之前根据概率/非概率,参数/非参数的维度划分模型,还可以根据模型处理的任务分为以下3类
- Regression回归模型:预测连续值,输出空间是无限的数字(监督学习)
- Classification分类模型:预测类别,输出是有限的类别标签(监督学习)
- 聚类模型:输出是无限的类别,与分类的区别是无需预定义类别,基于数据相似性分组(无监督学习)
回归分析的主要算法包括:
- 线性回归(Linear Regression)
- 逻辑回归(Logistic regressions)
- 多项式回归(Polynomial Regression)
- 逐步回归(Step Regression)
- 岭回归(Ridge Regression)
- 套索回归(Lasso Regression)
- 弹性网回归(ElasticNet)
“回归”的命名:人们在测量事物的时候因为客观条件所限,求得的都是测量值,而不是事物真实的值,为了能够得到真实值,无限次的进行测量,最后通过这些测量数据计算回归到真实值
线性与非线性
- 线性:两个变量之间的关系是一次函数关系的——图象是直线,叫做线性。注意:线性是指广义的线性,也就是数据与数据之间的关系。
- 非线性:两个变量之间的关系不是一次函数关系的——图象不是直线,叫做非线性
那到底什么时候可以使用线性回归呢?统计学家安斯库姆给出了四个数据集,被称为安斯库姆四重奏
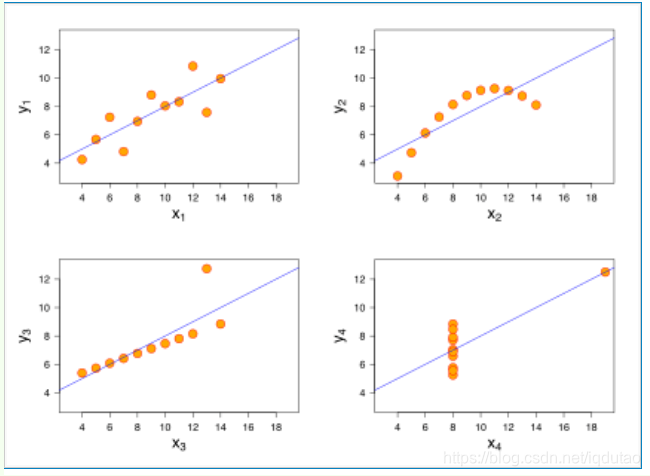
- 要预测的变量 y 与自变量
x的关系是线性的(图2 是一个非线性)。 - 各项误差服从正太分布,均值为0,与
x同方差(图4 误差不是正太分布)。 - 变量
x的分布要有变异性。 - 多元线性回归中不同特征之间应该相互独立,避免线性相关。
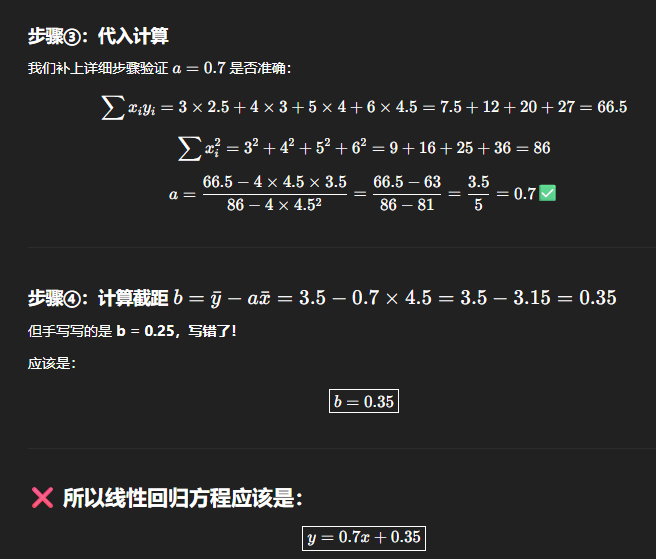
一元线性回归

通常将b合并到参数w中组成参数向量
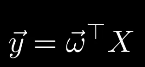
一元指只有一个输入变量X,如果需要基于不止一种变量做出预测即为多元
术语:
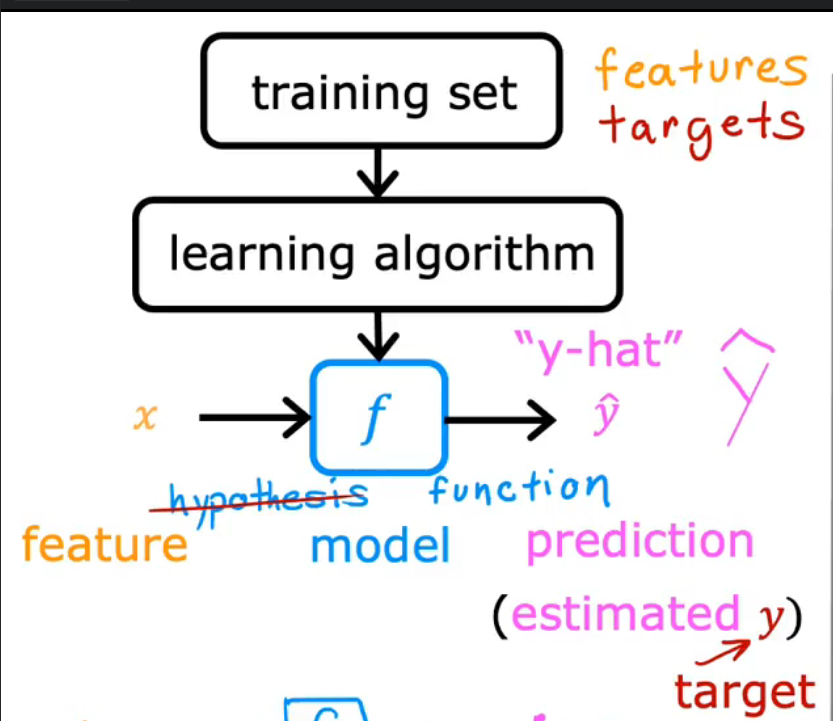
- X:Input Variable/feature/prediction 输入变量
- \(\hat{y}\) target Variable 输出变量,对真实输出的估计
- Y:output Variable 真实输出
- m:number of traning examples
- (x,y):single training example,一组观测数据
- \((x^{(i)}, y^{(i)}) = i^{\text{th}} \text{ training example}\) 第i组观测数据
- f:模型,在此处是一元线性回归模型
- \(f_{w,b}(x) = wx + b\),w,b称为parameter参数/coefficient系数/weight权重,是可以调整的变量以让模型的损失函数最小以提高模型的性能
- 符号 w∗ 和 b∗ 通常表示最优解(optimal solution), 这里指使目标函数最小的最优参数值
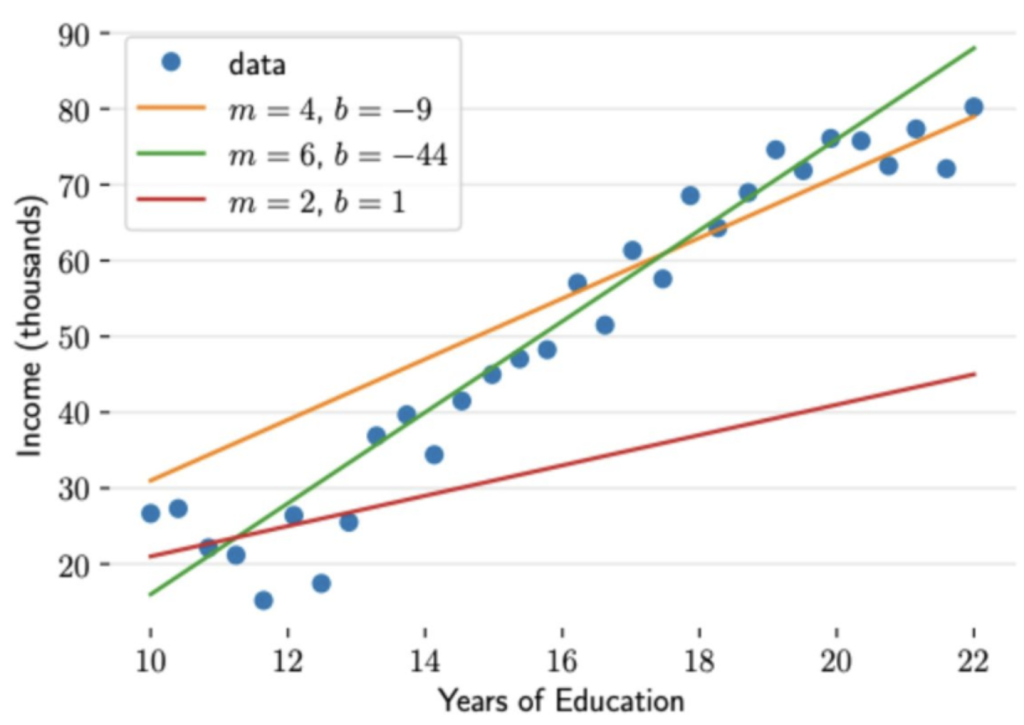
损失函数
上图给出了不同的参数,到底哪条直线是最佳的呢?如何衡量模型是否以最优的方式拟合数据呢?机器学习用损失函数(loss function)来衡量这个问题。损失函数又被称为代价函数(cost function),它计算了模型预测值 ŷ 和真实值 y 之间的差异程度

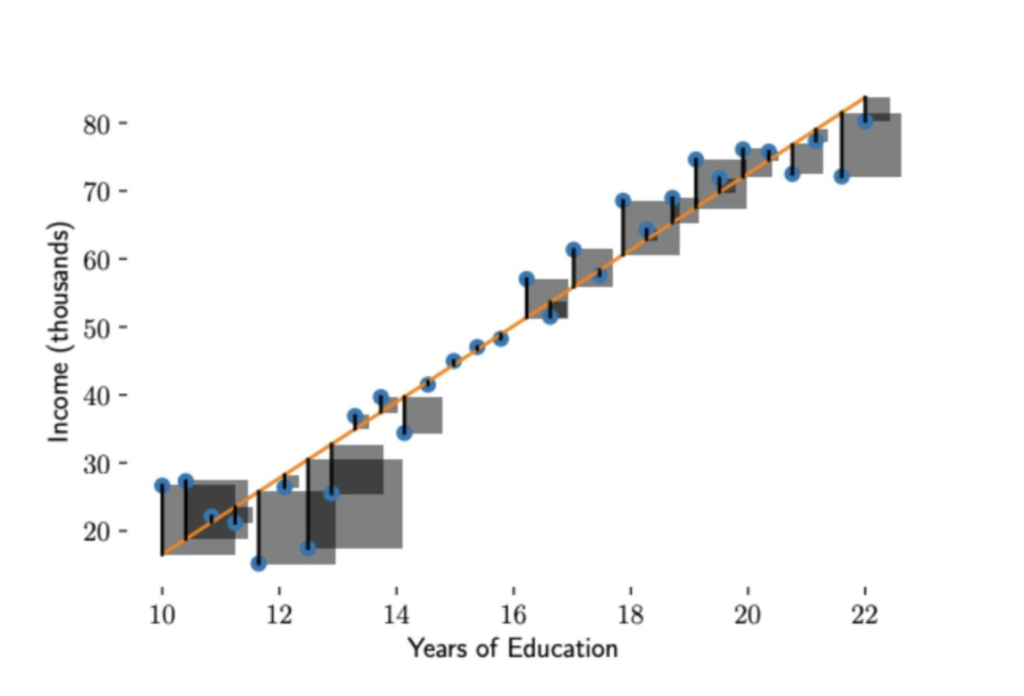
误差从图形上看是一条线段,平方后就形成了一个正方形,将正方形的面积求和再取平均,就是公式 3 的损失函数。所有的正方形的平均面积越小,损失越小
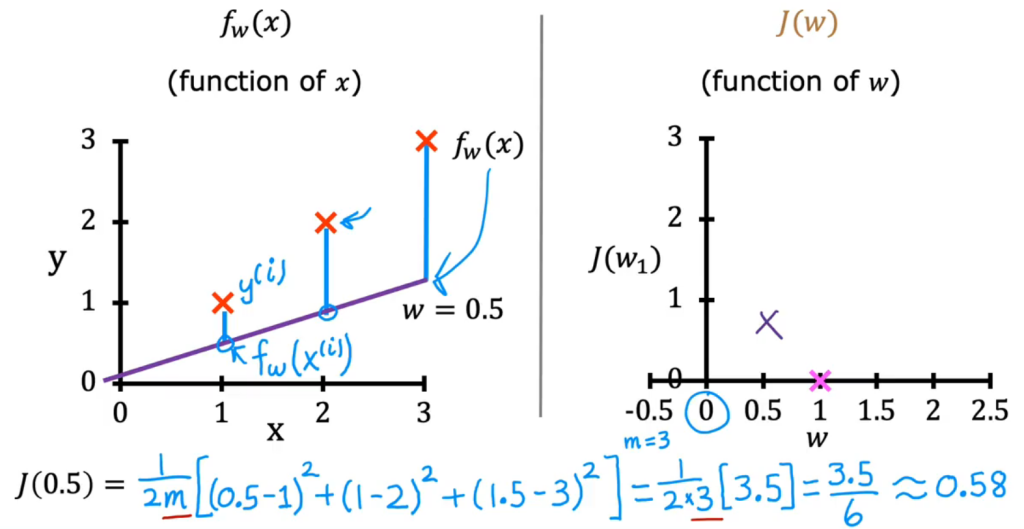
不同的参数w对应不同的模型函数fw(x)和一个成本j(w),当遍历所有的w就能得到完整的损失函数图像
其最小值所对应的w即我们应该选择作为模型的参数
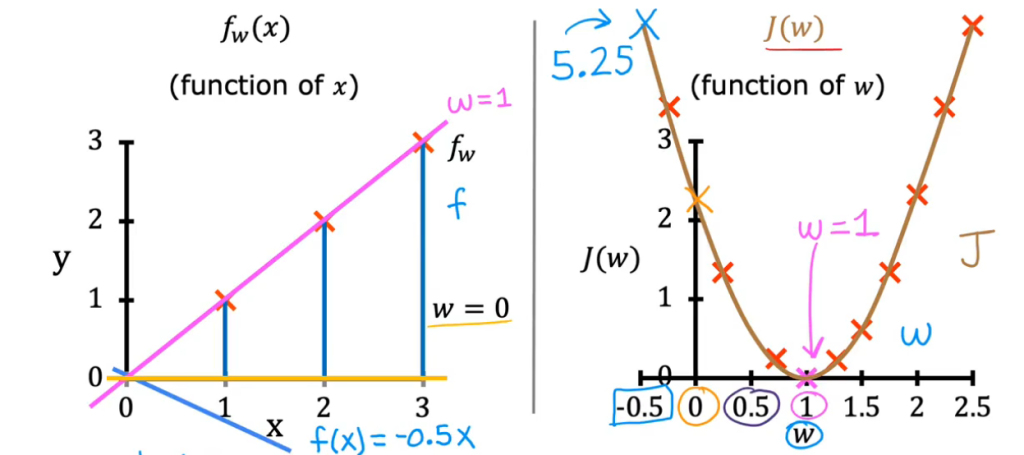
比如在该例中,w=1时J(w)的值最小,J是衡量平方误差大小的成本函数,从而选择w=1作为模拟函数的系数
采用平方损失函数来拟合函数的基本思想即是最小二乘法
最小二乘法
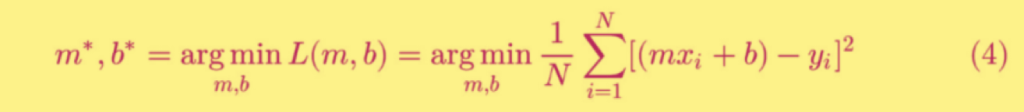
以上就是最小二乘法的数学表示,“二乘” 表示取平方,“最小” 表示损失函数最小。至此我们发现,有了损失函数,机器学习的过程被化解成对损失函数求最优解过程,即求一个最优化问题。
最小二乘法是用平方(或二次)损失函数来逼近目标函数的一种思想。线性回归只是最小二乘法的一个简单且常用的例子,因此介绍最小二乘法时通常会以线性回归为例。
为什么要平方?
- 把正负误差都变成正数(否则可能抵消)
- 放大大误差的影响,惩罚偏离大的点
那为什么只能用取平方,不能用别的办法,比如取绝对值呢?
- 数学上可导,便于求极值(比如梯度下降),而绝对值函数则不具有这个属性
几何意义:向量空间中的投影:将数据点看作高维空间中的向量,最小二乘法其实是把实际观测值(真实数据点)投影到模型预测值(由参数张成的子空间)上。投影后的点与真实点之间的“最短距离”对应的就是误差最小的情况
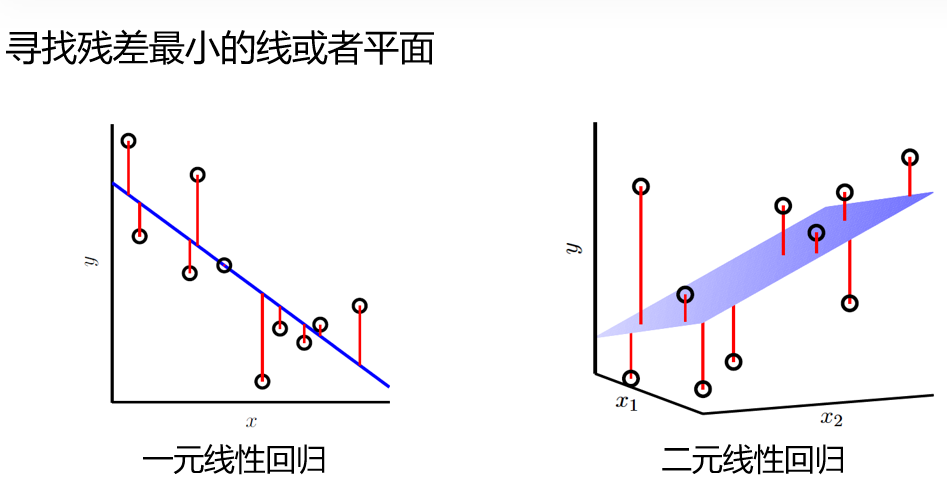
参数求解:


多元线性回归 Mutiple linear regression
现在我们把 x 扩展为多元的情况,即多种因素共同影响变量 y。现实问题也往往是这种情况,比如,要预测房价,需要考虑包括是否学区、房间数量、周边是否繁华、交通方便性等。共有 D 种维度的影响因素,机器学习领域将这 D 种影响因素称为特征(feature)。每个样本有一个需要预测的 y 和一组 D 维向量 X。原来的参数 m 变成了 D 维的向量 w。这样,某个 y_i 可以表示成
$$ y_i = b + \sum_{d=1}^D w_d x_{i,d} \quad\quad b = w_{D+1} \tag{12} $$ $$ y_i = \sum_{d=1}^{D+1} w_d x_{i,d} \tag{13} $$
为了表示起来更方便,也使算法更高效的运行,独立出来的偏置项可以使用下面的方法归纳到向量 w 中:使用 \(b = w_{D+1}\) 来表示参数中的 \(b\),将 \(b\) 添加到特征向量的最后一位,将D维特征扩展成D+1维,也就是在每个 x 最后添加一个值为1的项,这样就可以由公式12得到公式13。 \[ \mathbf{w} = \begin{bmatrix} w_1 \\ w_2 \\ \vdots \\ w_D \\ w_{D+1} \end{bmatrix} \quad \mathbf{X} = \begin{bmatrix} x_1 \\ x_2 \\ \vdots \\ x_N \end{bmatrix} = \begin{pmatrix} x_{1,1} & x_{1,2} & \dots & x_{1,D} & 1 \\ x_{2,1} & x_{2,2} & \dots & x_{2,D} & 1 \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ x_{N,1} & x_{N,2} & \dots & x_{N,D} & 1 \end{pmatrix} \quad \mathbf{y} = \begin{bmatrix} y_1 \\ y_2 \\ \vdots \\ y_N \end{bmatrix} \tag{14} \] 各个向量形状如公式14所示。其中,向量 w 表示模型中各个特征的权重;矩阵 X 的每一行是一条样本,每条样本中有D+1个特征值,分别为该样本在不同维度上的取值; 可以用内积的形式来表示求和项:\(\sum_{d=1}^{D+1} w_d x_{i,d} = \mathbf{w}^\top \mathbf{x}_i\)。N条样本组成的数据可以表示为: \(\mathbf{y} = \mathbf{X}\mathbf{w}\) \[ y_i = \sum_{d=1}^{D+1} w_d x_{i,d} = \mathbf{w}^\top \mathbf{x}_i \Rightarrow \mathbf{y} = \mathbf{X}\mathbf{w} \tag{15} \]
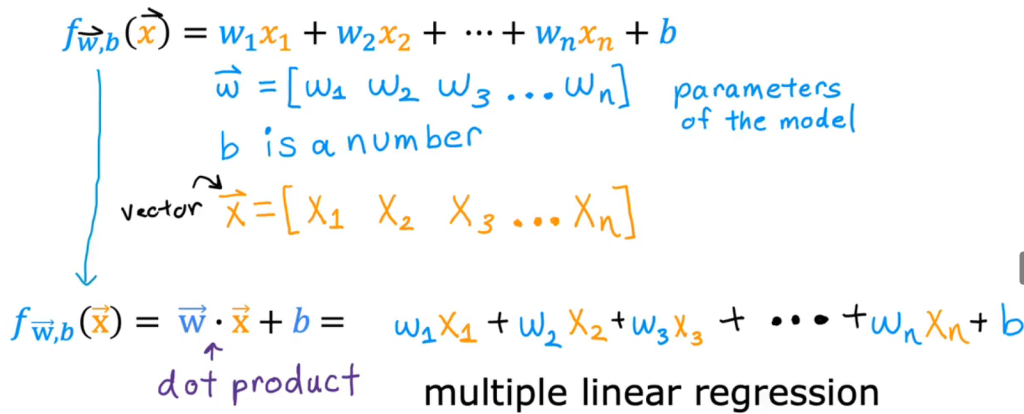
比一元线性回归更为复杂的是,多元线性回归组成的不是直线,是一个多维空间中的超平面,数据点散落在超平面的两侧
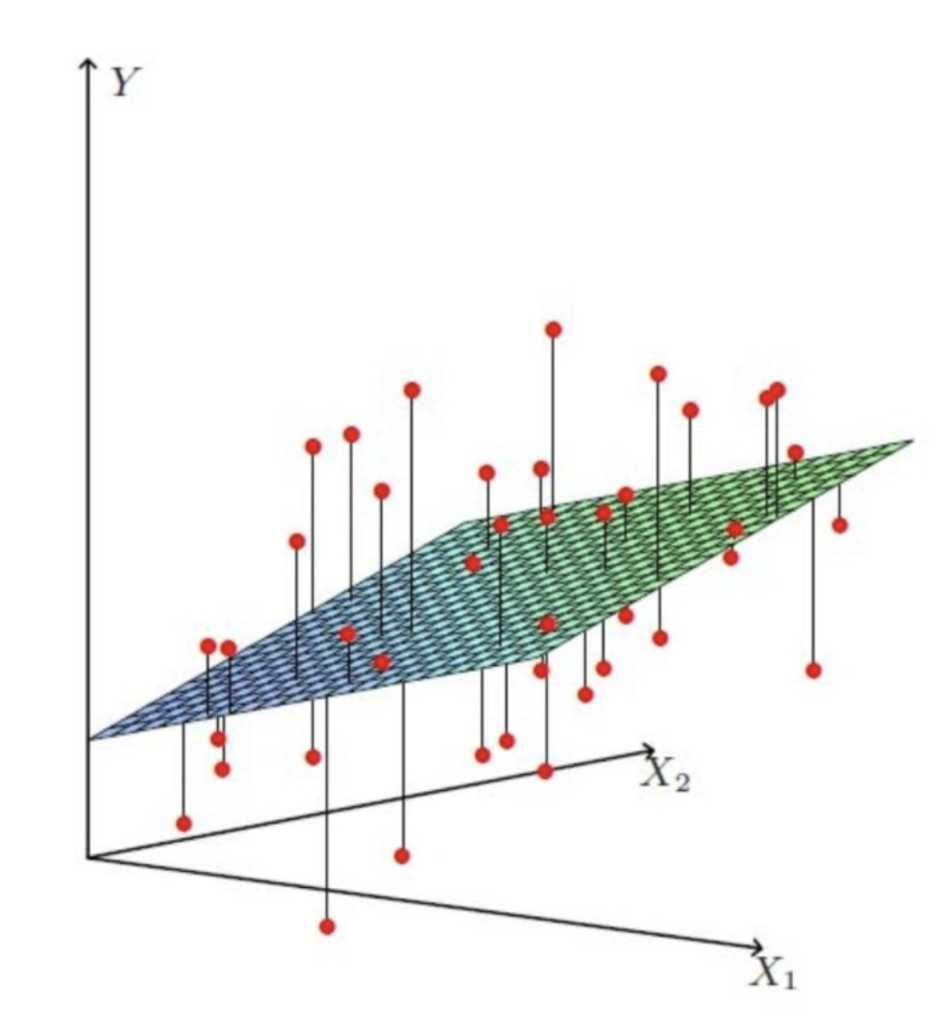
$$ L(w) = (\mathbf{Xw} – \mathbf{y})^\top (\mathbf{Xw} – \mathbf{y}) = \|\mathbf{Xw} – \mathbf{y}\|_2^2 \tag{16} $$
多元线性回归的损失函数仍然使用“预测值-真实值”的平方来计算,公式16为整个模型损失函数的向量表示。这里出现了一个竖线组成的部分,它被称作L2范数的平方。范数通常针对向量,也是一个机器学习领域经常用到的数学符号,公式17展示了一个向量 x的L2范数的平方以及其导数。 $$ \|\mathbf{x}\|_2^2 = \left(\left(\sum_{i=1}^N x_i^2\right)^{1/2}\right)^2 \quad\quad \nabla\|\mathbf{x}\|_2^2 = 2\mathbf{x} \tag{17} $$ $$ \frac{\partial}{\partial \mathbf{w}} L(\mathbf{w}) = 2\mathbf{X}^\top (\mathbf{Xw} – \mathbf{y}) = 0 \tag{18} $$ 对公式16中的向量w求导,得到公式18。 — $$ \mathbf{X}^\top \mathbf{Xw} = \mathbf{X}^\top \mathbf{y} \Rightarrow (\mathbf{X}^\top \mathbf{X})^{-1} \mathbf{X}^\top \mathbf{Xw} = (\mathbf{X}^\top \mathbf{X})^{-1} \mathbf{X}^\top \mathbf{y} \tag{19} $$ $$ \mathbf{w}^* = (\mathbf{X}^\top \mathbf{X})^{-1} \mathbf{X}^\top \mathbf{y} \tag{20} $$ 公式19组成向量 w的矩阵方程,根据线性代数的知识,最优解其实是在解这个矩阵方程,英文中称这个公式为 Normal Equation。这些最优解组成了一个最优超平面
求偏导求极值和梯度下降求极值
公式20中矩阵求逆的计算量比较大,复杂度在$O(n^3)$级别。当特征维度达到百万级以上或样本数量极大时,计算时间非常长,单台计算机内存甚至存储不下这些参数,求解矩阵方程的办法就不现实了,必须使用梯度下降法。梯度下降法以一定的精度逼近最优解,求解速度在数据量大时非常有优势,但不一定能得到绝对的最优解
Gradient Decent 梯度下降算法
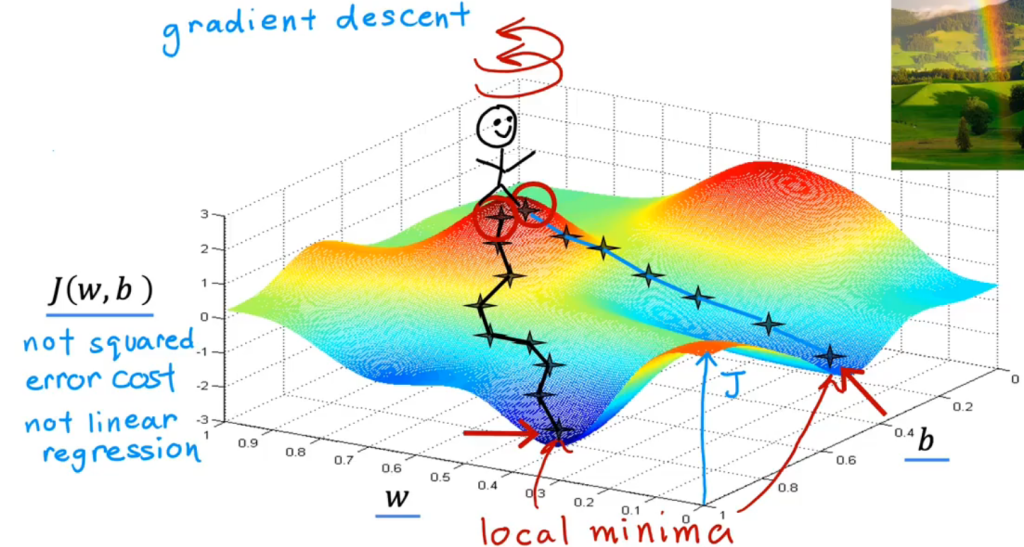
每次向变化率最高的方向走一步,直到走到最低点即各个方向都会导致值增加,从而找到局部最小值点。
梯度算法的重要性质:不同的初始值,会导致不同的局部最小值结果

Learning rate 学习率\alpha:控制向下坡走的步大小 0<\alpha≤1
Derivative 导数:控制方向
- =在数学中有时意为判断左右是否相等,有时为赋值的含义,而前者在编程中明确表示为==
- 两者的区别在于是否更新完全部参数再计算,差别不大,但是建议使用左边的方式
还是先从一元线性回归理解梯度算法的过程,从某个初始点不断向着最低点以学习率的倍数逼近
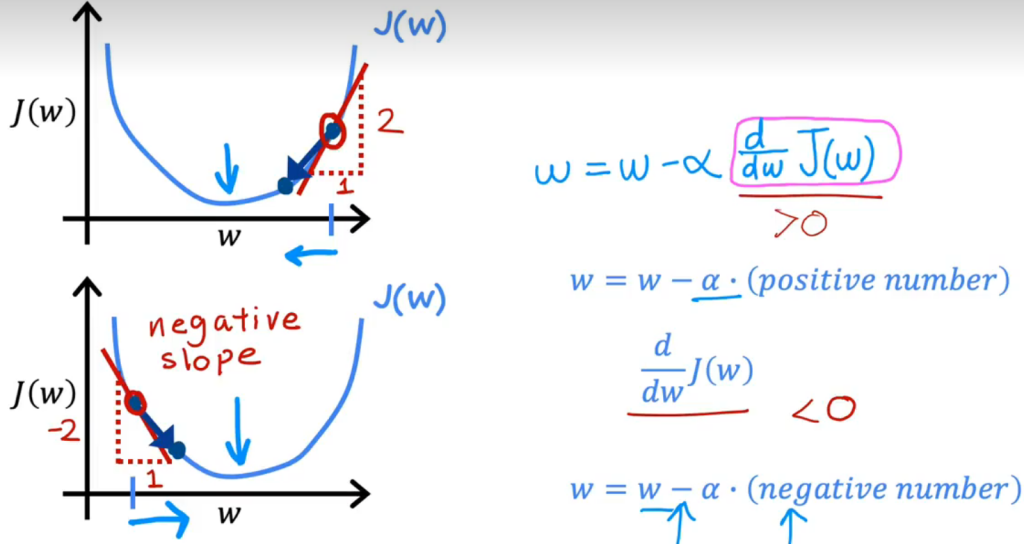
你可能会注意到如果学习率过大从而导致步长过大,但这不会引发函数发散即局部最小值位于某个步长的中间点,因为随着梯度下降的过程导数会不断变小
线性回归的梯度算法
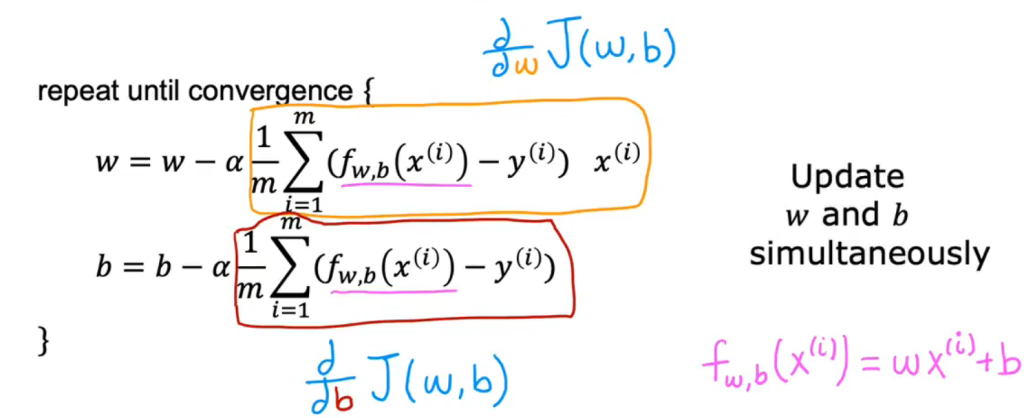
- f(x)是线性回归模型,其等于wx+b,黄框部分是成本函数关于w的导数,红框部分为成本函数关于b的导数。要同时更新w和b
- 成本函数前乘以1/2的原因:可以使其导数的形式变得更简洁
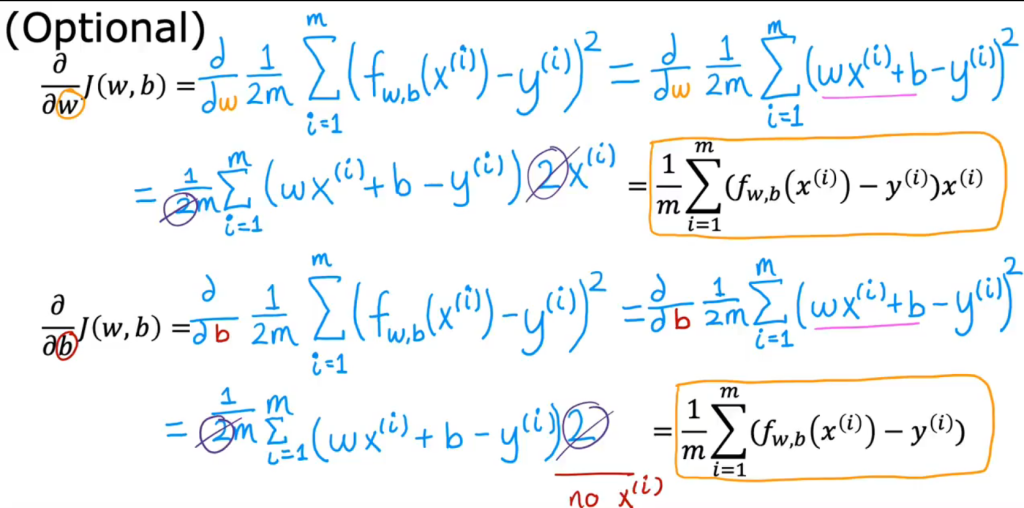
梯度算法的问题:通常对非凸函数(convex function)使用梯度算法寻找最佳w和b时,根据初始设置的w和b的不同会有多个局部最小值。然而线性回归的成本函数是凸函数,所以对其梯度下降算法并不会有这种问题,无论初始条件是什么都只会得到全局最小值
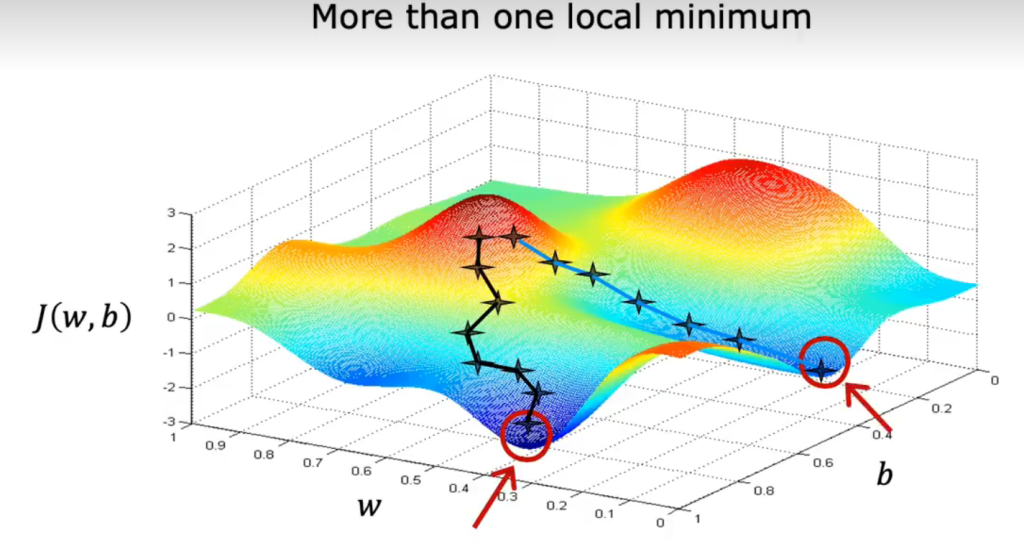
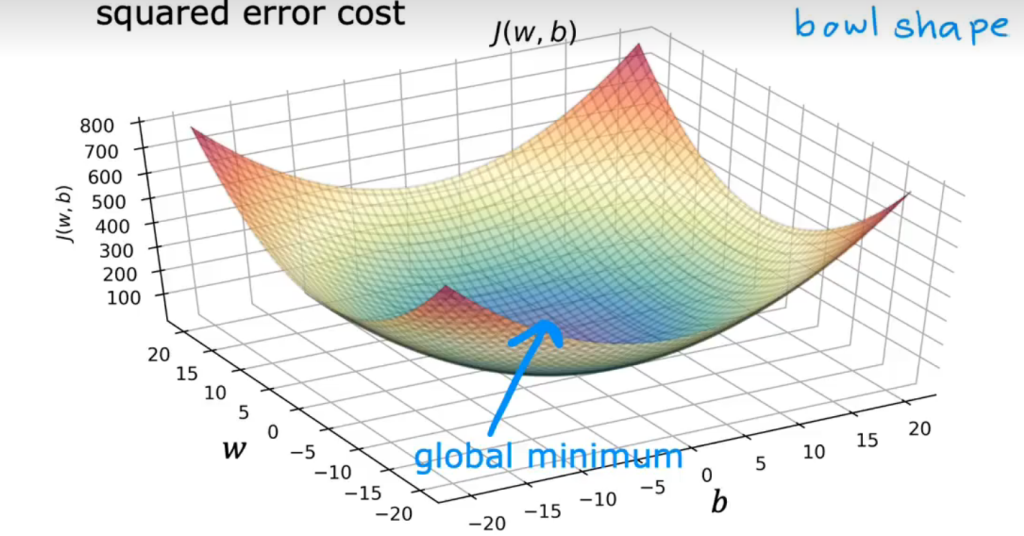
下面是对线性回归模型的成本函数应用梯度函数,将w设为-0.1,b设为900的过程
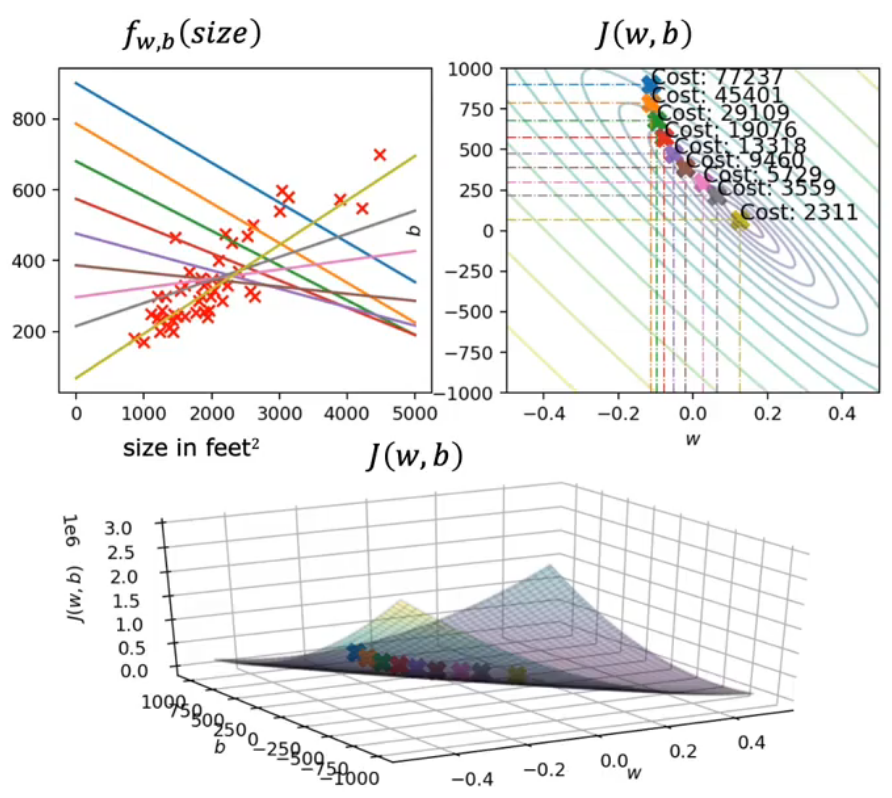
- Batch gradient desent 梯度下降算法指在下降的每一步中查看所有的数据集而不是训练数据的子集

线性回归的正则化
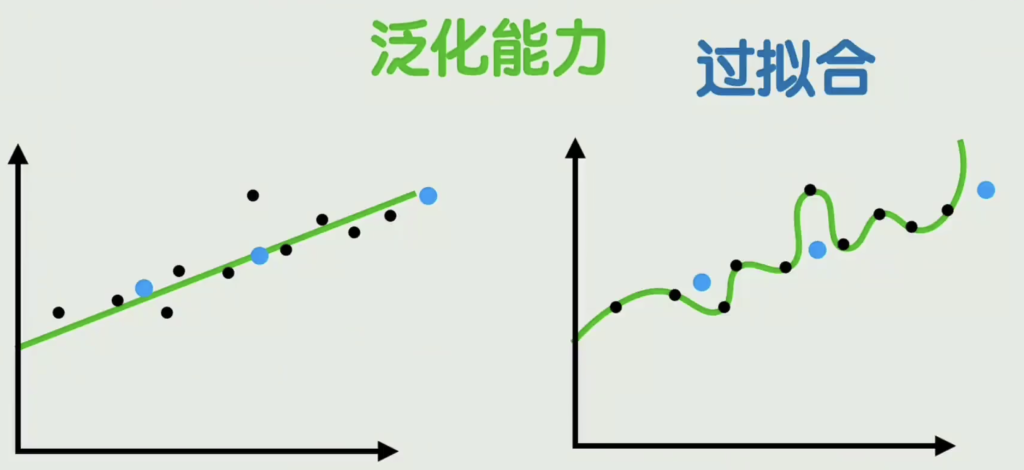
过拟合:在训练数据上表现的很完美,但在没见过数据上拟合的很糟糕的现象
泛化能力:在没见过的数据上的表现能力,叫泛化能力
训练数据可能是很简单的规律,但模型太复杂了,将噪声和随机波动也学会了,有两种解决方法:
- 第一种方法从数据入手:增加训练数据的量

但也可以通过修改原有数据来增加数据,可以对数据进行些微的扰动创建新的数据,这就叫做数据增强,这样不仅仅能很简单的创建新的训练数据,也能让模型不因输入的些微变化而产生较大波动,这就是增强了模型的鲁棒性robustness
第二种方法,从训练过程入手阻止过拟合发生,正则化
- 提前终止训练过程
- Dropout 丢弃
- 正则化:向损失函数中添加权重惩罚项,抑制参数野蛮增长的方法
- 训练是不断让损失函数变小的方向训练的, 那我们可以在损失函数中加入参数本身的值,这样参数在往大调整时,损失函数并不会减少的很多,甚至新的损失函数有可能是更大的,那么参数变大的趋势就被抑制住了
- 参数太多,即多元一般才需要正则化,因为不知道选择哪些参数,全选的话必然导致过拟合,所以可以全选,通过正则化降低每项的系数,避免模拟函数过拟合
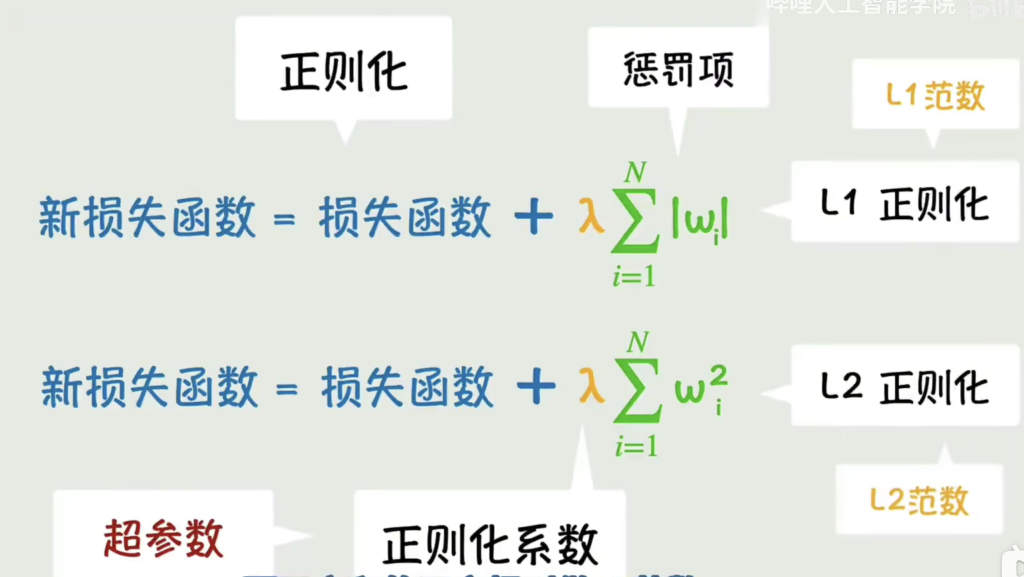
之前控制梯度下降的力度的权重系数叫学习率,正则化中控制惩罚力度的权重系数叫正则化系数,而这些控制参数的参数,叫做超参数
线性回归的正则化只惩罚所有特征的参数w,不惩罚常数项b。这会产生一个更拟合的曲线
如果\(\lambd\)权重很大代表分给正则化项更多的权重,则将会把各个参数惩罚为0,只剩下b常数项从而导致欠拟合。如果\(\lambd\)权重很小,则就会出现过拟合的问题。所以要选择一个合适的\(\lambd\)值

利⽤L2范数进⾏正则化不仅可以使模型选择较⼩的参数,同时也避免X^T X不可逆的问题
对数几率回归(对率回归)
线性回归模型帮助我们用最简单的线性方程实现了对数据的拟合,然而,这只能完成回归任务,无法完成分类任务,那么 logistics regression 就是在线性回归的基础上添砖加瓦,构建出了一种分类模型。虽然名称是“回归”,但实际却是一中分类学习方法
如果在线性模型 \( (z = w^T x + b) \) 的基础上做分类,比如二分类任务,即 \( y \in \{0,1\} \),直觉上我们会怎么做?最直观的,可以将线性模型的输出值再套上一个函数 \( y = g(z) \),最简单的就是“单位阶跃函数”(unit-step function),如下图中红色线段所示。 \[ y = \begin{cases} 0, & z < 0; \\ 0.5, & z = 0; \\ 1, & z > 0. \end{cases} \] 也就是说 \( z = w^T x + b \) 看作为一个分割线,大于 \( z \) 的判定为类别0,小于 \( z \) 的判定为类别1。 但是,这样的分段函数数学性质不太好,它既不连续也不可微。我们知道,通常在做优化任务时,目标函数最好是连续可微的。那么如何改进呢? 这里就用到了对数几率函数(形状如图中黑色曲线所示):
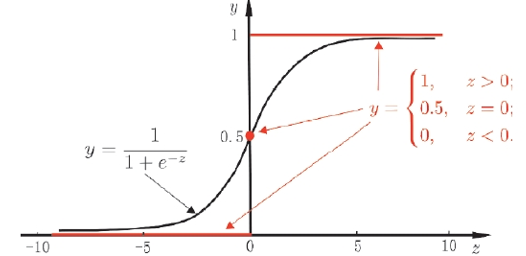
总的来说,模型的完全形式如下: \[ y = \frac{1}{1 + e^{-(w^T x + b)}} \]
\( w^T \) 的作用是让权重向量 \( \mathbf{w} \) 和输入特征向量 \( \mathbf{x} \) 能够正确计算内积(点积)
- y是最终的分类结果(0或1):例如,
y=1表示“恶性”,y=0表示“良性”。

- 直接对分类可能性进行建模,无需事先假设数据分类;
- 不是仅预测出“类别”,而是可得到近似概率预测;
- 对率函数是任意阶可导的凸函数,有很好的数学性质。
习题: