信访的精确定义:公民、法人或者其他组织采用书信、电话、网络、走访等形式,向各级人民政府、县级以上人民政府工作部门反映情况,提出建议、意见或者投诉请求,依法由有关行政机关处理的活动
1. 基础术语
- 语料库:大量标注 / 未标注的文本数据集合,是 NLP 模型训练的基础(如中文的人民日报语料、英文的 Wiki 语料);
- 标注数据:带有标签的文本数据(如情感分析中 “这部电影好看” 标注为 “正面”),用于监督学习;
- 未标注数据:无标签的原始文本,用于无监督 / 半监督学习;
- 词汇表(Vocab):从语料中提取的所有唯一词的集合,是将词转化为数字的基础;
- OOV(Out of Vocabulary):未登录词,指文本中出现的词汇表中没有的词,是 NLP 的常见问题;
- 语义表示:将词 / 句子转化为计算机可处理的数字形式(如向量),是 NLP 的核心环节(即 “词嵌入 / 句嵌入”)
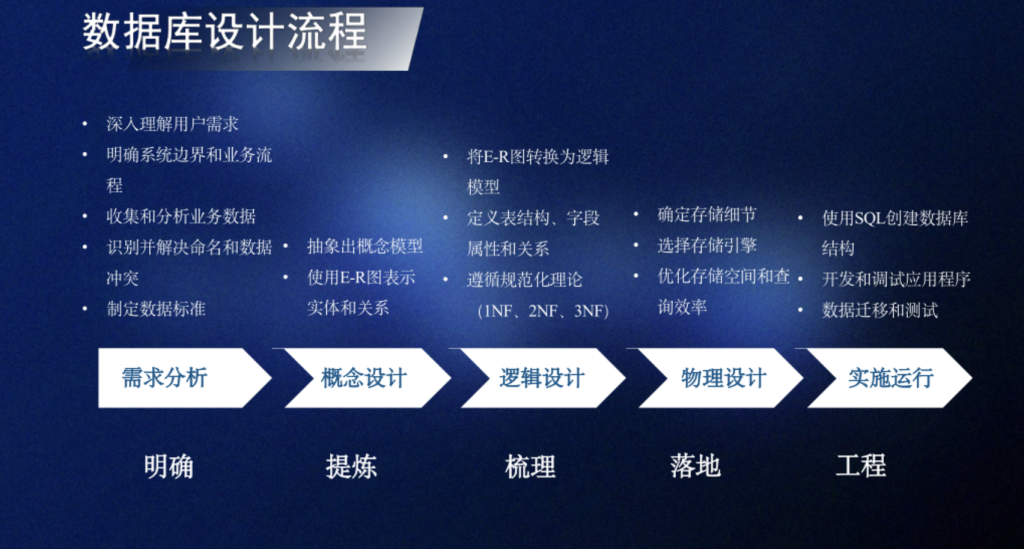
2. 处理流程
原始文本 → 文本预处理 → 特征表示 → 模型训练 → 模型推理 / 部署
2.1 原始文本获取
收集任务相关的语料数据(如爬取网页、公开数据集、人工标注),需保证数据的有效性和相关性。
2.2 文本预处理
- 文本清洗:去除乱码、特殊符号(@、#、¥)、冗余空格、换行符,统一大小写(英文);
- 分词(中文专属):使用分词工具将句子拆分为词(如 jieba 分词);
- 停用词去除:加载停用词表,移除文本中的无意义词;
- 标准化:繁简转换、错别字修正、词干提取 / 词形还原(英文,如 “running”→“run”);
- 过滤低频次:移除语料中出现次数极少的词(减少噪声,避免 OOV)
2.3 特征表示(Bert模型的输出结果)
计算机无法直接处理文本,必须将词 / 句子转化为向量,该过程称为 “特征表示”
- 词嵌入Word Embedding
- 向量的距离代表语义相似度
- Word2Vec:经典的无监督词嵌入模型,分为 CBOW(用上下文预测中心词)和 Skip-gram(用中心词预测上下文),可从海量未标注语料中学习词的语义向量;
- GloVe:结合 TF-IDF 的统计信息和 Word2Vec 的神经网络,学习的词向量语义更精准;
- 句嵌入
- 将整个句子转化为一个向量,代表方法有Doc2Vec、Sentence-BERT(SBERT),适用于文本匹配、相似度计算等任务。
2.4 模型训练
将特征表示后的数字向量送入NLP 模型,根据任务类型(分类、生成、匹配等)选择对应的模型,分为传统机器学习模型和深度学习模型:
传统机器学习模型:代表模型:
- 逻辑回归(LR)
- 支持向量机(SVM)
- 朴素贝叶斯(NB)
适用于简单任务(如文本分类),基于TF-IDF 特征
- TF-IDF 的核心思想:一个词在当前文档里很常见,但在其他文档里不常见,那它就更重要。
- TF(Term Frequency,词频):表示某个词在一篇文档里出现得有多频繁。一个词在当前文本里出现越多,TF 通常越高
- IDF(Inverse Document Frequency,逆文档频率):表示某个词在整个语料库里是不是“太常见”
- 如果一个词在几乎所有文档里都出现,比如“的”“是”“一个”,那它区分文本的能力就弱,IDF 会低
- 如果一个词只在少数文档中出现,比如“卷积神经网络”,它更有辨识度,IDF 会高
深度学习模型:当前 NLP 的主流,适用于所有任务,尤其是复杂的生成、翻译任务,代表模型:
- 基础深度模型:CNN(卷积神经网络,擅长提取局部特征,如文本分类)、RNN/LSTM/GRU(循环神经网络,擅长处理序列数据,解决 CNN 的词序忽略问题)
- 主流模型:Transformer
- 由编码器(Encoder) 和解码器(Decoder) 组成,编码器负责 “理解文本”(双向注意力),解码器负责 “生成文本”(单向注意力);
- 预训练大模型:BERT,(双向理解,适用于理解类任务:分类、NER、QA)
- 仅用编码器:适用于理解类任务(文本分类、NER、QA、相似度计算),代表模型:BERT;
- 仅用解码器:适用于生成类任务(文本生成、聊天机器人),代表模型:GPT;
- 编码器 + 解码器:适用于序列到序列(Seq2Seq)任务(机器翻译、摘要生成)
2.5 模型推理与部署
将训练好的模型应用于新的未标注文本,完成预测(如对新的评论做情感分析),并根据实际需求将模型部署到线上(如智能客服、APP 接口)
3. 模型
信息提取功能的核心基础模型为BERT(Bidirectional Encoder Representations from Transformers)
3.1 架构
信息提取功能采用“数据层—模型层—功能层—输出层”的四层技术架构
3.1.1 数据层
完成信访文本数据的采集、清洗、脱敏、标注
- 数据处理:去重、关键词匹配、人工筛选,剔除无实质诉求、格式残缺的无效文本,统一文本编码为 UTF-8、字段命名规则,完成数据标准化预处理;
- 数据脱敏:对投诉人姓名、联系方式、身份证号等敏感信息进行字符替换、部分隐藏处理,避免隐私泄露;
数据标注数据集:按照制定的标注规范,完成实体类型(时间、地点、涉事主体)、分类标签(投诉类型、情绪等级)、诉求/举措的人工标注,形成标注数据集
3.1.2 模型层
以BERT基础预训练模型为核心,完成模型部署、微调、优化,为功能层提供模型推理能力,具体包括:
- 基础模型部署:基于 Hugging Face Transformers 库调用BERT-base-large中文预训练模型,适配中文信访文本的行文风格与语义特征,模型输入为经数据层处理后的序列化文本,设置最大序列长度为512,适配信访文本的常规长度;
- 模型微调:采用领域适配增量预训练策略,先使用未标注的信访原始文本进行继续预训练,让模型学习信访领域专业术语、句式特征,再使用标注数据集进行微调,采用小批量梯度下降法(Batch Size=32),减少过拟合风险的同时减小计算资源需求;
- 模型轻量化优化:针对不同功能模块添加专属优化层,
- 命名实体识别模块添加 CRF 层提升序列标注精度
- CRF 条件随机场,是一种概率图模型。在命名实体识别任务中,CRF 层能够学习标签之间的转移规律,约束预测标签的合法性,避免出现不合理的标注结果,从而提升实体识别的整体准确率。
- 分类模块采用学习率动态调整策略,提升模型推理精度与效率。
- 学习率是训练神经网络时最重要的超参数之一
- 在训练中自动改变学习率大小的优化策略,能让模型更快收敛、更稳定学习,从而提高分类精度和训练效率,例如设置:初始学习率=2e-5,每2个epoch 衰减 10%
- 命名实体识别模块添加 CRF 层提升序列标注精度
3.1.2 功能层
基于微调后的BERT模型实现三大核心功能,各功能模块独立开发,预留统一接口:
- 命名实体识别模块:识别信访文本中的时间、地点、涉事主体(部门/个人/企业)三类核心实体
- 多维度分类模块:实现投诉类型(49个一级分类)、情绪等级(无情绪/轻微不满/强烈不满/愤怒)
- 诉求与举措抽取模块:识别信访人的核心诉求、责任单位已采取/拟采取的处理措施,建立诉求与举措的语义关联
3.1.3 输出层
完成结构化数据的统一输出,将三大功能模块的推理结果整合为标准化JSON结构化字典(同时保存为
excel表格,便于人工审核),输出格式统一、字段规范,方便直接对接后续系统模块,核心输出字段包括:实体信息(时间、地点、涉事主体)、分类结果(投诉类型、情绪等级)、诉求与举措(核心诉求、处理措施),同时保留原始文本索引,便于人工复核与溯源。
JSON 是一种轻量级的数据交换格式,一种用文本来表示结构化数据的标准写法,很适合在系统之间传递数据。对象用 {} 表示,里面是 键值对,数组用 [] 表示,里面可以放多个值:
{
"name": "张三",
"age": 28
}
{
"hobbies": ["阅读", "跑步", "旅游"]
}3.2 功能层实现方案
3.2.1 命名实体识别(时间、地点、涉事主体)
- 技术路线:BERT+CRF(在政务文本命名实体识别任务中已验证其优越性,可有效解决传统模型语义表示不足、长距离依赖处理能力弱等问题)
- 实现流程
- 输入:经清洗脱敏后的信访文本原始句子,进行分词、序列化处理后输入模型;
- BERT层:将句子转化为词向量,捕捉上下文语义特征,输出每个字的特征向量;
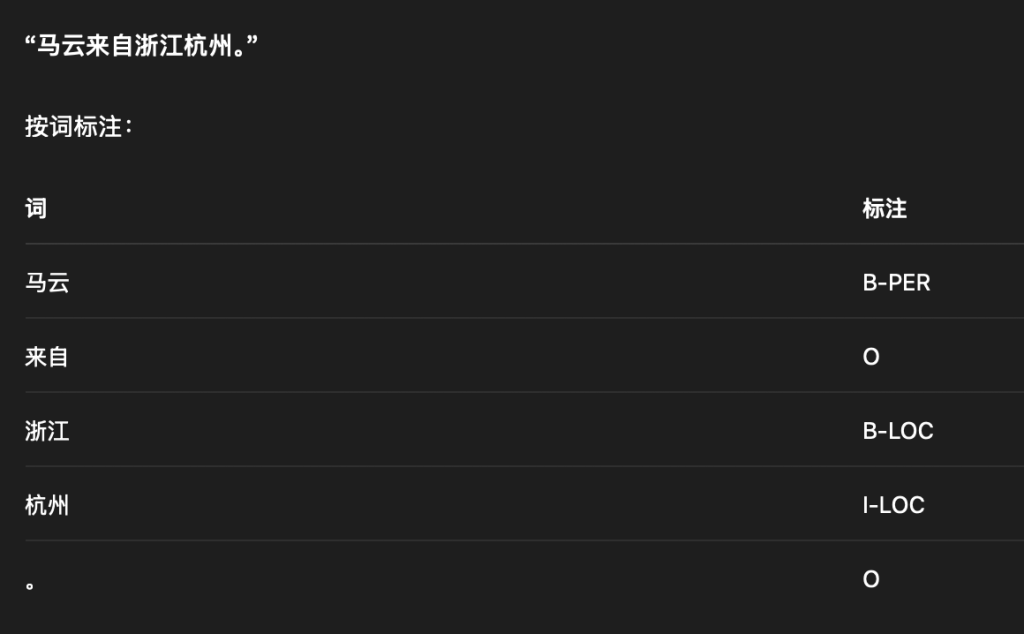
- CRF层:对BERT层输出的特征向量进行序列标注,定义实体标注规则(采用BIO 标注法:B-实体开始、I-实体中间、O-非实体),CRF层通过学习标注序列的转移概率,优化标注序列的合理性,解决实体边界模糊、重叠标注问题;
- 避免出现“B-时间+ I-地点” 等不合理标注
- 输出:识别出的时间、地点、涉事主体实体及对应位置
- 如{“时间”:”2026年2月8日”,”地点”:”XX区XX街道”,”涉事主体”:”XX物业公司”}
后续迭代中可引入BERT-BiLSTM-CRF架构,进一步捕捉文本的上下文序列特征,提升长文本中实体识别的准确率,同时添加注意力机制,对信访文本中核心实体相关词汇赋予更高权重
3.2.2 多维度文本分类(投诉类型、情绪等级)
- 技术路线:BERT+全连接层+激活函数(Softmax)初步实现分类功能
- 实现流程
- 输入:经清洗脱敏后的信访文本整段内容;
- BERT层:对文本进行编码,提取文本整体语义特征,输出向量作为文本的核心特征表示;
- 全连接层:设置两层全连接层,第一层将1024维特征向量映射为256 维,第二层将256维向量分别映射到多维度分类标签空间,分别对应投诉类型(一级分类49类)、情绪等级(4类),后续可根据业务需求扩展标签类别;
- 激活函数:通过Softmax实现多标签概率计算,选取概率最大值为最终分类结果,损失函数采用交叉熵损失,适配分类任务的损失计算需求
- 输出:多维度分类结果
- 如{“投诉类型”:”民生服务-物业管理”,”情绪等级”:”强烈不满”,”紧急程度”:”一般”}
3.2.3 诉求与举措抽取(诉求、举措、诉求与举措的关系)
- 技术路线:BERT+序列标注+关系抽取
- 实现流程
- 序列标注阶段:采用BERT模型对信访文本进行序列标注,采用BIOE 标注法,比基础BIO标注更精准区分实体边界(在BIO基础上增加E-xxx(实体结束),识别出疑似诉求、疑似举措的文本片段,标注规则适配信访文本表述特征;
- 如“要求/希望/诉求”后为诉求片段,“已处理/将整改/采取措施”后为举措片段
- 关系抽取阶段:对标注出的片段进行语义关联分析,判断片段间是否为“诉求-对应举措”关系,剔除无关片段;
- 输出:结构化的诉求与举措信息
- {“核心诉求”:”要求物业公司修复小区破损电梯”,”处理措施”:”物业公司已安排工作人员现场排查,将于3个工作日内完成修复”}
- 序列标注阶段:采用BERT模型对信访文本进行序列标注,采用BIOE 标注法,比基础BIO标注更精准区分实体边界(在BIO基础上增加E-xxx(实体结束),识别出疑似诉求、疑似举措的文本片段,标注规则适配信访文本表述特征;
下一步安排:
- 基于Python+PyTorch+Transformers部署BERT-base中文预训练模型,搭建基础模型训练框架;
- 标注数据集(不少于500条),并使用标注后的信访数据集,分别训练命名实体识别(BERT+CRF)、基础文本分类模型,实现核心功能的初步落地
- 对模型进行初步测试,结合测试结果制定模型优化方向。
4. 实践记录
4.1 命名实体识别模型
5. 个人实践任务
标注数据集的中间某些部分
本来尝试用开源的进行标注,顺便看看其他人的方案如何,如果效果不错可以参考其方案
后来选择手动标注
我之前没有梳理清楚每个部分的职责,我现在搞清楚了,给你整理了思路,我只做这个的分类,要识别投诉类型(49个一级分类)、情绪等级(无情绪/轻微不满/强烈不满/愤怒),最终输出三大功能模块的推理结果整合为标准化JSON结构化字典(同时保存为excel表格,便于人工审核),在反馈前10000.xlsx那里面有每个信访的原内容和对应的一级分类,但是里面只有是和否的满意数据,没有4个等级,同时在问题分类2501.xlsx里有所有一级分类的列表
这是目前我的需求和所有的数据集,现在我要求你按照图片里所说的思路去实现,但是如果图片里没有涉及的需求的解决方案,你需要给我提出,并告诉我怎么做,新建一个conda环境,下载你所需要用的包,给我详细的实现步骤
1.新建环境
conda create -n xinfang-cls python=3.10 -y
conda activate xinfang-cls
进入项目目录 cd ~/Desktop/xinfang-nlp
2.安装必要包
pip install -U pip
pip install torch transformers pandas openpyxl scikit-learn tqdm
- 生成数据脚本:01_make_cls_data.py,这一步的数据表格是这些,需改你的表列名。还有你的情绪等级能不能调用其他人的模型,你是不是识别原内容有没有属于你定的各个情绪等级里的词来决定是哪个等级?有更好的方式吗,我想的是,调用其他github开源的模型去做情绪等级分类这一部分,其他的还是按照原来的方案,重新给我从这一步之后的所有步骤
3.生成训练数据(列名已对齐你的表),也就是转换为json,01_make_cls_data.py
4.用开源情感模型把 emotion_id 自动补齐(替代“关键词词表”)01b_add_emotion_by_sent_model.py
5.训练双头分类模型(投诉类型49类 + 情绪4类),预留10%作为测试集
6.“一键测试”这 3 条并输出标准化 JSON(不改你全量推理脚本)03b_infer_cls_demo3.py:
7.改进,因为感情预测不准。调整外部情感模型的 NEG 分数映射
8.改进输出格式,不是你得保存成文件啊JSONL(推荐,适合系统)+ Excel(审核),但同时也在控制台显示03b_infer_demo3_save.py(只跑3条样本)
9.准确率,只有70%。
重合那么点不用改了,现在的问题是你的准确率是不是有点低,我要是没理解错只有76%对吧,我想知道你训练模型时的全流程,看看和我们说的一不一样
10.优化模型 你的这个改进是我们文档里提到的吗,原理是什么,还有你能想到其他能让正确率等指标更好的其他改进方法吗?可以参考一些已有的项目的优化方式