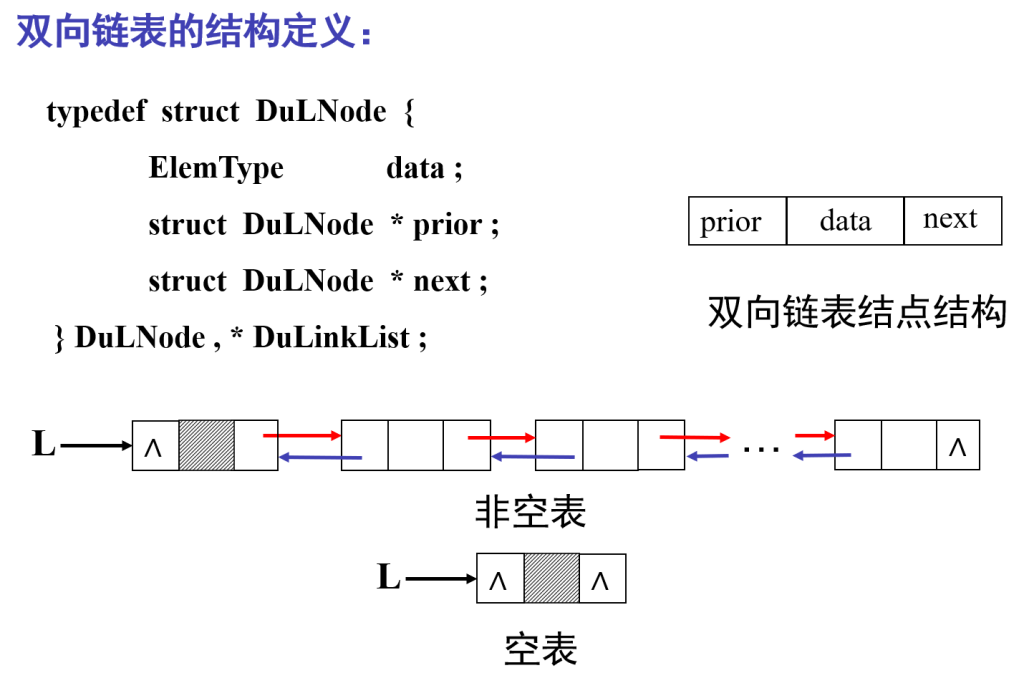
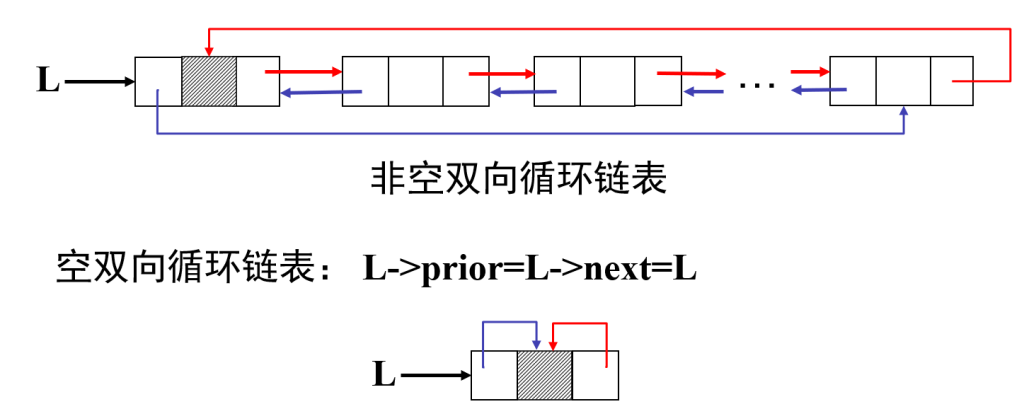
双向循环链表:
头结点的前驱指针指向链表的最后一个结点,最后一个结点的后继指针指向头结点
删除操作
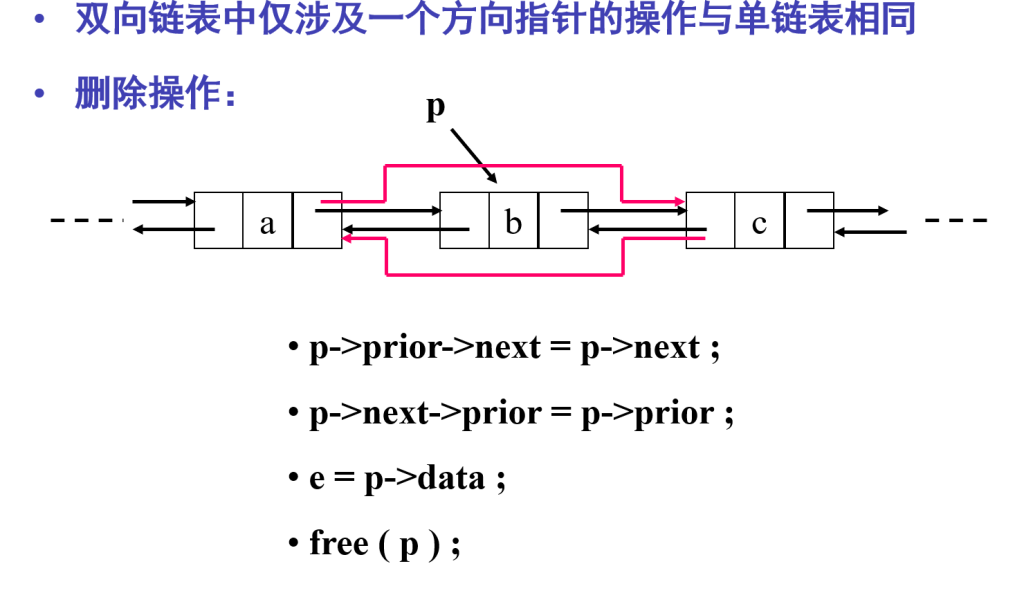
把结点 p 的数据域 data 的值赋给变量 e,就可以在结点被释放后,仍然能访问到该数据
使用 malloc 等函数动态分配的内存,在不再使用时需要手动释放,否则会造成内存泄漏
删除带头结点的双向循环链表 L 的第 i 个元素
Status Listdelete_DuL(DuLinkList &L, int i, ElemType &e)
{
if (!(p = GetElemP_DuL(L, i))) return ERROR;
e = p->data;
p->prior->next = p->next;
p->next->prior = p->prior;
free(p);
return OK;
}
- A(无头单循环链表)、C(带头单循环链表):单循环链表中,
p的前驱结点需要从p开始遍历链表直到找到next指向p的结点,时间复杂度为 O (n),不满足要求。 - B(双循环链表):双循环链表的每个结点包含
前驱指针(prior)和后继指针(next),可以直接通过p->prior获取前驱结点,修改指针的操作仅需常数时间,时间复杂度为 O (1),符合要求。
插入操作
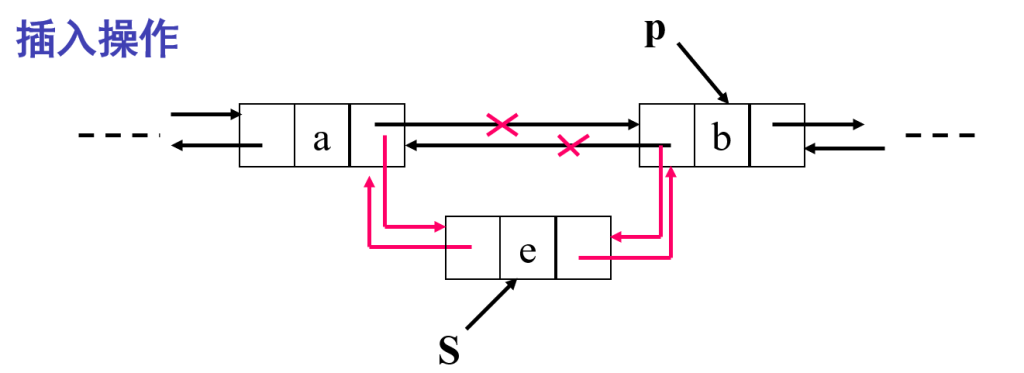
插入操作的完整步骤:
S = (DuLinkList)malloc(sizeof(DuLNode));→ 为新结点S分配内存。S->data = e;→ 给新结点S存数据e。S->prior = p->prior;→ 让S的前驱指向p的前驱(即a)。p->prior->next = S;→ 让a的后继指向S(这一步就是你问的核心)。S->next = p;→ 让S的后继指向p。p->prior = S;→ 让p的前驱指向S。
在双向循环链表 L 中的第 i 个元素之前插入元素 e
Status ListInsert_DuL(DuLinkList &L, int i, ElemType e)
{
if (!(p = GetElemP_DuL(L, i))) return ERROR;
if (!(s = (DuLinkList)malloc(sizeof(DuLNode))))
return ERROR;
s->data = e;
s->prior = p->prior;
p->prior->next = s;
s->next = p;
p->prior = s;
retrun OK;
}
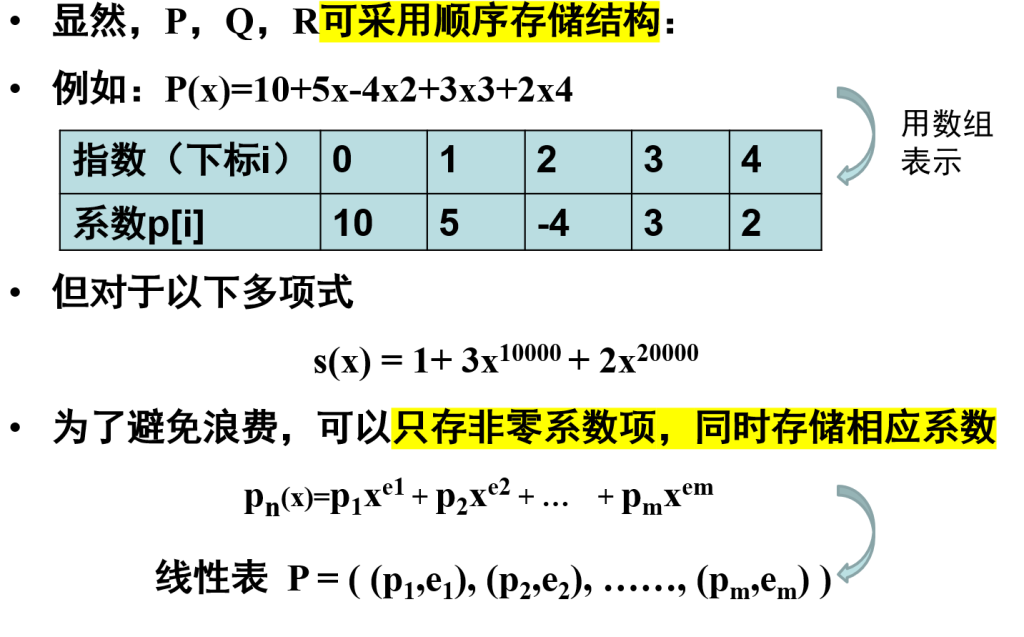
静态链表
为什么有下标但不能随机访问
因为顺序存储 + 下标才可以随机访问,头节点的内存地址 + 下标 ✖️每个节点分配的内存空间就能立刻找到,但是静态链表并不是顺序存储,存储位置是分散的,只是现在用下标替换了指针
这种结构具有链式存储的主要优点:插入删除时不需移动元素,
但需预先分配一个较大的空间,查找时仍不能像顺序表随机访问,而是要顺序走过每个节点
用数组下标代替指针,构造“可控、可预分配、无需动态内存”的链式存储结构
#define MAXSIZE 1000
typedef struct {
ElemType data ;
int cur ;
} component , SLinkList [ MAXSIZE ] ;一元多项式的表示及相加

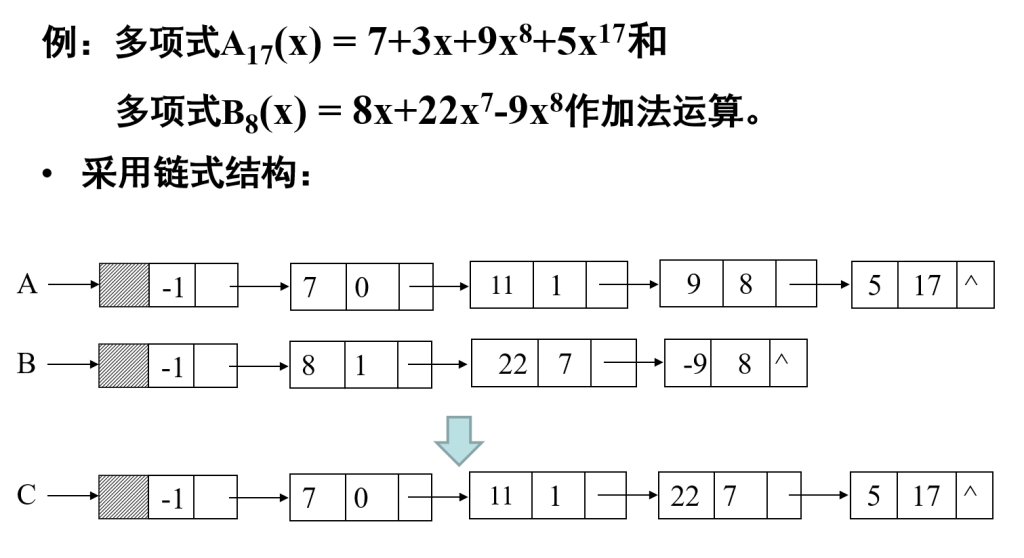
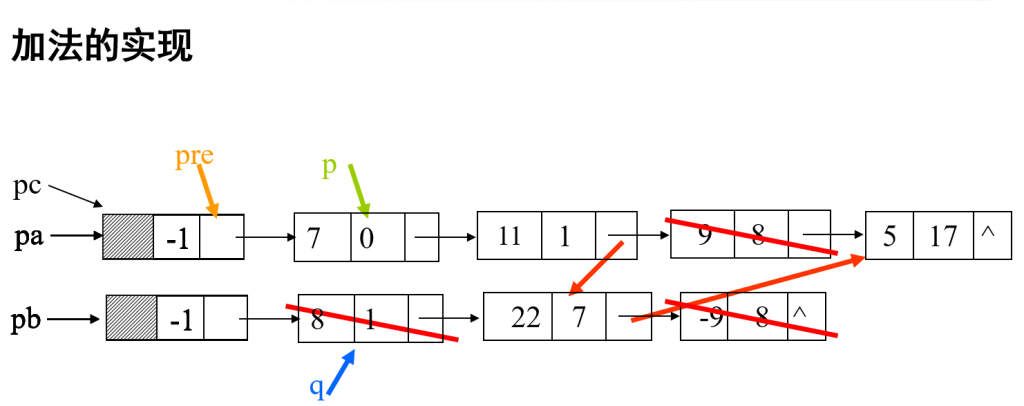
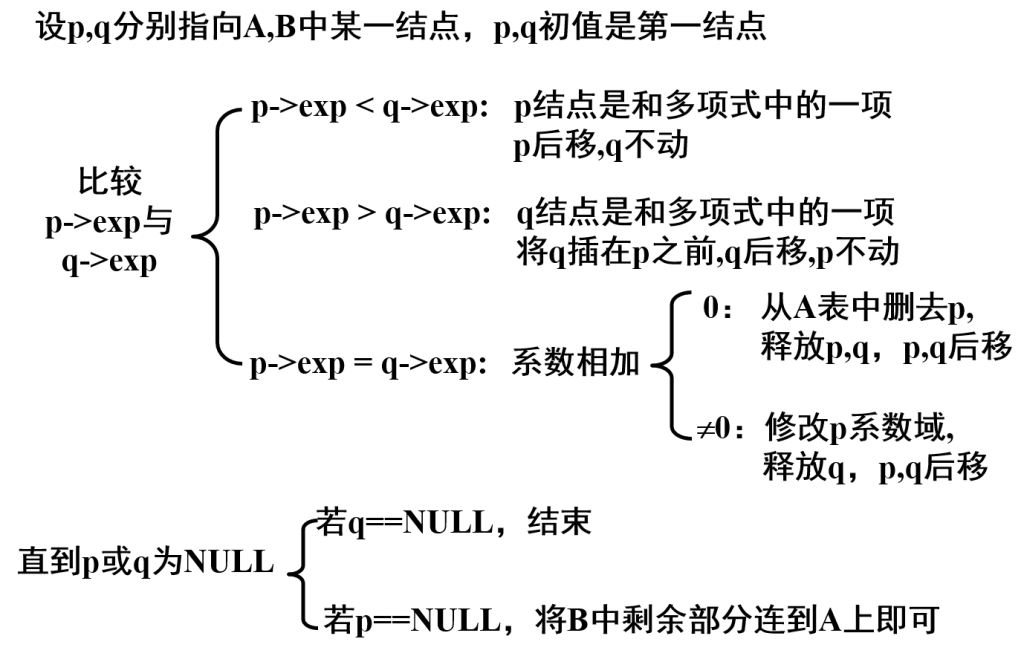
习题
单链表的遍历
已知非空带头单链表 L,其数据域类型为整数类型。编一算法,求表中所有数据域值大于给定值 Value 的结点个数,并返回。设链表的结点结构为:
typedef struct LNode {
int data;
struct LNode *next;
} LNode, *LinkList;
LinkList L;解:
int CountGreater(LinkList L, int Value)
{
int cnt = 0;
LNode *p = L->next; // 首元结点
while (p != NULL) {
if (p->data > Value) cnt++;
p = p->next;
}
return cnt;
}2.10

采用多次单元素删除的方式(外层循环 k 次,每次删除 1 个元素)。每次删除 1 个元素时,都要将后续元素逐个向前移动(内层循环 for(j=a.length; j>=i+1; j--) a.elem[j - i] = a.elem[j];)。
例如:删除 k 个元素需要移动 k 次,每次移动 \(O(n)\) 个元素,总时间复杂度为 \(O(kn)\),效率极低。
正确算法采用一次性批量删除的方式,核心是通过一次元素移动,覆盖要删除的 k 个元素,时间复杂度优化为 \(O(n)\)(仅需移动一次后续元素)。
Status DeleteK(SqList &a, int i, int k)
{
// 从顺序表 a 中删除第 i 个元素开始的 k 个元素(i 从 0 开始编号)
int j;
// 参数合法性检查:i 越界、k 为负、要删除的元素超过表长,都不合法
if (i < 0 || i > a.length - 1 || k < 0 || k > a.length - i)
return INFEASIBLE;
// 批量移动元素:将第 i+k 个元素及之后的元素,整体向前移动 k 位
// 覆盖掉第 i 到 i+k-1 这 k 个要删除的元素
for (j = 0; j <= k; j++)
a.elem[j + i] = a.elem[j + i + k];
// 表长减少 k(因为删除了 k 个元素)
a.length = a.length - k;
return OK;
}2.11
设顺序表 va 中的数据元素递增有序。试写一算法,将 x 插入到顺序表的适当位置上,以保持该表的有序性
Status InsertOrderList(SqList &va, ElemType x)
{
// 在非递减的顺序表 va 中插入元素 x 并使其仍成为顺序表的算法
int i;
// 检查顺序表是否已满,若已满则无法插入,返回OVERFLOW
if(va.length==va.listsize)return(OVERFLOW);
// 从顺序表的最后一个元素开始向前遍历
// 找到第一个不小于x的元素位置,同时将大于x的元素依次后移
for(i=va.length; i>0 && x<va.elem[i-1]; i--)
va.elem[i]=va.elem[i-1];
// 将x插入到找到的位置
va.elem[i]=x;
// 顺序表长度加1
va.length++;
// 返回插入成功的状态OK
return OK;
}2.15
已知指针 ha 和 hb 分别指向两个单链表的头结点,并且已知两个链表的长度分别为 m 和 n。试写一算法将这两个链表连接在一起,假设指针 hc 指向连接后的链表的头结点,并要求算法以尽可能短的时间完成连接运算。请分析你的算法的时间复杂度。
注意ha和hb不是头指针,只是遍历指针。
大致思路是比一比谁更长,以长的为基础,把短的 “粘” 在长的尾巴上。
// 函数功能:将两个单链表连接在一起,hc指向连接后的链表头结点
void MergeList_L(LinkList &ha, LinkList &hb, LinkList &hc)
{
// 定义两个指针pa、pb(没想到要定义两个指针),分别用于遍历两个链表
LinkList pa, pb;
// pa指向链表ha的头结点
pa = ha;
// pb指向链表hb的头结点
pb = hb;
// 同时遍历两个链表,直到其中一个链表的当前节点的下一个节点为空
while (pa->next && pb->next)
{
pa = pa->next;
pb = pb->next;
}
// 如果链表ha先遍历到尾节点(即pa->next为空)
if (!pa->next)
{
// 连接后的链表头结点指向hb的头结点
hc = hb;
// 遍历到链表hb的尾节点
while (pb->next)
pb = pb->next;
// 将链表ha的第一个数据节点(ha->next)连接到链表hb的尾节点后
pb->next = ha->next;
}
// 如果链表hb先遍历到尾节点(即pb->next为空)
else
{
// 连接后的链表头结点指向ha的头结点
hc = ha;
// 遍历到链表ha的尾节点
while (pa->next)
pa = pa->next;
// 将链表hb的第一个数据节点(hb->next)连接到链表ha的尾节点后
pa->next = hb->next;
}
}2.19 已知线性表中的元素以值递增有序排列,并以单链表作存储结构。试写一高效的算法,删除表中所有值大于 mink 且小于 maxk 的元素(若表中存在这样的元素),同时释放被删结点空间,并分析你的算法的时间复杂度(注意,mink 和 maxk 是给定的两个参变量,它们的值可以和表中的元素相同,也可以不同)。
我的错误想法:
pc = hc - next
while(pc){
if(pc->value >=mink)hc->next = pc
if(pc->value <=maxk)pc ->next = null
pc = pc->next
// 函数功能:删除单链表L中所有值大于mink且小于maxk的元素,并释放被删节点空间
// 参数:
// L:待操作的单链表(引用传递,头指针)
// mink:下限值
// maxk:上限值
// 返回值:操作成功返回OK,若mink > maxk返回ERROR
Status ListDelete_L(LinkList &L, ElemType mink, ElemType maxk)
{
// 定义指针,p用于遍历当前节点,q用于暂存待删除节点,prev用于指向当前节点的前驱节点
LinkList p, q, prev = NULL;
// 若下限大于上限,操作无意义,返回错误
if (mink > maxk) return ERROR;
// p初始化为链表头指针
p = L;
// prev初始化为头指针(指向头结点)
prev = p;
// p移动到第一个数据节点
p = p->next;
// 遍历链表,直到p为空或p所指节点值不小于maxk
while (p && p->data < maxk) {
// 若当前节点值小于等于mink,无需删除,更新前驱和当前节点,继续往后遍历
if (p->data <= mink) {
prev = p;
p = p->next;
}
// 若当前节点值大于mink且小于maxk,需要删除
else {
// 前驱节点的next指向当前节点的下一个节点,断开当前节点
prev->next = p->next;
// q暂存当前要删除的节点
q = p;
// p移动到下一个节点,准备继续遍历
p = p->next;
// 释放被删除节点的空间
free(q);
}
}
// 操作成功,返回OK
return OK;
}2.21 试写一算法,实现顺序表的就地逆置,即利用原表的存储空间将线性表 \((a_1, \dots, a_n)\) 逆置为 \((a_n, \dots, a_1)\)
我的想法,首先这是顺序表,没有指针一说,用索引
n一定要用,后面的结点的next指向前面一个节点,同时最后一个结点作为头结点的指向对象
p = hc ->next
hc-> next = lc[n-1]
while(p){
// 函数功能:实现顺序表的就地逆置,利用原存储空间将顺序表元素反转
// 参数:
// L:待逆置的顺序表(引用传递,以便修改原表)
// 返回值:操作成功返回OK
Status ListOppose_Sq(SqList &L)
{
int i; // 用于循环的索引变量
ElemType x; // 临时变量,用于交换元素时暂存值
// 循环执行到顺序表长度的一半即可,因为每次交换两个对称位置的元素
for(i = 0; i < L.length / 2; i++) {
x = L.elem[i]; // 暂存顺序表中第i个位置的元素
// 将第i个位置的元素替换为其对称位置(倒数第i+1个位置)的元素
L.elem[i] = L.elem[L.length - 1 - i];
// 将对称位置的元素替换为之前暂存的第i个位置的元素,完成交换
L.elem[L.length - 1 - i] = x;
}
return OK; // 返回操作成功的标识
}2.25 假设以两个元素依值递增有序排列的线性表 A 和 B 分别表示两个集合(即同一表中的元素值各不相同),现要求另辟空间构成一个线性表 C,其元素为 A 和 B 中元素的交集,且表 C 中的元素有依值递增有序排列。试对顺序表编写求 C 的算法。
// 函数功能:求两个递增有序顺序表A和B的交集,结果存入顺序表C(C需预先分配好空间或能动态扩展)
// 参数:
// A:第一个递增有序顺序表(引用传递,方便遍历)
// B:第二个递增有序顺序表(引用传递,方便遍历)
// C:用于存储交集结果的顺序表(引用传递,将结果存入其中)
// 返回值:操作成功返回OK
Status ListCross_Sq(SqList &A, SqList &B, SqList &C)
{
int i = 0, j = 0, k = 0; // i用于遍历A,j用于遍历B,k用于记录C中元素的位置
// 当A和B都未遍历完时,循环比较元素
while (i < A.length && j < B.length) {
// 若A当前元素小于B当前元素,A指针后移,找更大的元素
if (A.elem[i] < B.elem[j]) i++;
else {
// 若A当前元素大于B当前元素,B指针后移,找更大的元素
if (A.elem[i] > B.elem[j]) j++;
// 若A和B当前元素相等,说明是交集中的元素
else {
// 将该共同元素插入到C中第k个位置
ListInsert_Sq(C, k, A.elem[i]);
// A指针后移,继续遍历A
i++;
// C的元素位置后移,准备插入下一个元素
k++;
}
}
}
// 操作成功,返回OK
return OK;
}循环A,如果A(B)当前元素比B大,则比较下一个B(A)元素,当遇到相等的元素则将其添加到C中
2.33 已知由一个线性链表表示的线性表中含有三类字符的数据元素(如:字母字符、数字字符和其他字符),试编写算法将该线性表分割为三个循环链表,其中每个循环链表表示的线性表中均只含一类字符。
// 函数功能:将单链表L按字符类型(数字、字母、其他)分割为3个单循环链表s1、s2、s3
// 参数:
// L:待分割的原单链表(引用传递,处理后原链表头结点会被释放)
// s1:存储数字字符的单循环链表(引用传递,需预先创建头结点)
// s2:存储字母字符的单循环链表(引用传递,需预先创建头结点)
// s3:存储其他字符的单循环链表(引用传递,需预先创建头结点)
// 返回值:操作成功返回OK
Status ListDivideInto3CL(LinkList &L, LinkList &s1, LinkList &s2, LinkList &s3)
{
LinkList p, q, pt1, pt2, pt3;
// p指向原链表L的第一个数据节点,准备遍历原链表
p = L->next;
// pt1、pt2、pt3分别指向三个目标循环链表的头结点,用于后续拼接节点
pt1 = s1;
pt2 = s2;
pt3 = s3;
// 遍历原链表,直到所有节点处理完毕(p为NULL)
while (p) {
// 判断当前节点p的数据是否为数字字符('0' - '9')
if (p->data >= '0' && p->data <= '9') {
q = p; // q暂存当前要处理的节点
p = p->next; // p移动到原链表的下一个节点,继续遍历
// 将q节点插入到s1循环链表中(采用头插法,q的next指向原s1的第一个节点,再让s1头结点的next指向q)
q->next = pt1->next;
pt1->next = q;
pt1 = pt1->next; // pt1移动到新的末尾节点(即刚插入的q节点)
}
// 判断当前节点p的数据是否为字母字符(大写'A'-'Z' 或 小写'a'-'z')
else if ((p->data >= 'A' && p->data <= 'Z') ||
(p->data >= 'a' && p->data <= 'z')) {
q = p; // q暂存当前要处理的节点
p = p->next; // p移动到原链表的下一个节点,继续遍历
// 将q节点插入到s2循环链表中(头插法)
q->next = pt2->next;
pt2->next = q;
pt2 = pt2->next; // pt2移动到新的末尾节点
}
// 既不是数字也不是字母,判定为其他字符
else {
q = p; // q暂存当前要处理的节点
p = p->next; // p移动到原链表的下一个节点,继续遍历
// 将q节点插入到s3循环链表中(头插法)
q->next = pt3->next;
pt3->next = q;
pt3 = pt3->next; // pt3移动到新的末尾节点
}
}
q = L; // q暂存原链表的头结点
free(q); // 释放原链表的头结点(原链表数据节点已全部分割,头结点无用)
return OK; // 返回操作成功标识
}2.38 设有一个双向循环链表,每个结点中除有 pre、data 和 next 三个域外,还增设了一个访问频度域 freq。在链表被起用之前,频度域 freq 的值均初始化为零,而每当对链表进行一次 Locate (L, x) 的操作后,被访问的结点(即元素值等于 x 的结点)中的频度域 freq 的值便增 1,同时调整链表中结点之间的次序,使其按访问频度非递增的次序顺序排列,以便始终保持被频繁访问的结点总是靠近表头结点。试编写符合上述要求的 Locate 操作的算法。
指针循环访问,如果某个结点的值等于x,则将结点的frequency++,之后重新排序,不清楚怎么排序
// 函数功能:在双向循环链表中查找值为 e 的节点,找到后更新其频度域 freq,并按 freq 非递增调整节点位置
// 参数:
// L:双向循环链表的头节点(引用传递,方便修改链表结构)
// e:要查找的元素值
// 返回值:找到的节点指针,未找到返回 NULL
DuLinkList ListLocate_Dul(DuLinkList &L, ElemType e)
{
DuLinkList p, q; // 定义指针 p 用于遍历查找,q 用于辅助插入位置的查找
p = L->next; // p 指向链表的第一个数据节点,开始遍历
// 遍历链表,直到找到值为 e 的节点或回到头节点(遍历完一圈未找到)
while (p != L && p->data != e) p = p->next;
if (p == L) return NULL; // 若 p 回到头节点,说明未找到,返回 NULL
else {
p->freq++; // 找到目标节点,频度域 freq 加 1
// 步骤一:从原链表中删除该节点
p->pre->next = p->next; // 该节点前驱的 next 指向该节点的后继
p->next->pre = p->pre; // 该节点后继的 pre 指向该节点的前驱,完成删除
// 步骤二:查找合适的插入位置(按 freq 非递增)
q = L->next; // q 指向链表的第一个数据节点,开始查找插入位置
// 遍历链表,找到第一个 freq 小于等于当前节点 freq 的节点 q
while (q != L && q->freq > p->freq) q = q->next;
// 情况一:q 为头节点(说明当前节点 freq 最大,应插入到表头)
if (q == L) {
p->next = q->next; // 当前节点的 next 指向原头节点的 next(即第一个数据节点)
q->next = p; // 头节点的 next 指向当前节点
p->pre = q->pre; // 当前节点的 pre 指向头节点的 pre(即尾节点)
q->pre = p; // 头节点的 pre 指向当前节点,完成循环链表的连接
}
// 情况二:q 不是头节点(在 q 之前插入当前节点)
else {
p->next = q->pre->next; // 当前节点的 next 指向 q 前驱的 next(即 q)
q->pre->next = p; // q 前驱的 next 指向当前节点
p->pre = q->pre; // 当前节点的 pre 指向 q 的前驱
q->pre = p; // q 的 pre 指向当前节点,完成插入
}
return p; // 返回找到的节点指针
}
}