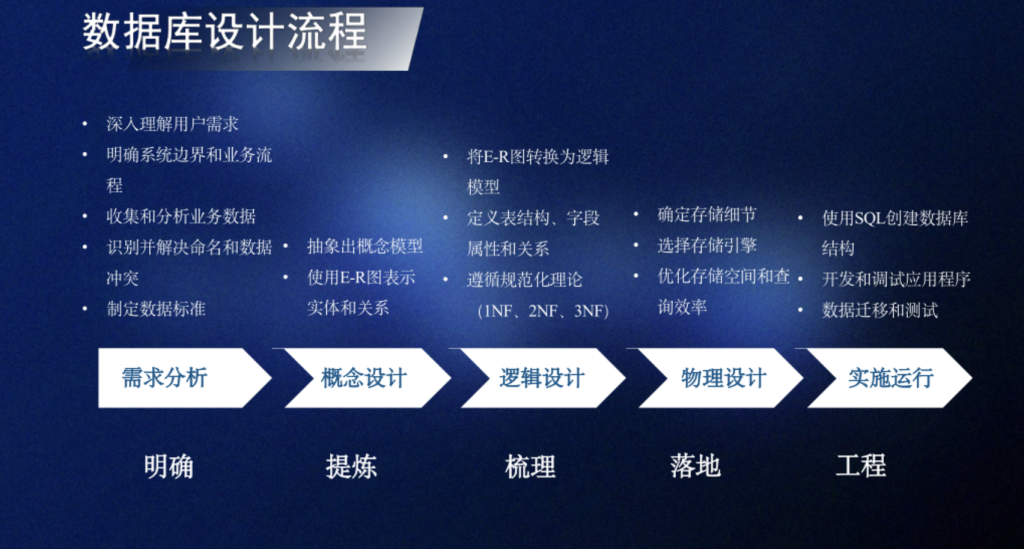
KNN概述
k 近邻法(k-nearest neighbor,k-NN)是最简单的分类与回归方法,是一种常用的监督学习方法
其工作机制为:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本构成训练数据集,然后基于这k个“邻居”的标签来进行预测。
kNN是懒惰学习(lazy learning)的典型代表,缺乏显性的模型表达式。不过,K -近邻法具有记忆性 (Memory-based),懒惰学习技术在训练阶段仅仅将样本保存起来,训练开销为0,等收到测试样本时再进行处理,相应的,那些在训练阶段就对样本进行学习处理的方法,称为“急切学习(eager learning)”
K近邻法基本流程
- 收集数据:可以采用任意方法获取所需数据。
- 准备数据:整理为适合进行距离计算的结构化数据格式。
- 分析数据:可运用各种分析方法对数据进行处理。
- 训练算法:注:此步骤不适用于k-近邻算法(因其为惰性学习算法,无显式训练过程)。
- 测试算法:通过计算分类错误率来评估算法性能。
- 使用算法:输入样本数据及结构化输出结果,运行k-近邻算法进行分类判定
K近邻模型三要素
- 距离度量
- K-值的选择
- 分类决策规则
距离度量
kNN中使用的距离度量可以是欧式距离、曼哈顿距离、切比雪夫距离或者一般的闵可夫斯基距离。具体定义可参见这里
k值选择
K值较小(如K=1)
模型偏差小:
仅依赖最近的少数邻居,能捕捉数据的局部细节和复杂模式,预测结果更接近真实值,偏差较低。
模型方差大:
对噪声和异常点敏感,微小的数据波动会导致分类结果显著变化,模型稳定性差,方差较高。
敏感性高:
分类结果易受最近邻的个别点影响,边界决策不规则(如锯齿状)
复杂度高:若k值与训练集样本数相同,会导致最终模型的结果都是指向训练集中类别数最多的那一类,忽略了数据当中其它的重要信息,模型会过于简单
拟合程度:
模型过度关注局部特征,可能学习到噪声,导致过拟合(在训练集表现好,测试集差)
| 特点 | K值较小 | K值较大 |
| 模型偏差 | 小 | 大 |
| 模型方差 | 大 | 小 |
| 对待分类实例的敏感性 | 强 | 弱 |
| 模型复杂度 | 复杂 | 简单 |
| 模型拟合程度 | 过拟合 | 欠拟合 |
- 当k = 1时,k近邻算法就是最近邻算法
- 实际工作中经常使用交叉验证的方式去选取最优的k值,将数据集分成若干份(如5份或10份),轮流用其中一份作为验证集,其余作为训练集,多次训练和验证,最终取平均结果评估模型性能。而且一般情况下,k值都是比较小的数值
分类决策规则
对于分类问题,决策规则常采用多数投票的方式(众数思想):
(还可基于距离远近进行加权平均或加权投票)
输入:训练数据集 \( D = \{(\mathbf{x}_i, y_i)\}_{i=1}^m \),其中:特征向量 \( \mathbf{x}_i \in \mathcal{X} \subseteq \mathbb{R}^n \)类别标签 \( y_i \in \mathcal{Y} = \{c_1, c_2, \dots, c_K\} \)
根据给定的距离度量,在训练集 \( D \) 中找出与 \( \mathbf{x} \) 最邻近的 \( k \) 个点,其邻域记为 \( N_k(\mathbf{x}) \)
在 \( N_k(\mathbf{x^*}) \) 中根据分类决策规则确定样本的类别 \( c^*\):
\[
c^* = \arg \max_{c_j} \sum_{x_i \in U_K(x^*)} I(y_i = c_j), \quad
\begin{cases}
i = 1, 2, \cdots, N \\
j = 1, 2, \cdots, M
\end{cases}
\]
I为指示函数,当样本 xi的标签 yi=cj时值为 1,否则为 0。求和:统计 k个邻居中属于类别 cj的数量。
选择使统计值最大的类别 cj作为预测结果\(c^*\),对新的实例,根据与之相邻的 k 个训练实例的类别,通过多数投票等方式进行预则
对于回归问题,决策规则常采用平均法则(均值思想):
\[
\hat{y}^* = \frac{1}{K} \sum_{x_i \in U_K(x^*)} y_i, \quad i = 1, 2, \cdots, N
\]
对新的实例,根据与之相邻的 k 个训练实例的标签,通过均值计算进行预则。

K近临分类例子:

KNN优缺点
优点:
- 结构简单;
- 无数据输入假定,准确度高,对异常点不敏感。
缺点:
- 计算复杂度高、空间复杂度高;
- 样本不平衡时,对稀有类别预测准确度低;
- 使用懒惰学习,预测速度慢。
KD树
KNN最简单的实现方法是线性扫描,这是一种暴力实现方法,然而当训练集很大时,搜索k个最近邻居的计算非常耗时。
在实现kNN时,主要考虑的问题就是如何对训练数据进行快速k近邻搜索。这样的方法有kd树和球树,本文只讨论kd树
构造KD树
kd树是一种对k维空间中的实例点进行存储,以便对其进行快速检索的二叉树结构。
构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间切分,构成一系列的k维超矩形区域,kd树的每个结点对应一个k维超矩形区域。
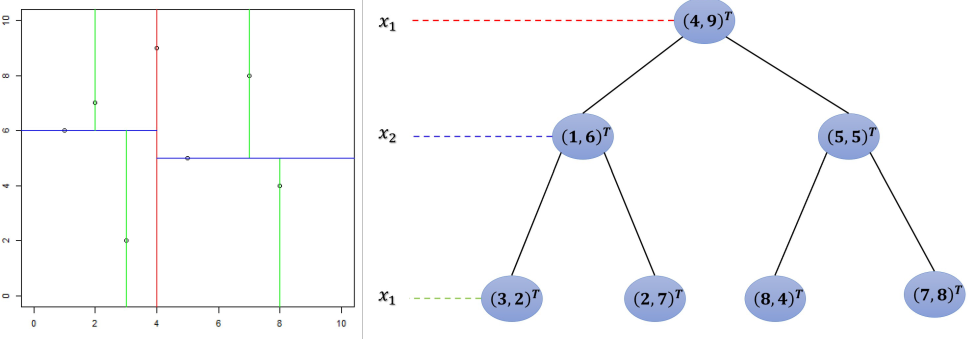
假设数据集(以二维数据集为例):T={(1,6),(2,7),(3,2),(4,9),(5,5),(7,8)(8,4)}目标:构建平衡KD树,支持高效查询。
1.选择分割轴:
计算每个特征的方差,选择方差最大的轴,或随便选一个轴。根据方差选出来的是第 l1 个特征 xl1x轴方差
2.选择分割点:
计算所有实例在属性特征 xl1 方向上的中位数,以该中位数对应的样本作为根结点,将超凭形区域切割为两个子区域。深度指所有结点的最大层次数,根结点处深度为 0,由根结点生成的 子结点深度为 1
3.递归构造子树
继续对深度为 j 的结点切割,根据求余公式 lj = (j + 1) mod p 得到特征xlj,选择 xlj 为当前最优特征,以该结点区域中所有实例在特征 xlj 上的中位数作为切割点,将区域切割为两个子区域.重复(1)(2),直到两个子区域没有实例存在时停止(这意味着最后所有训练实例都对应一个叶结点或内部结点),从而形成kd树的区域划分。

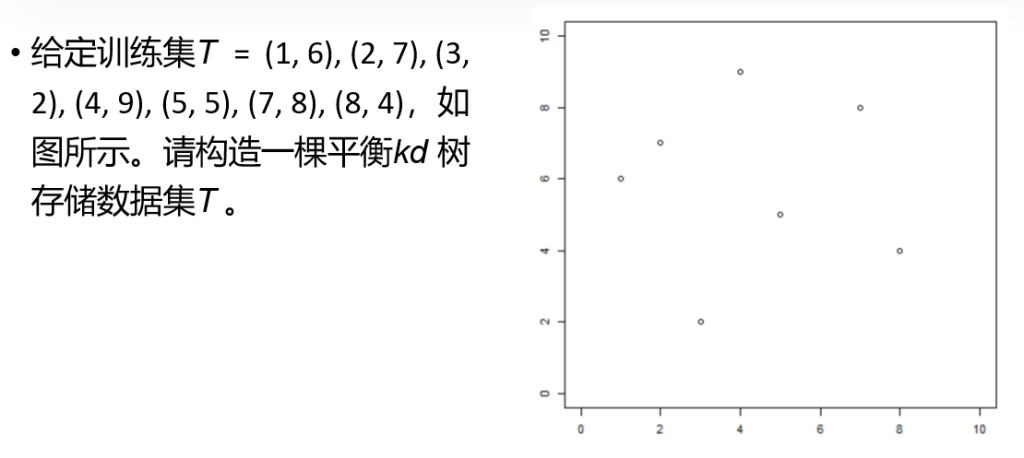
第 1 层分割(按 x 轴)
- 排序:按第 1 维(x 坐标)排序:(1,6), (2,7), (3,2), (4,9), (5,5), (7,8), (8,4)
- 选择中位数:第 4 个点 (4,9)作为根节点。
- 划分:
- 左子树:x < 4 → {(1,6),(2,7),(3,2)}
- 右子树:x > 4 → {(5,5),(7,8),(8,4)}
第 2 层分割(按 y 轴)
- 左子树 {(1,6),(2,7),(3,2)}:
- 按第 2 维(y 坐标)排序:(3,2), (1,6), (2,7)
- 中位数:(1,6)。
- 划分:
- 左子节点:y < 6 → (3,2)
- 右子节点:y > 6 → (2,7)
- 右子树 {(5,5),(7,8),(8,4)}:
- 按第 2 维排序:(8,4), (5,5), (7,8)
- 中位数:(5,5)。
- 划分:
- 左子节点:y < 5 → (8,4)
- 右子节点:y > 5 → (7,8)
第 3 层分割(按 x 轴)
- 所有子节点均为叶子节点,无需进一步分割。
验证平衡性
- 每个非叶子节点的左右子树深度差不超过 1(左子树深度=2,右子树深度=2),满足平衡条件。
搜索最近邻 – 体会KD树提升KNN效率
输入:已构造的kd树;目标点x;
过程:
- 在kd树中找到包含目标点x xx的叶结点:从根结点出发,递归地向下访问kd树,直到叶结点为止;
- 以此叶结点为“当前最近点”,把目标点与此叶结点的实例之间的距离记为“当前最近距离”;
- 递归地向上回退,对每个父结点:
(a)如果该父结点保存的实例点与目标点的距离比当前最近距离更近,则以该实例点为“当前最近点”,以该距离为“当前最近距离”;
(b)检查该父结点的另一子结点对应的区域是否与以目标点为球心、以“当前最近距离”为半径的超球体相交。如果相交,则递归地对该父结点的另一子结点进行最近邻搜索;如果不相交,则向上回退。
- 当回退到根结点时,搜索结束。最后的“当前最近点”就是x的最近邻点
例子:
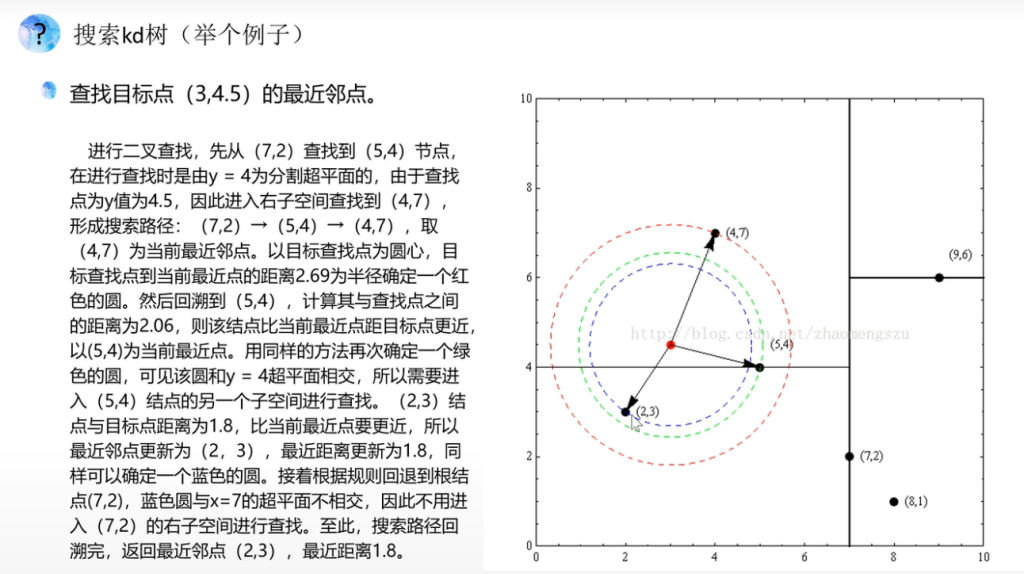
从这个过程我们应该明白构建KD树如何加快查找临近点的效率,显然我们并没有遍历所有的点去查找是否为最邻近点。近乎一半的点没有参与搜索最近邻的过程