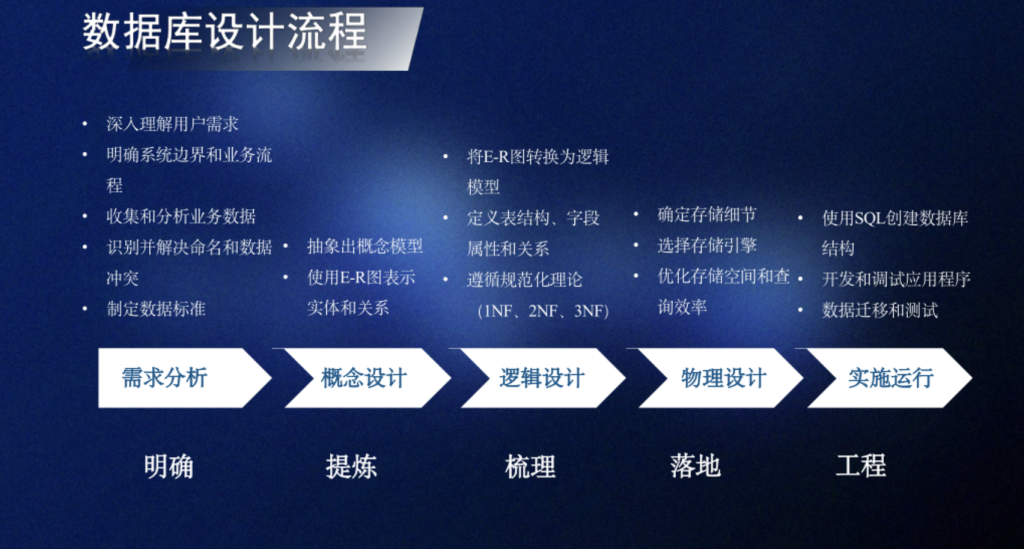
用 k-NN 算法给企鹅 “分类”:从数据清洗到模型落地的完整指南
一、数据集初探:认识企鹅数据
首先导入常用的库,然后查看 seaborn 库中可用的数据集。本实验将使用企鹅(penguins)数据集
# 导入所需库
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets, linear_model
import pandas as pd
import seaborn as sns
# 查看seaborn库中的数据集名称
sns.get_dataset_names()
输出
['anagrams', 'anscombe', 'attention', 'brain_networks', 'car_crashes', 'diamonds', 'dots', 'dowjones', 'exercise', 'flights', 'fmri', 'geyser', 'glue', 'iris', 'healthexp', 'mpg', 'penguins', 'planets', 'seaice', 'taxis', 'tips', 'titanic']接下来,我们加载企鹅数据集并查看其内容。将数据集加载到一个名为 dfp(即 penguins dataframe,企鹅数据框)的数据框中,然后查看该数据表的前几行数据
# 加载企鹅数据集
dfp = sns.load_dataset('penguins')
# 查看数据集的前几行
dfp.head()
# 查看数据集的后几行
dfp.tail()
# 获取数据集的行数和列数
num_rows, num_columns = dfp.shape
# 打印行数(数据点/观测值数量)和列数(特征/测量指标数量)
print('数据点(或观测值)数量 =', num_rows) #数据点(或观测值)数量 = 344
print('特征(或测量指标)数量 =', num_columns)。#特征(或测量指标)数量 = 7还可以通过散点图来可视化数据:
# 绘制以体重为x轴、喙深度为y轴,按物种分类的散点图
sns.scatterplot(data=dfp, x="body_mass_g", y="bill_depth_mm", hue="species")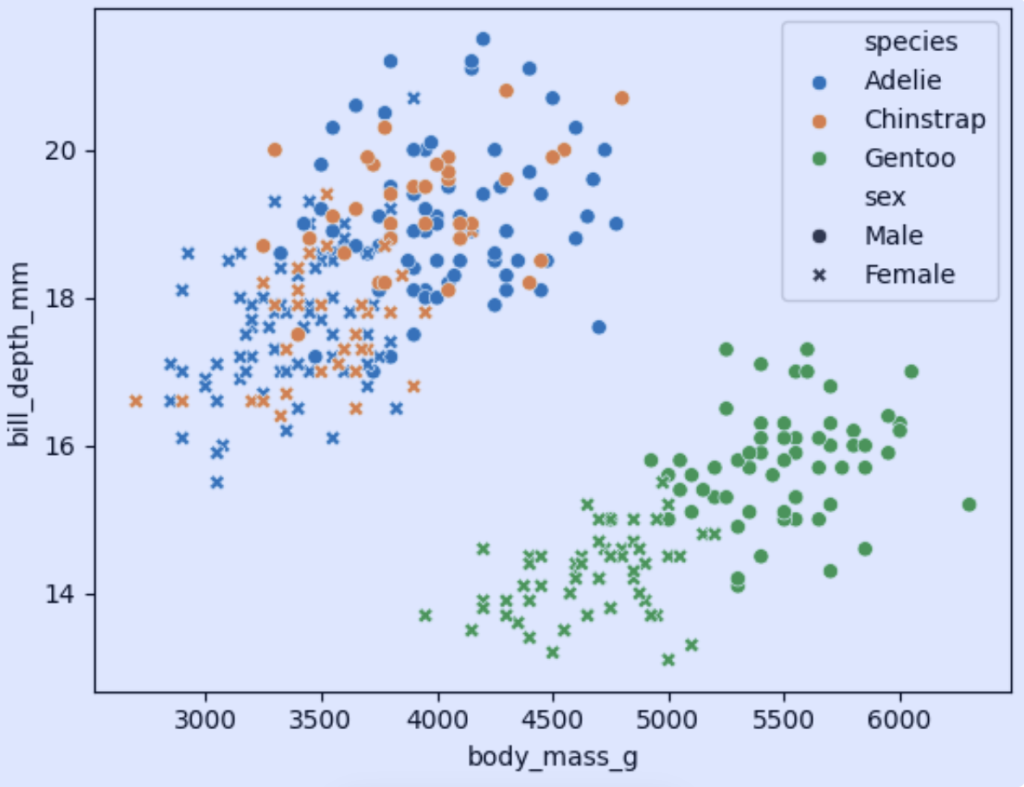
如果觉得上述散点图看起来有些拥挤,可以通过以下代码调整图形大小:
# 设置图形大小
plt.figure(figsize=(8, 8))
# 绘制以体重为x轴、喙深度为y轴,按岛屿分类的散点图
sns.scatterplot(data=dfp, x="body_mass_g", y="bill_depth_mm", hue="island")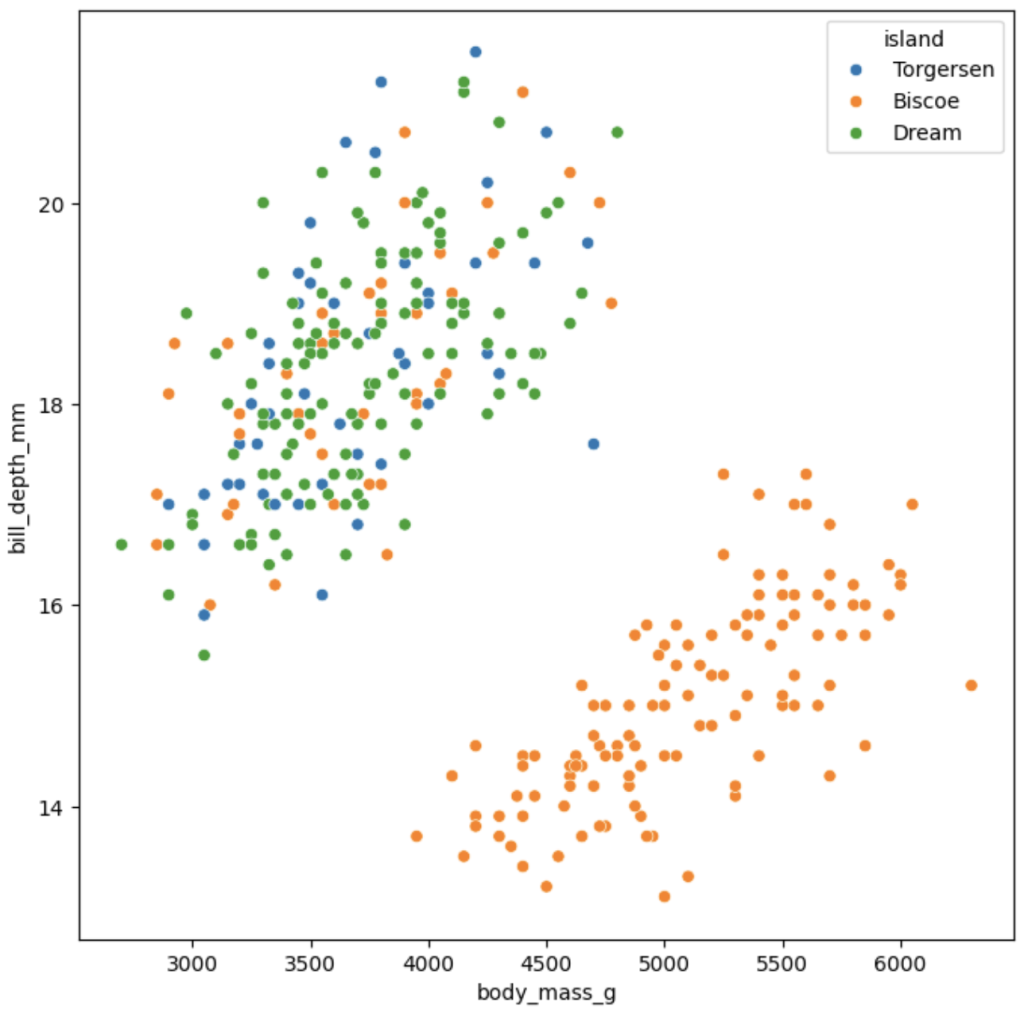
# 如果不通过可视化打印整个数据集(取消注释后执行该单元格,查看完后需重新注释以清除大量输出)
# print(dfp.to_string())
# 查看“species”列中的唯一值
dfp.species.unique()
# 也可以这样写,访问“species”列的数据
dfp2['species']
dfp2['species'].unique()# 数据集中存在一些无效值(NaN,即 “非数字”),统计每列中无效值(NaN)的数量
dfp.isna().sum()
#输出:
species 0
island 0
bill_length_mm 2
bill_depth_mm 2
flipper_length_mm 2
body_mass_g 2
sex 11
dtype: int64
# 找出包含无效值(NaN)的行
NaN_rows = dfp[dfp.isna().any(axis=1)]
# 查看这些包含无效值的行
NaN_rows
# 打印包含无效值的行的索引
print(NaN_rows.index)
//输出Index([3, 8, 9, 10, 11, 47, 246, 286, 324, 336, 339], dtype='int64')
# 通过索引查看包含无效值的行
dfp.loc[NaN_rows.index]dfp.isna()
isna() 是 Pandas 中用于检测缺失值的方法。它会遍历 dfp 这个 DataFrame 的每个元素,若元素是 NaN(或其他 Pandas 认定的缺失值形式,比如 None 等),就返回 True;否则返回 False。
执行后,会得到一个和原 dfp 形状完全相同 的布尔型 DataFrame(每个位置都是 True 或 False,标记对应位置是否为缺失值)。
any(axis = 1)
any() 是用于判断 “是否存在满足条件的元素” 的方法。
axis=1 表示 按 “行” 进行判断:对于每一行,只要这一行里有 任意一个 元素是 True(即原数据中该行存在 NaN),整个行就会被标记为 True;只有当一行里所有元素都是 False(即该行没有 NaN),才会标记为 False。
执行后,会得到一个布尔型的 Series(长度等于原 DataFrame 的行数),每个元素标记对应行是否包含 NaN。
处理缺失值
均值填充(Mean Imputation)
处理缺失值的一种方法是用 “合理” 的值填充这些缺失值。均值填充的实现方法简单(如下述仅用一行代码即可实现),但需要注意的是,这种方法会改变原始数据集。
均值填充的优点是可以保持样本数量不变;缺点是它可能会改变数据的某些统计特性(均值得以保持,但方差和协方差会减小)
下面以数值型特征用均值填充、缺失的性别(sex)特征均视为 “雌性(Female)” 为例进行处理:
# 对缺失值进行填充:数值型特征用均值填充,性别特征缺失值填充为'Female'
dfp1 = dfp.fillna({
'bill_length_mm': dfp['bill_length_mm'].mean(),
'bill_depth_mm': dfp['bill_depth_mm'].mean(),
'flipper_length_mm': dfp['flipper_length_mm'].mean(),
'body_mass_g': dfp['body_mass_g'].mean(),
'sex': 'Female'
})dfp.fillna
dfp 是 Pandas 的 DataFrame 类型
dfp.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)value:用于填充缺失值的具体值或字典 / Series/DataFrame
案例中只显示传入Value参数,传入了一个字典 {...} 作为 value 的值,用于指定不同列的缺失值填充规则
对性别特征(sex),用固定字符串 'Female' 填充缺失值。
对数值型特征(bill_length_mm、bill_depth_mm 等),用各列自身的均值(dfp['列名'].mean())填充缺失值;
查看处理结果
# 查看处理后的数据框中,原本包含缺失值的行的情况(缺失值已被填充)
dfp1.loc[NaN_rows.index]
# 查看处理前的数据框中,包含缺失值的行的情况(原始缺失值)
dfp.loc[NaN_rows.index]species(物种) | island(岛屿) | bill_length_mm(喙长度:毫米) | bill_depth_mm(喙深度:毫米) | flipper_length_mm(鳍长度:毫米) | body_mass_g(体重:克) | sex(性别) | |
|---|---|---|---|---|---|---|---|
| 3 | Adelie(阿德利企鹅) | Torgersen(托尔格森岛) | 43.92193 | 17.15117 | 200.915205 | 4201.754386 | Female(雌性) |
| 8 | Adelie(阿德利企鹅) | Torgersen(托尔格森岛) | 34.10000 | 18.10000 | 193.000000 | 3475.000000 | Female(雌性) |
| 9 | Adelie(阿德利企鹅) | Torgersen(托尔格森岛) | 42.00000 | 20.20000 | 190.000000 | 4250.000000 | Female(雌性) |
| 10 | Adelie(阿德利企鹅) | Torgersen(托尔格森岛) | 37.80000 | 17.10000 | 186.000000 | 3300.000000 | Female(雌性) |
| 11 | Adelie(阿德利企鹅) | Torgersen(托尔格森岛) | 37.80000 | 17.30000 | 180.000000 | 3700.000000 | Female(雌性) |
| 47 | Adelie(阿德利企鹅) | Dream(梦岛) | 37.50000 | 18.90000 | 179.000000 | 2975.000000 | Female(雌性) |
| 246 | Gentoo(巴布亚企鹅) | Biscoe(比斯科岛) | 44.50000 | 14.30000 | 216.000000 | 4100.000000 | Female(雌性) |
| 286 | Gentoo(巴布亚企鹅) | Biscoe(比斯科岛) | 46.20000 | 14.40000 | 214.000000 | 4650.000000 | Female(雌性) |
| 324 | Gentoo(巴布亚企鹅) | Biscoe(比斯科岛) | 47.30000 | 13.80000 | 216.000000 | 4725.000000 | Female(雌性) |
| 336 | Gentoo(巴布亚企鹅) | Biscoe(比斯科岛) | 44.50000 | 15.70000 | 217.000000 | 4875.000000 | Female(雌性) |
| 339 | Gentoo(巴布亚企鹅) | Biscoe(比斯科岛) | 43.92193 | 17.15117 | 200.915205 | 4201.754386 | Female(雌性) |
在数据处理过程中,检查处理结果是一种良好的习惯。但对于大型数据集而言,由于无法逐行打印并检查每个数据项以确保没有引入错误,因此需要采用其他有效的检查方法。
- 一种方法是绘制处理前后数据集的图形,观察图形是否基本一致
# 绘制处理前数据集的散点图(以体重为x轴,喙深度为y轴)
sns.scatterplot(data=dfp, x="body_mass_g", y="bill_depth_mm")- 此外,可以使用 describe () 函数查看数据的统计摘要,对比处理前后数据的统计特性是否大致相同
# 查看处理前数据集的统计摘要
dfp.describe()
# 查看处理后数据集的统计摘要
dfp1.describe()bill_length_mm(喙长度:毫米) | bill_depth_mm(喙深度:毫米) | flipper_length_mm(鳍长度:毫米) | body_mass_g(体重:克) | |
|---|---|---|---|---|
| count(数量) | 342.000000 | 342.000000 | 342.000000 | 342.000000 |
| mean(均值) | 43.921930 | 17.151170 | 200.915205 | 4201.754386 |
| std(标准差) | 5.459584 | 1.974793 | 14.061714 | 801.954536 |
| min(最小值) | 32.100000 | 13.100000 | 172.000000 | 2700.000000 |
| 25%(第一四分位数) | 39.225000 | 15.600000 | 190.000000 | 3550.000000 |
| 50%(中位数) | 44.450000 | 17.300000 | 197.000000 | 4050.000000 |
| 75%(第三四分位数) | 48.500000 | 18.700000 | 213.000000 | 4750.000000 |
| max(最大值) | 59.600000 | 21.500000 | 231.000000 | 6300.000000 |
删除包含空值的行 Row Deletion
# 查看包含缺失值的行
dfp.loc[NaN_rows.index]
# 统计每列中缺失值(NaN)的数量
dfp.isna().sum()
# 删除包含缺失值的行,得到新的数据集dfp2
dfp2 = dfp.dropna()
#处理后的数据集 dfp2 中已不存在 NaN 值。统计dfp2中每列的缺失值数量,以验证这一点:
dfp2.isna().sum()# 查看删除缺失值后的数据集dfp2
dfp2注意到 dfp2 最左侧列的索引值不连续(例如,缺少索引 3)。我们可以使用 reset_index () 函数重置索引,但需要注意删除原始索引,否则原始索引会作为新列保留在数据框中:
# 错误的做法:这样会保留原始索引作为新列
# dfp2 = dfp2.reset_index()
# 正确的做法:重置索引并删除原始索引列
dfp2 = dfp2.reset_index(drop=True)
# 查看重置索引后的dfp2
dfp2列表删除法可得到无偏但效率更低的估计量,
在统计学中,“估计量效率” 衡量的是在相同无偏性前提下,估计量的方差大小:样本量的减少总会导致方差增大,意味着其结果波动更大、不确定性更高,即 “效率更低”。若两个估计量均无偏(即估计值的期望等于真实总体参数),则方差更小的估计量效率更高,因为它的估计结果更稳定、更接近真实值;
数据可视化
接下来,我们将通过几种可视化方式来探索清理后的企鹅数据集
散点图
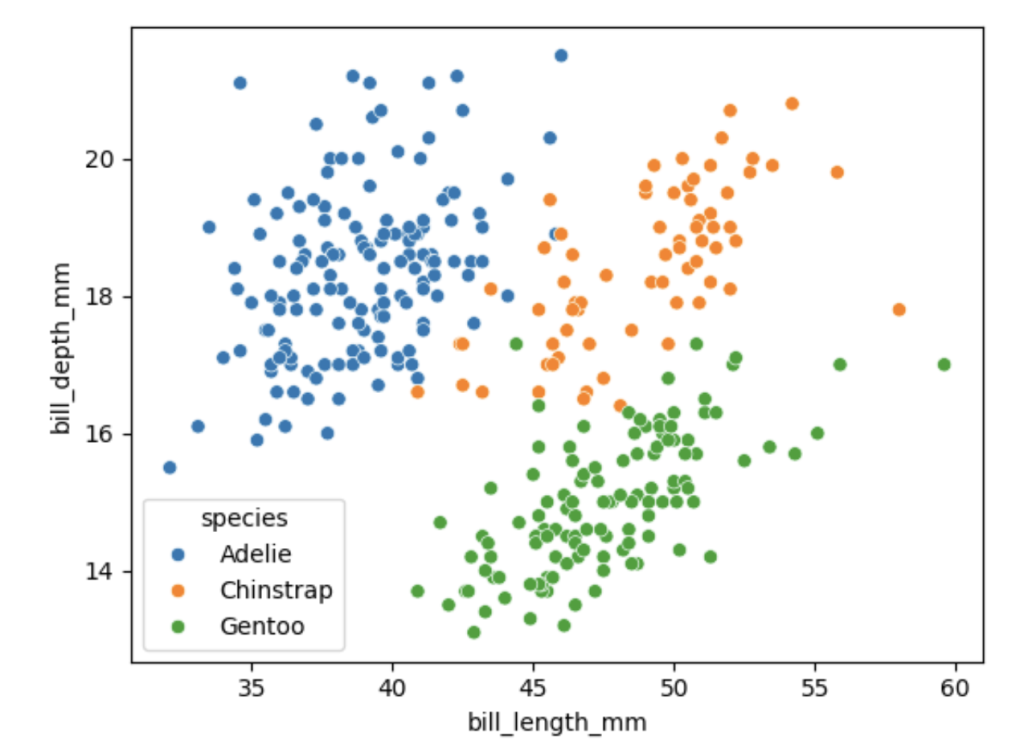
# 绘制以喙长度为x轴、喙深度为y轴,按物种分类的散点图
sns.scatterplot(data=dfp2, x="bill_length_mm", y="bill_depth_mm", hue="species")scatterplot
seaborn.scatterplot(data=None, x=None, y=None, hue=None, size=None,
style=None, alpha=None, s=None, ...)基础数据参数
data:传入的数据集(通常是 Pandas DataFrame),后续参数可直接使用列名。x/y:指定散点图的横轴和纵轴变量(必选,通常为数值型)。
分组与样式参数
hue:按指定变量对数据分组,并用不同颜色区分(如按 “性别” 分组,不同性别点的颜色不同)。size:按指定变量设置点的大小(如用 “年龄” 决定点的大小)。style:按指定变量设置点的形状(如按 “类别” 用圆形 / 三角形区分)。
外观参数
alpha:点的透明度(0~1,值越小越透明,避免点重叠时看不清)。s:点的固定大小(若不通过size动态设置,可直接指定固定值,如s=100)。
成对关系图
# 绘制按物种分类的成对关系图
sns.pairplot(dfp2, hue='species')pairplot
seaborn.pairplot(data, hue=None, hue_order=None, palette=None, vars=None, x_vars=None, y_vars=None, kind=’scatter’, diag_kind=’auto’, corner=False, …)
基础数据参数
vars:指定要分析的变量列表(默认使用所有数值型变量)。例如vars=['身高', '体重', '年龄']只分析这三个变量。data:必选,输入的数据集(通常是 Pandas DataFrame)。x_vars/y_vars:分别指定横轴和纵轴的变量(可用于绘制非对称的关系图)。
分组与样式参数
hue:按指定的类别变量分组,用不同颜色区分各组数据(如按 “性别” 分组,不同性别点的颜色不同)。palette:指定颜色方案(如palette='Set2')。
图表类型参数
kind:非对角线位置的图表类型,默认'scatter'(散点图),可选'reg'(添加回归线)、'kde'(核密度图,展示密度分布)。diag_kind:对角线位置的单变量分布图类型,默认'auto'(数值型变量用直方图),可选'hist'(直方图)、'kde'(核密度图)。
布局参数
corner:是否只绘制左下角的三角区域(避免重复,因为变量 A 与 B 的关系和 B 与 A 的关系相同),corner=True 可简化图表。
图中每个子图展示两个变量之间的关系: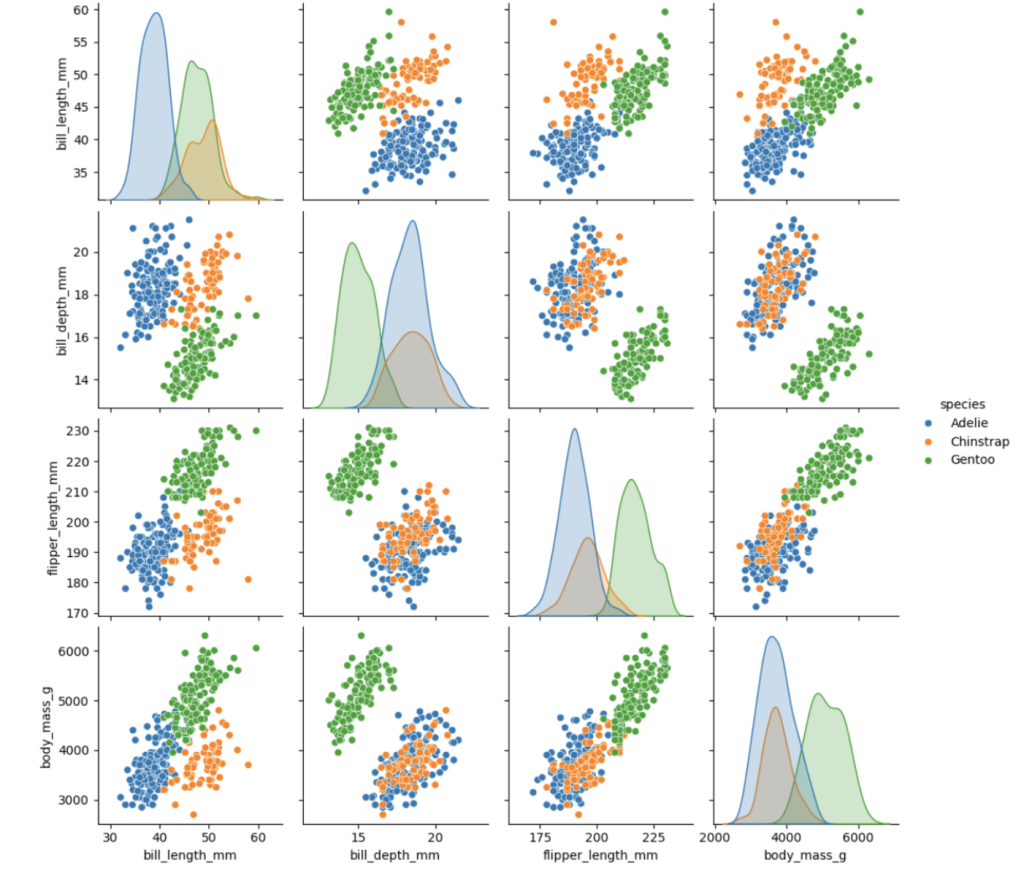
- 非对角线子图:是散点图,用于观察两个变量(如
bill_length_mm和bill_depth_mm)之间的相关性(正相关、负相关或无明显相关),还能通过颜色区分不同类别(这里是企鹅的不同物种species),看出不同类别在变量关系上的差异。 - 对角线子图:是单变量的分布直方图(或核密度图),展示单个变量(如
bill_length_mm)自身的分布特征(如是否对称、峰值位置等),同时不同颜色也能体现该变量在不同类别中的分布差异。
# 绘制按物种分类的角形成对关系图(仅显示下三角部分)
# 参考链接:https://seaborn.pydata.org/generated/seaborn.pairplot.html
sns.pairplot(dfp2, corner=True, hue='species', height=1.5)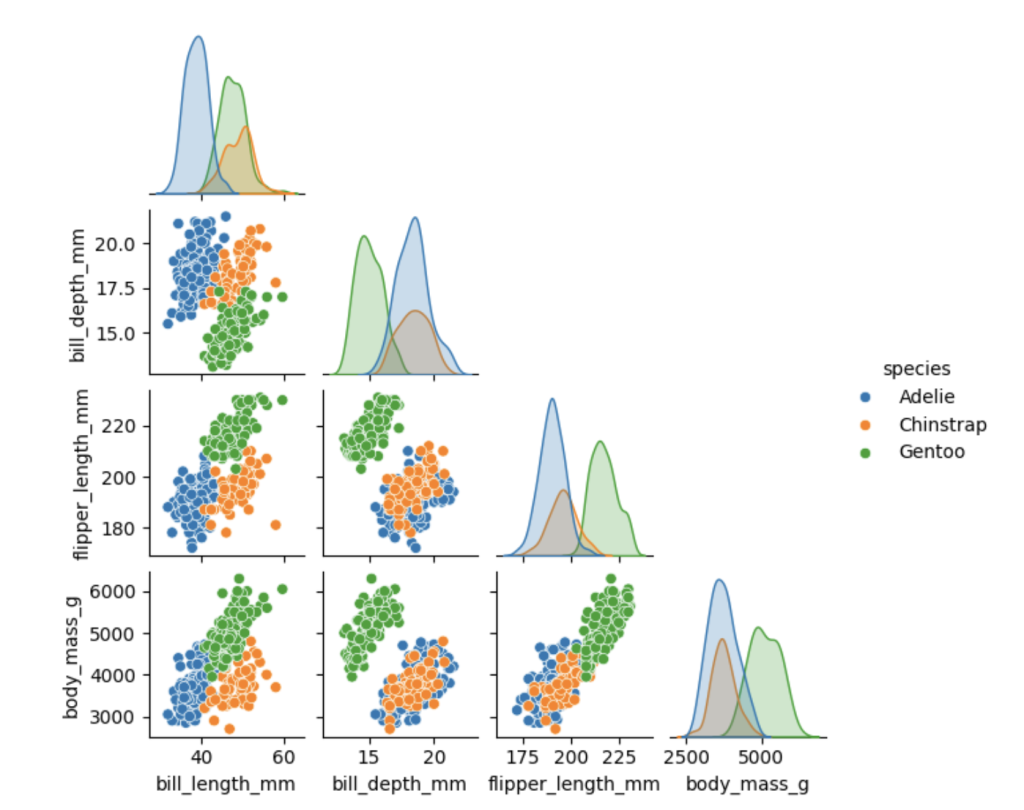
# 绘制按物种分类的成对关系图,对角线为核密度估计图,下三角添加核密度曲线
g = sns.pairplot(dfp2, diag_kind="kde", hue='plot(dfp2, diag_kind="kde", hue='species')
g.map_lower(sns.kdeplot, levels=4, color=".2")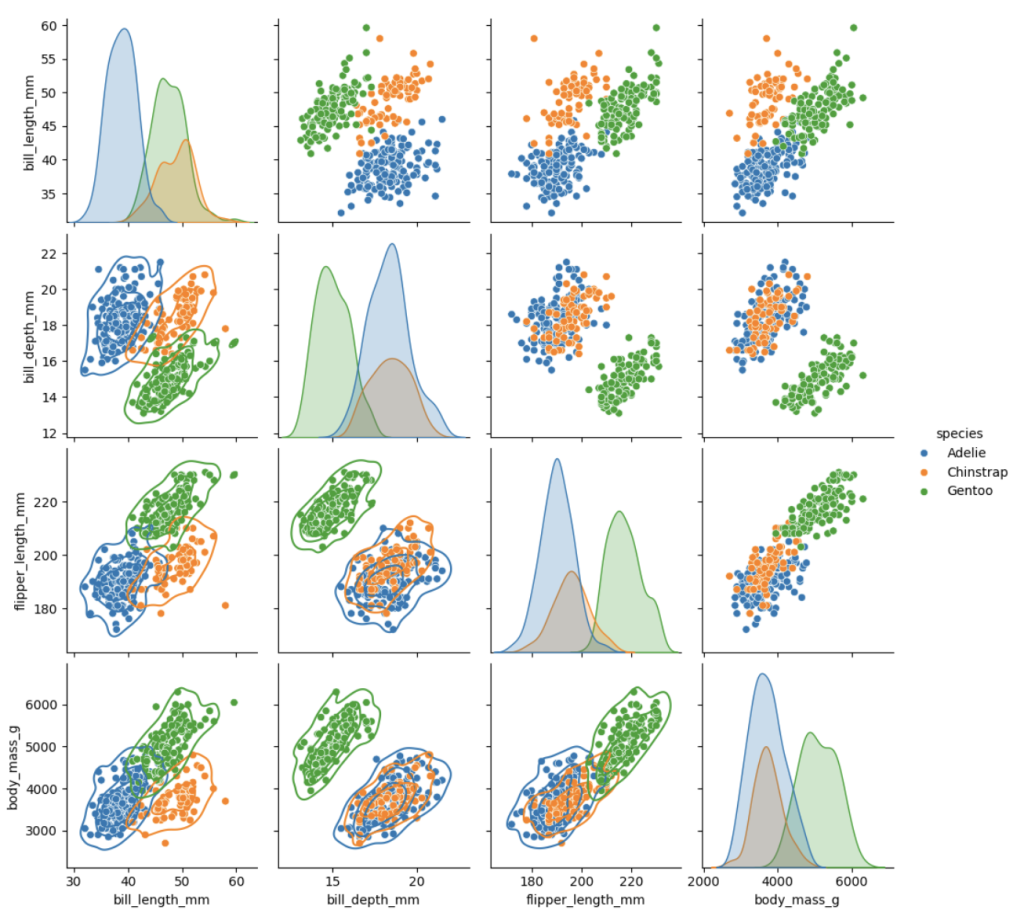
此处为一个成对关系图,对角线为各特征的核密度估计图,非对角线为不同特征之间的散点图,下三角部分还添加了 4 个级别的核密度曲线,不同物种的企鹅用不同颜色标注
如何分离数据聚类(具有共同特征的数据项)
查看物种聚类
# 散点图(喙长vs喙深,按物种着色,突出聚类)
sns.scatterplot(data=dfp2, x="bill_length_mm", y="bill_depth_mm",hue="species")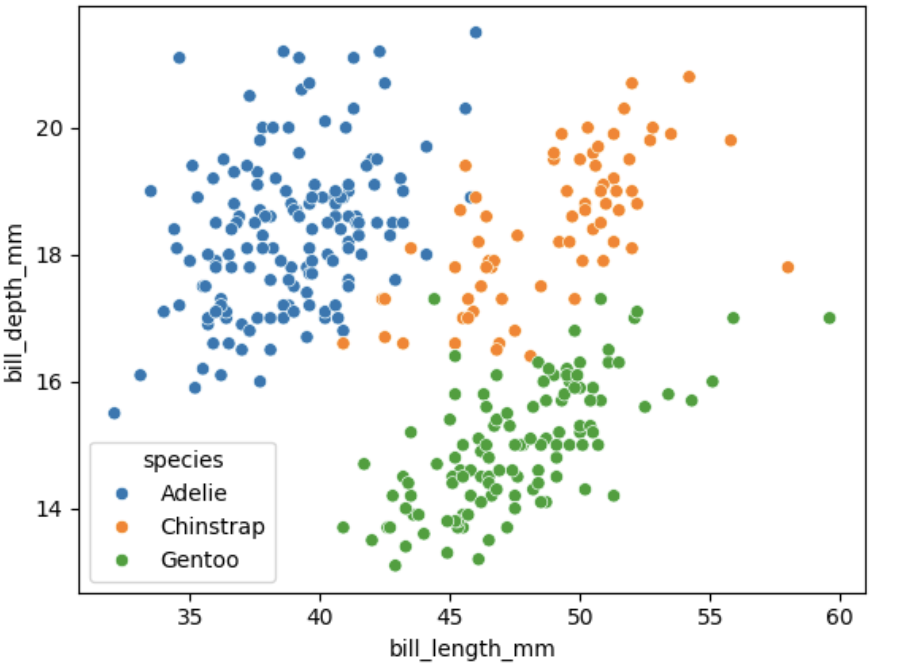
访问列数据与唯一值
# 访问物种列的所有数据
dfp2['species']
# 查看物种列的唯一值(去重)
dfp2['species'].unique()
# 输出结果:array (['Adelie', 'Chinstrap', 'Gentoo'], dtype=object)
unique() 函数的核心作用就是从指定的特征(列)中,将所有重复出现的值 “去重”,只保留每一个不同值的 “唯一实例”,最终返回该特征下所有不重复的取值集合。该方法可让代码自动识别唯一特征值,无需人工查看。创建数据子集
有时,根据某个特征值将数据集分离成不同的子集是很有用的。例如,如果我们选择按 “species”(物种)特征分离数据,可以使用以下命令获取仅包含阿德利企鹅(Adelie)数据的新数据框:
dfp2.loc[dfp2['species'] == 'Adelie']我们可以创建三个数据子集,分别对应三种企鹅物种:
# 创建阿德利企鹅(Adelie)的数据子集
dfA = dfp2.loc[dfp2['species'] == 'Adelie']
# 创建帽带企鹅(Chinstrap)的数据子集
dfC = dfp2.loc[dfp2['species'] == 'Chinstrap']
# 创建巴布亚企鹅(Gentoo)的数据子集
dfG = dfp2.loc[dfp2['species'] == 'Gentoo']原理:
dfp2.loc [布尔数组] 会保留布尔值为 True 的行,形成新的数据框。
dfp2 [‘species’] == ‘Adelie’ 会返回一个布尔数组,行索引对应的值为 True 表示该行为阿德利企鹅。
用matplotltlib单独绘制聚类
# 提取阿德利企鹅的喙长和喙深数据,转换为数组
blA = np.array(dfA['bill_length_mm'].tolist())
bdA = np.array(dfA['bill_depth_mm'].tolist())
# 绘制阿德利企鹅散点图(蓝色)
plt.scatter(blA, bdA, color='blue')
# 提取帽带企鹅的喙长和喙深数据,转换为数组
blC = np.array(dfC['bill_length_mm'].tolist())
bdC = np.array(dfC['bill_depth_mm'].tolist())
# 绘制帽带企鹅散点图(橙色)
plt.scatter(blC, bdC, color='orange')
# 提取巴布亚企鹅的喙长和喙深数据,转换为数组
blG = np.array(dfG['bill_length_mm'].tolist())
bdG = np.array(dfG['bill_depth_mm'].tolist())
# 绘制巴布亚企鹅散点图(绿色)
plt.scatter(blG, bdG, color='green')
# 设置坐标轴标签
plt.xlabel('bill_length_mm(喙长毫米)')
plt.ylabel('bill_depth_mm(喙深毫米)')
# 设置图例(右下角)
plt.legend(['Adelie(阿德利企鹅)', 'Chinstrap(帽带企鹅)', 'Gentoo(巴布亚企鹅)'], loc='lower right')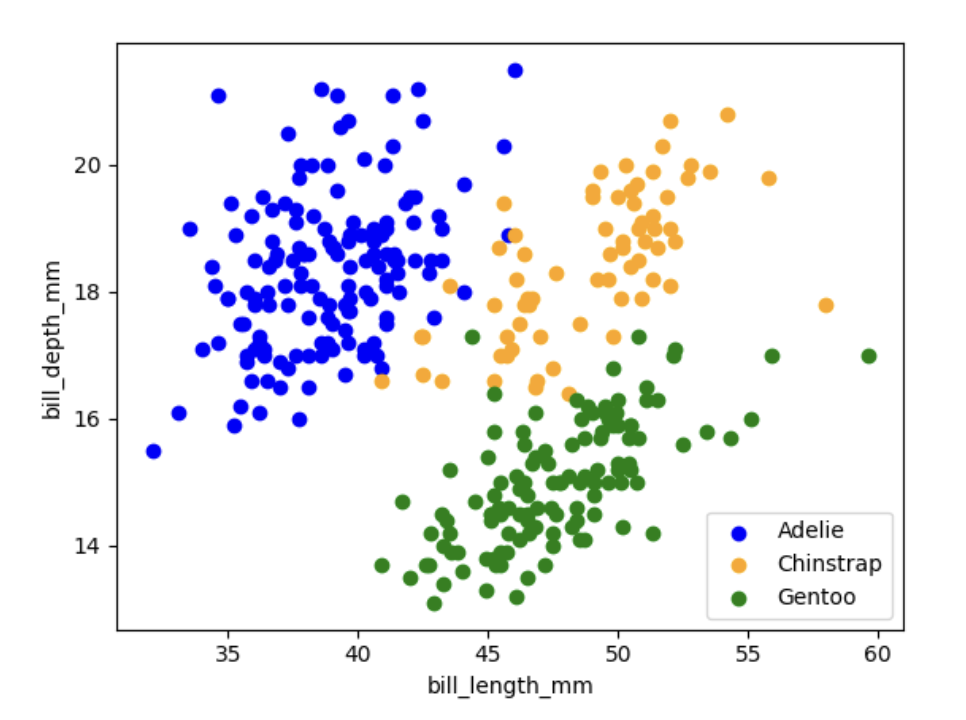
通过统计摘要验证数据是否合理:
# 阿德利企鹅数据的统计摘要
dfA.describe()默认情况下,该函数仅对数值型列生效(非数值列如字符串、日期会被自动忽略),返回以下统计指标(按输出顺序):
| 统计指标 | 含义 |
|---|---|
count | 非缺失值的数量(可判断是否存在缺失数据) |
mean | 平均值(反映数据的集中趋势) |
std | 标准差(反映数据的离散程度,值越大说明数据波动越大) |
min | 最小值 |
25% | 第一四分位数(下四分位数,25% 的数据小于该值) |
50% | 第二四分位数(中位数,50% 的数据小于该值,不受极端值影响) |
75% | 第三四分位数(上四分位数,75% 的数据小于该值) |
max | 最大值 |
数组切片操作
numpy 数组支持切片操作,可选择部分数据:
# 查看blA数组的第3到第5个元素(索引2到4,左闭右开)
blA[2:5]
# 查看blA数组除最后5个元素外的所有数据
blA[:-5]统计子集行数
.shape属性:
作用是 快速获取 DataFrame 的 “维度信息”—— 返回一个元组 (行数, 列数),直观反映数据的规模大小。
# 方法1:使用shape[0]获取行数
print('dfA(阿德利企鹅)行数 =', dfA.shape[0], '; dfC(帽带企鹅)行数 =', dfC.shape[0], '; dfG(巴布亚企鹅)行数 =', dfG.shape[0])
输出结果:dfA(阿德利企鹅)行数 = 146 ; dfC(帽带企鹅)行数 = 68 ; dfG(巴布亚企鹅)行数 = 119# 方法2:忽略列数(用_占位)
rA, _ = dfA.shape
rC, _ = dfC.shape
rG, _ = dfG.shape
print('dfA(阿德利企鹅)行数 =', rA, '; dfC(帽带企鹅)行数 =', rC, '; dfG(巴布亚企鹅)行数 =', rG)
输出结果:dfA(阿德利企鹅)行数 = 146 ; dfC(帽带企鹅)行数 = 68 ; dfG(巴布亚企鹅)行数 = 119k 近邻算法:核心直觉
k 近邻(k-NN)算法简单而强大,仅依赖特征空间中的 “邻近性” 概念,以下介绍其分类原理。
训练集 Training set
训练集是用于建模的数据集合:
- 每行对应一个观测值。
- 每个观测值包含:
- 数值特征向量 \(\boldsymbol{x} = (x_1, x_2, …)^T\)
- 分类型标签 y
- 无需使用数据集中的所有变量,通常选择与分类最相关的特征子集。
几何视角
- 每个观测值 x 可视为 n 维空间中的一个点。
- 当 n=2 或 3 时,可直接在平面或空间中可视化。
- 当 n>3 时,无法直接可视化,但向量、距离和邻域的数学概念仍然适用。
- 每个观测值根据其标签 y 着色。
k 近邻算法的核心问题:
给定一个新数据点,其在特征空间中最近的 k 个邻居中,哪个类别占主导?
企鹅示例
以帕尔默企鹅数据集为例:
- 选择两个数值特征:\(x = (bill\_length\_mm, bill\_depth\_mm)^T\)(喙长、喙深)
- 类别标签:\(y \in \{Adelie, Chinstrap, Gentoo\}\)(三种企鹅物种)
可视化结果:
- 按物种着色(蓝色:阿德利企鹅,橙色:帽带企鹅,绿色:巴布亚企鹅),数据点自然形成聚类。
- 对于新测量的企鹅数据,可通过查找其最近的 k 个邻居,采用多数投票法确定物种类别。
新观测值分类流程
假设研究人员收集到新的企鹅测量数据,分类步骤如下:
- 将新观测值作为点绘制在同一特征空间中。
- 计算该点与训练集中所有点的距离。
- 识别距离最近的 k 个点(“邻居”)。
- 通过邻居的多数投票结果为新点分配标签。
示例:
- 选取每种物种的前 20 个数据点作为训练集。
- 引入 3 个 “新点”(用叉号 × 表示)进行测试。
- 视觉上,每个叉号靠近一个聚类,算法据此分配物种标签。
现实中,新数据是未知的,k 近邻算法的优势在于无需复杂模型,仅基于训练集的几何特征即可预测,灵活性强。
k 值的选择
k 值的选择至关重要:
- 小 k 值:对噪声敏感,易过拟合。
- 大 k 值:平滑决策边界,但可能模糊类别间的差异。
因此,k 近邻算法需在简单性、直觉性和灵活性之间平衡。
可视化演示:新点分类
# 绘制每种物种的前20个数据点(训练集)
plt.scatter(blA[0:20], bdA[0:20], color='blue')
plt.scatter(blC[0:20], bdC[0:20], color='orange')
plt.scatter(blG[0:20], bdG[0:20], color='green')
# 设置图例和坐标轴标签
plt.legend(['Adelie(阿德利企鹅)', 'Chinstrap(帽带企鹅)', 'Gentoo(巴布亚企鹅)'], loc='lower right')
plt.xlabel('bill_length_mm(喙长毫米)')
plt.ylabel('bill_depth_mm(喙深毫米)')
# 选取每种物种倒数第4个数据点作为“新观测值”
indx = -4
# 绘制新观测值(叉号,放大显示)
plt.scatter(blA[indx], bdA[indx], color='blue', marker='x', s=500)
plt.scatter(blC[indx], bdC[indx], color='orange', marker='x', s=500)
plt.scatter(blG[indx], bdG[indx], color='green', marker='x', s=500)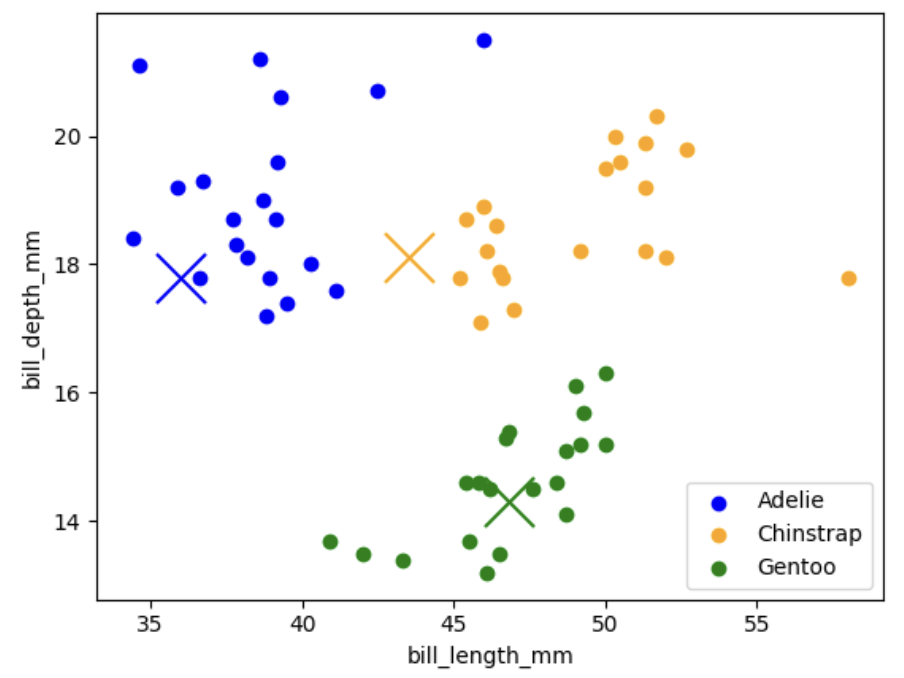
分类结果分析
- 绿色叉号位于巴布亚企鹅(Gentoo)聚类中心,可分类为巴布亚企鹅。
- 蓝色叉号虽不在阿德利企鹅(Adelie)聚类中心,但远离其他聚类,可安全分类为阿德利企鹅。
- 橙色叉号存在歧义:略靠近帽带企鹅(Chinstrap)聚类,但喙深特征与阿德利企鹅接近,喙长特征也与部分阿德利企鹅重叠,需通过投票确定类别。
可解释性问题
上述示例体现了机器学习中的可解释性难题:
- 前两个分类结果直观且可解释,第三个则存在不确定性。
- 可解释性在金融、医疗诊断等领域至关重要,例如基于机器学习的投资决策或疾病诊断,需要明确的推理依据。
k 近邻算法:数学细节
符号定义
- 训练集中的每个数据点用下标索引:特征向量 \(x_1, x_2, x_3, …\),对应标签 \(y_1, y_2, y_3, …\)(即可视化中的彩色点)。
- 新观测值:\(x^*\),需为其分配标签。

距离计算
计算新观测值 \(x^*\) 与训练集中每个点 \(x_i\) 的距离,最常用的距离度量方法是欧几里得距离(Euclidean distance),其计算公式为: $d(x, x_i) = \sqrt{\sum_{j=1}^{d}(x_j – x_{ij})^2}$

分类规则
找到使距离最小的索引 i,将该索引对应的标签 \(y_i\) 分配给新观测值 \(x^*\)。


预测规则:回归任务
在回归任务中,KNN 算法通常通过计算 K 个近邻的数值的算术平均值来确定新样本的预测值。新样本的预测值\(\hat{y}\)可表示为:
\(\hat{y} = \frac{1}{K} \sum_{i \in \mathcal{N}_K(x)} y_i\)
示例
若 K=3,且 3 个近邻的数值分别为 10、15、20,则新样本的预测值为:
\(\hat{y} = \frac{10+15+20}{3} = 15\)
加权 K 近邻(Weighted KNN)
加权 K 近邻算法会给距离新样本更近的近邻分配更大的权重(即更高的重要性)。常用的权重函数为:
\(w_i = \frac{1}{d(x, x_i) + \varepsilon}\)
其中\(\varepsilon\)是一个极小的正数,用于避免因距离\(d(x, x_i) = 0\)导致的分母为零问题。
分类任务
在加权 K 近邻的分类任务中,新样本的预测标签通过 “加权多数投票” 确定,公式为:
\(\hat{y} = \arg\max_{c \in \mathcal{C}} \sum_{i \in \mathcal{N}_K(x)} w_i \mathbb{I}\{y_i = c\}\)
回归任务
在加权 K 近邻的回归任务中,新样本的预测值通过 “加权平均值” 计算,公式为:
\(\hat{y} = \frac{\sum_{i \in \mathcal{N}_K(x)} w_i y_i}{\sum_{i \in \mathcal{N}_K(x)} w_i}\)
示例
考虑一个新样本x,以及 3 个训练样本\(x_1\)、\(x_2\)、\(x_3\),它们与x的距离分别为:
\(d(x, x_1) = 1, \quad d(x, x_2) = 2, \quad d(x, x_3) = 3\)
采用权重函数\(w_i = \frac{1}{d(x, x_i) + \varepsilon}\),取\(\varepsilon = 0.001\)(避免分母为零),则 3 个训练样本的权重分别为:
\(w_1 = \frac{1}{1 + 0.001} = \frac{1}{1.001}, \quad w_2 = \frac{1}{2 + 0.001} = \frac{1}{2.001}, \quad w_3 = \frac{1}{3 + 0.001} = \frac{1}{3.001}\)
数值近似计算结果为:
\(w_1 \approx 0.9990, \quad w_2 \approx 0.4998, \quad w_3 \approx 0.3332\)
可见,\(w_1\)约为\(w_2\)的 2 倍、\(w_3\)的 3 倍,这体现了 “距离越近,权重越大” 的原则。
假设 3 个训练样本对应的目标数值分别为:
\(y_1 = 10, \quad y_2 = 15, \quad y_3 = 20\)
则加权 K 近邻回归的预测值为:
\(\hat{y} = \frac{w_1 y_1 + w_2 y_2 + w_3 y_3}{w_1 + w_2 + w_3} = \frac{(0.9990 \times 10) + (0.4998 \times 15) + (0.3332 \times 20)}{0.9990 + 0.4998 + 0.3332}\)
因此,预测值为:
\(\hat{y} = \frac{24.151}{1.832} \approx 13.18\)
可以看出,距离最近的样本\(x_1\)(权重最大)对最终预测结果的贡献最强。尽管\(y_2\)(15)和\(y_3\)(20)的数值更大,但它们与新样本的距离更远,权重更小,对预测结果的影响被削弱。最终预测值\(\hat{y} \approx 13.18\)更接近距离最近的样本\(x_1\)的数值(10),而非 3 个样本数值的简单平均值\(\frac{10 + 15 + 20}{3} = 15\)。
这一示例表明,加权 K 近邻回归会根据样本间的距离调整预测结果,让距离更近的样本在预测中发挥更大作用



hyperparameter 超参数
“hyper-” 表示 “超越、外层”,对应超参数 “训练外设定” 的属性;无前缀的 “parameter” 对应 “训练内学习” 的参数。超参数的选择需人工确定,后续可通过模型校准调整。
超参数是建模前需指定的参数,不由数据学习得到,k 近邻算法的关键超参数包括:
- k:需查找的最近邻居数量。
- p:距离度量的范数选择(如 p=1 为曼哈顿距离,p=2 为欧氏距离)。
为获得更优的建模效果,实践中建议遵循以下原则:
- 通过验证集或交叉验证调整参数(k,p),且确保p≥1(保证距离度量有效性);
- 采用分层抽样划分数据集,尤其是类别不平衡场景;
- 仅使用训练集的统计信息(均值、标准差)对特征进行标准化;
- 报告完整的性能指标集,包括精确率、召回率、F1 分数、特异度、平衡准确率等;
- 分析混淆矩阵的非对角线元素(错误分类样本),可发现系统性分类误差,进而指导特征工程优化或选择更合适的距离度量方式。
数据集二分与三分
为了优化超参数并评估模型性能,通常将数据集分为:
- 二分:训练集(用于初始化模型)和测试集(用于评估最终性能)。
- 三分:训练集、验证集(用于调优超参数)和测试集。
重要原则:
- 测试集需视为 “未知数据”,其结果不得用于进一步调优模型,仅用于模拟真实场景下的性能。
- 数据集比例无固定规则,常见二分比例为 75%(训练集)/25%(测试集),三分比例为 50%/25%/25%。
使用 scikit-learn 实现 k 近邻分类
接下来将使用 scikit-learn 库,基于清理后的企鹅数据集实现 k 近邻分类
# 查看清理后数据集的前5行
dfp2.head()
| species(物种) | island(岛屿) | bill_length_mm(喙长毫米) | bill_depth_mm(喙深毫米) | flipper_length_mm(鳍长毫米) | body_mass_g(体重克) | sex(性别) | |
|---|---|---|---|---|---|---|---|
| 0 | 阿德利企鹅(Adelie) | 托格森岛(Torgersen) | 39.1 | 18.7 | 181.0 | 3750.0 | 雄性(Male) |
| 1 | 阿德利企鹅(Adelie) | 托格森岛(Torgersen) | 39.5 | 17.4 | 186.0 | 3800.0 | 雌性(Female) |
| 2 | 阿德利企鹅(Adelie) | 托格森岛(Torgersen) | 40.3 | 18.0 | 195.0 | 3250.0 | 雌性(Female) |
| 3 | 阿德利企鹅(Adelie) | 托格森岛(Torgersen) | 36.7 | 19.3 | 193.0 | 3450.0 | 雌性(Female) |
| 4 | 阿德利企鹅(Adelie) | 托格森岛(Torgersen) | 39.3 | 20.6 | 190.0 | 3650.0 | 雌性(Female) |
提取特征与标签
使用数组切片提取数值特征(用于预测)和物种标签(待预测目标):
索引依据不同——loc 按「标签(行索引名、列名)」选数据,iloc 按「整数位置(从 0 开始)」选数据
冒号 : 代表 “选中对应维度的所有元素”
| 写法 | 含义 | 选中的行(直观第几行) |
|---|---|---|
iloc[0] | 位置 0 | 第一行 |
loc[0] | 标签 0 | 第一行 |
iloc[2:6] | 位置 2、3、4、5(左闭右开,不含 6) | 第 3~6 行 |
loc[2:6] | 标签 2、3、4、5、6(左闭右闭,含 6) | 第 3~7 行 |
# 提取数值特征(喙长、喙深、鳍长、体重),赋值给X
X = dfp2.iloc[:, 2:6].values
# 提取物种标签,赋值给y
y = dfp2.iloc[:, 0].values
# 查看第3行(索引2)的物种标签
dfp2.iloc[2, 0:1].values
#输出array(['Adelie'], dtype=object),一维数组,仅包含一个元素 'Adelie'dtype=object 说明数组中的元素是Python 对象类型(这里是字符串)
# 查看第2行(索引1)第 3 列到第 6 列(左闭右开区间)
dfp2.iloc[1, 2:6].values
#输出 array ([np.float64 (39.5), np.float64 (17.4), np.float64 (186.0), np.float64 (3800.0)], dtype=object)数据集二分:训练集与测试集
使用 scikit-learn 的 train_test_split 函数将数据集分为训练集(60%)和测试集(40%):
函数说明:
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2, # 测试集占比(默认0.25)
train_size=0.8, # 训练集占比(与test_size互补,可省略)
random_state=42, # 随机种子(固定结果,方便复现)
shuffle=True, # 是否打乱数据(默认True)
stratify=y # 分层抽样(保持目标变量y的分布与原数据一致,避免样本偏倚)
)# 导入train_test_split函数
from sklearn.model_selection import train_test_split
# 分割数据集(test_size=0.4表示测试集占40%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.40)返回值说明:
- X_train:训练集特征(60% 数据)
- X_test:测试集特征(40% 数据)
- y_train:训练集标签(与 X_train 对应)
- y_test:测试集标签(与 X_test 对应)
数据归一化
特征归一化可消除量纲影响,提高模型性能,使用 StandardScaler 函数将数据转换为均值为 0、方差为 1 的标准正态分布(\(Z \sim N(0, 1)\)):
# 导入StandardScaler
from sklearn.preprocessing import StandardScaler
# 初始化标准化器
scaler = StandardScaler()
# 用训练集数据拟合标准化器(仅使用训练集,避免测试集信息泄露)
scaler.fit(X_train)
# 对训练集和测试集进行标准化转换
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)注意:仅使用训练集数据拟合标准化器,测试集需视为未知数据,避免数据泄露。
拟合 k 近邻模型
使用曼哈顿距离(p=1,也称为出租车距离),设置 k=2(最近的 2 个邻居):
# 导入KNeighborsClassifier
from sklearn.neighbors import KNeighborsClassifier
# 初始化分类器(n_neighbors=2表示k=2,p=1表示曼哈顿距离)
classifier = KNeighborsClassifier(n_neighbors=2, p=1)
# 用训练集拟合模型
classifier.fit(X_train, y_train)
#输出结果:KNeighborsClassifier (n_neighbors=2, p=1)预测测试集
使用训练好的模型预测测试集标签:
# 预测测试集标签
y_pred = classifier.predict(X_test)模型性能评估
通过混淆矩阵、分类报告和准确率评分评估模型性能:
# 导入评估指标
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
# 计算混淆矩阵
cm = confusion_matrix(y_test, y_pred)
# 计算分类报告
clsrep = classification_report(y_test, y_pred)
# 计算准确率
accsc = accuracy_score(y_test, y_pred)
# 打印结果
print("混淆矩阵:")
print(cm)
print("\n分类报告:")
print(clsrep)
print("准确率:", accsc)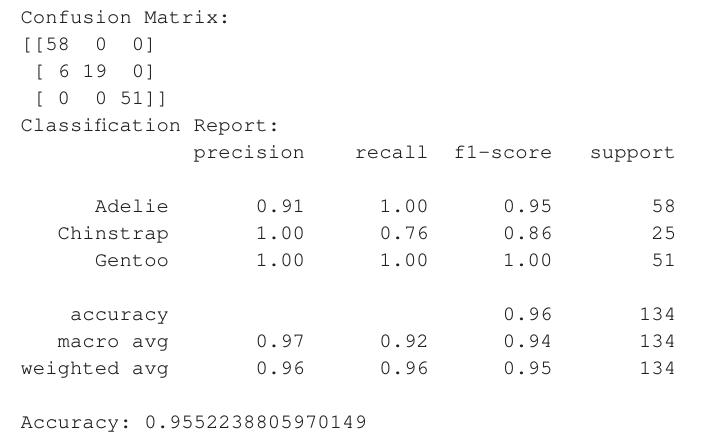
混淆矩阵详解
混淆矩阵是正方形矩阵,行数和列数等于标签的唯一值数量(此处为 3,对应三种企鹅)。
- 第 i 行第 j 列的数值表示:测试集中实际属于第 i 类,但被模型预测为第 j 类的数据点数量。
- 对角线元素:预测正确的数量。
- 非对角线元素:预测错误的数量。
可视化混淆矩阵:
# 导入混淆矩阵可视化工具
from sklearn.metrics import ConfusionMatrixDisplay
# 可视化混淆矩阵
cmplot = ConfusionMatrixDisplay(cm, display_labels=classifier.classes_)
cmplot.plot()
plt.show()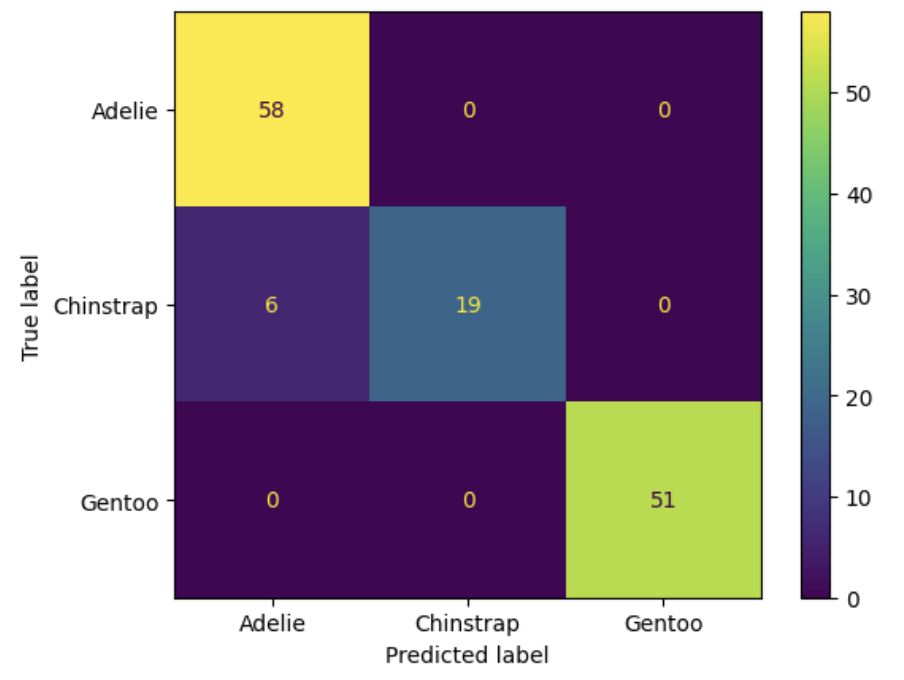
准确率计算
准确率 = 正确预测的样本数 / 总样本数 = 对角线元素之和 / 矩阵所有元素之和:
# 手动计算准确率(验证)
correct = cm[0,0] + cm[1,1] + cm[2,2]
total = cm.sum()
accuracy = correct / total
print("手动计算准确率:", accuracy)
# 也可使用 numpy 的 trace 函数(计算对角线元素之和)简化计算:
# 使用np.trace计算对角线元素之和
import numpy as np
accuracy = np.trace(cm) / cm.sum()
print("使用np.trace计算准确率:", accuracy)k 近邻算法的回归应用
前文介绍了 k 近邻算法在分类任务中的应用(预测离散类别标签),该算法也可用于回归任务(预测连续值标签)。
回归任务定义:回归任务中,特征和标签均为连续值(如根据云量、日照时长、温度等预测降雨量)。
机器学习中的基本任务类型:回归(Regression):用于预测连续值。例如,预测房价或股票价格。分类(Classification):用于预测离散的类别标签。例如,判断一封邮件是垃圾邮件还是正常邮件。聚类(Clustering):用于将数据分组,使得同一组内的数据点相似,不同组之间的数据点不相似
KNN 算法的核心应用是分类任务(离散标签预测)和回归任务(连续数值预测)。
K 近邻算法通常不用于聚类任务,核心原因是聚类属于无监督学习(无标签数据),而 KNN 本质是依赖标签的监督学习算法,两者核心逻辑不匹配。
- k 近邻回归原理:
将连续变量离散化,步骤如下:
- 给定特征集 \(x_1, x_2, x_3, …\) 和对应的标签集 \(f(x_1), f(x_2), f(x_3), …\),将每个数据点视为一个聚类。
- 对于新数据点 \(x^*\),找到距离最近的邻居 \(x_i\)(使 \(|x^* – x_i|\) 最小)。
- 用 \(f(x_i)\) 估计 \(f(x^*)\)。
- 解释为什么 KNN 算法被称为 “惰性学习器(lazy learner)”?它与线性回归这类模型的训练过程有何不同?
KNN 算法被称为 “惰性学习器”,是因为它没有显式的参数估计阶段:算法会存储全部训练集数据,将计算过程推迟到预测阶段。对于一个新的输入样本x,KNN 算法会计算该样本与所有训练样本xi之间的距离d(x,xi),然后对距离最近的 K 个样本的标签(或数值)进行聚合,从而得到预测结果。
与之相反,线性回归模型需要通过最小化损失函数(如最小二乘法)来估计参数β,其损失函数表达式为:
minβ∑i=1n(yi−xi⊤β)2
随后,线性回归模型会利用拟合得到的模型y^(x)=x⊤β^进行快速预测。因此,KNN 算法的计算集中在推理(预测)阶段,而线性回归模型的计算则集中在训练阶段。
二分类器(补充)
上文所述的分类任务,本质是根据某一观测数据的特征,判断该观测所属的类别。
在上述案例中,我们尝试利用企鹅的生理特征数据对其物种进行分类。
有一种特殊且重要的分类器,仅需判断 “是” 或 “否”、“真” 或 “假”、“有罪” 或 “无罪”、“患病” 或 “健康” 等,即仅存在两个类别,通常称为 “正类” 和 “负类”。
这类分类器被称为二分类器,其对应的混淆矩阵值得进一步探讨。
接下来,我们仍以企鹅数据集为例,尝试通过其他生理特征预测企鹅的性别。这将构成一个二分类任务:预测结果要么是 “雌性(正类)”,要么是 “非雌性(负类)”。


相关公式与评价指标
有了 TP、FP、FN、TN 这些基础数据后,我们可以计算多种模型性能评价指标。以下是最常用的指标,其中P代表测试集中正类的总数量,N代表测试集中负类的总数量。


决策边界
想象一个二分类场景:特征数据点位于二维空间中。
我们可以用不同颜色标记二分类的输出结果,例如:
- 红色:正类(即雌性企鹅);
- 蓝色:负类(即雄性企鹅)。
从之前的散点图中,我们已能看到类似的颜色区分。从该图中,我们可以想象绘制一条线来分隔红色(正类)和蓝色(负类)区域,这条线就称为决策边界。决策边界的一侧判定为正类,另一侧判定为负类。我们不会手动绘制这条线,而是通过代码可视化决策边界。
绘制决策边界需要更多步骤,核心思路是:先确定测试集特征的取值范围并创建规则网格,然后预测网格中每个点的类别并按类别着色。此处对应原文中的决策边界与真实标签叠加图,蓝色和红色区域为决策边界划分的预测类别区域,空心蓝色圆和空心红色圆代表标准化后的真实标签样本,可清晰观察到样本与决策边界的位置关系及预测正确 / 错误的情况
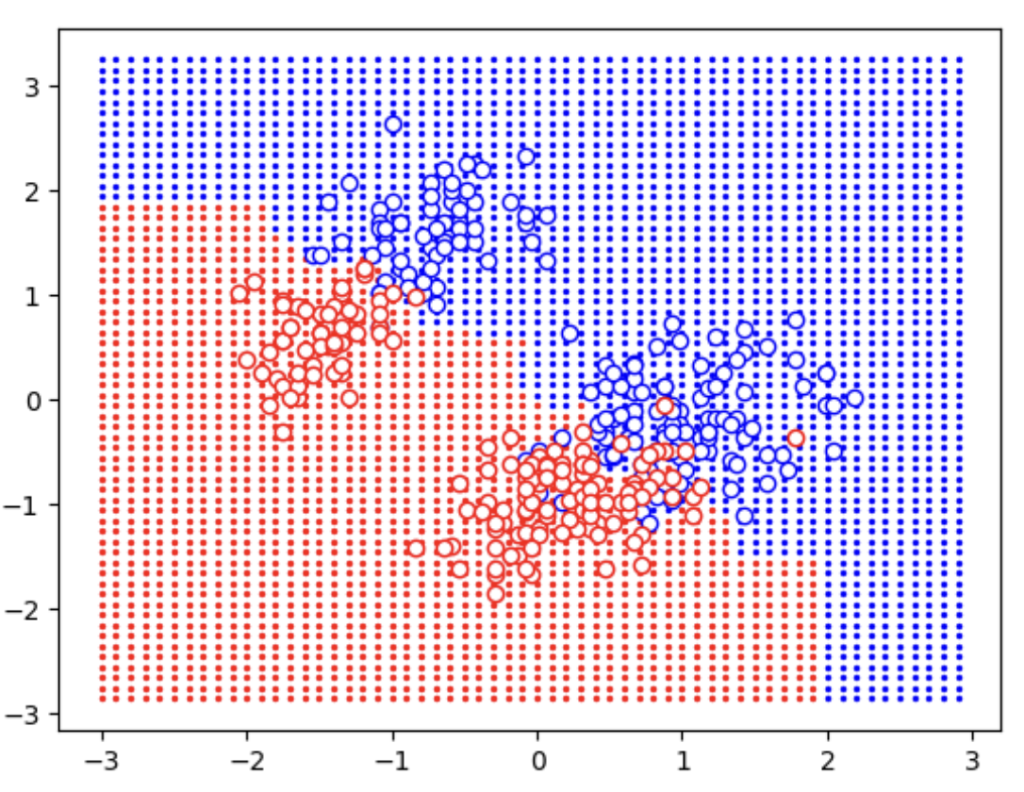
# 1. 绘制决策边界网格:按预测类别着色
indxF_grid = np.where(y_pred_grid == 'Female')[0]
indxM_grid = np.where(y_pred_grid != 'Female')[0]
plt.scatter(xx1xx2[indxM_grid, 0], xx1xx2[indxM_grid, 1], color='blue', s=2)
plt.scatter(xx1xx2[indxF_grid, 0], xx1xx2[indxF_grid, 1], color='red', s=2)
# 2. 对整个数据集的特征进行标准化(使用训练集的scaler参数)
X_trans = scaler.transform(X)
# 3. 找到真实标签为雄性和雌性的样本索引
indxM_true = np.where(y == 'Male')[0]
indxF_true = np.where(y != 'Male')[0]
# 4. 绘制标准化后的真实标签样本,用空心圆表示(避免覆盖网格点),边缘颜色分别为蓝色(雄性)和红色(雌性)
plt.scatter(X_trans[indxM_true, 0], X_trans[indxM_true, 1], facecolors='w', edgecolors='b')
plt.scatter(X_trans[indxF_true, 0], X_trans[indxF_true, 1], facecolors='w', edgecolors='r')